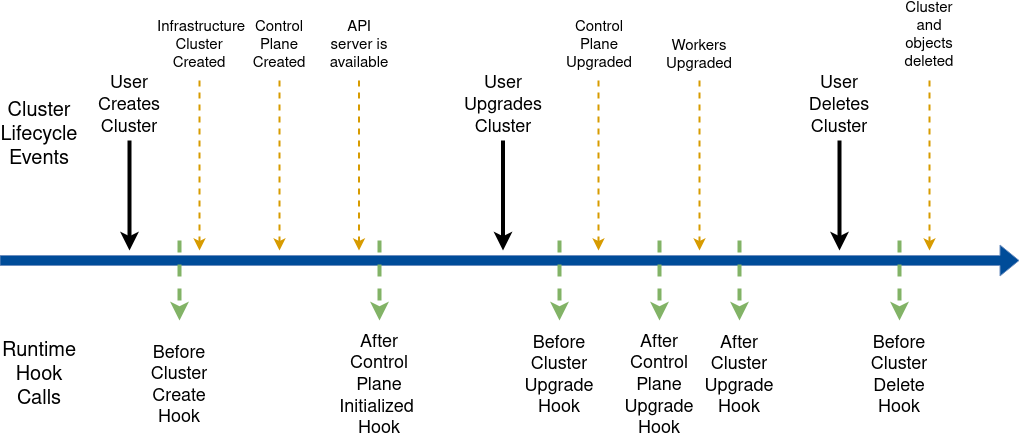
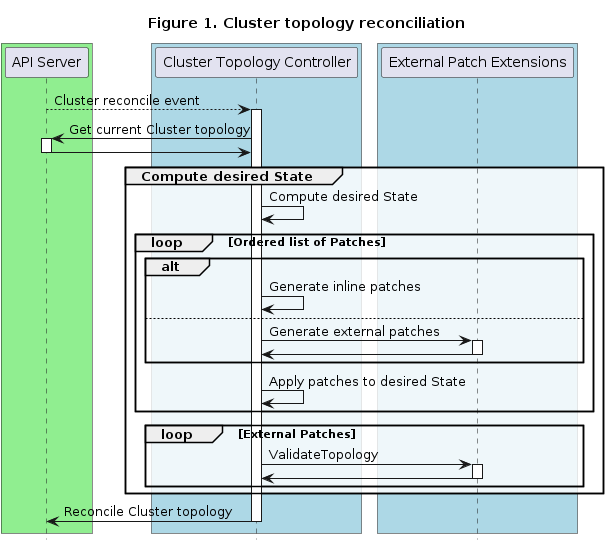
Cluster API is a Kubernetes sub-project focused on providing declarative APIs and tooling to simplify provisioning, upgrading, and operating multiple Kubernetes clusters.
Started by the Kubernetes Special Interest Group (SIG) Cluster Lifecycle , the Cluster API project uses Kubernetes-style APIs and patterns to automate cluster lifecycle management for platform operators. The supporting infrastructure, like virtual machines, networks, load balancers, and VPCs, as well as the Kubernetes cluster configuration are all defined in the same way that application developers operate deploying and managing their workloads. This enables consistent and repeatable cluster deployments across a wide variety of infrastructure environments.
k8s.gcr.io image registry will be redirected to registry.k8s.io on Monday March 20th.
All images available in k8s.gcr.io are available at registry.k8s.io.
Please read the announcement for more details.
Also, this guide provide instructions about how to identify images to mirror and how to use mirrored images.
This book documents ClusterAPI v1.7. For other Cluster API versions please see the corresponding documentation:
Kubernetes is a complex system that relies on several components being configured correctly to have a working cluster. Recognizing this as a potential stumbling block for users, the community focused on simplifying the bootstrapping process. Today, over 100 Kubernetes distributions and installers have been created, each with different default configurations for clusters and supported infrastructure providers. SIG Cluster Lifecycle saw a need for a single tool to address a set of common overlapping installation concerns and started kubeadm.
Kubeadm was designed as a focused tool for bootstrapping a best-practices Kubernetes cluster. The core tenet behind the kubeadm project was to create a tool that other installers can leverage and ultimately alleviate the amount of configuration that an individual installer needed to maintain. Since it began, kubeadm has become the underlying bootstrapping tool for several other applications, including Kubespray, minikube, kind, etc.
However, while kubeadm and other bootstrap providers reduce installation complexity, they don’t address how to manage a cluster day-to-day or a Kubernetes environment long term. You are still faced with several questions when setting up a production environment, including:
How can I consistently provision machines, load balancers, VPC, etc., across multiple infrastructure providers and locations?
How can I automate cluster lifecycle management, including things like upgrades and cluster deletion?
How can I scale these processes to manage any number of clusters?
SIG Cluster Lifecycle began the Cluster API project as a way to address these gaps by building declarative, Kubernetes-style APIs, that automate cluster creation, configuration, and management. Using this model, Cluster API can also be extended to support any infrastructure provider (AWS, Azure, vSphere, etc.) or bootstrap provider (kubeadm is default) you need. See the growing list of available providers .
To manage the lifecycle (create, scale, upgrade, destroy) of Kubernetes-conformant clusters using a declarative API.
To work in different environments, both on-premises and in the cloud.
To define common operations, provide a default implementation, and provide the ability to swap out implementations for alternative ones.
To reuse and integrate existing ecosystem components rather than duplicating their functionality (e.g. node-problem-detector, cluster autoscaler, SIG-Multi-cluster).
To provide a transition path for Kubernetes lifecycle products to adopt Cluster API incrementally. Specifically, existing cluster lifecycle management tools should be able to adopt Cluster API in a staged manner, over the course of multiple releases, or even adopting a subset of Cluster API.
To add these APIs to Kubernetes core (kubernetes/kubernetes).
This API should live in a namespace outside the core and follow the best practices defined by api-reviewers, but is not subject to core-api constraints.
To manage the lifecycle of infrastructure unrelated to the running of Kubernetes-conformant clusters.
To force all Kubernetes lifecycle products (kOps, Kubespray, GKE, AKS, EKS, IKS etc.) to support or use these APIs.
To manage non-Cluster API provisioned Kubernetes-conformant clusters.
To manage a single cluster spanning multiple infrastructure providers.
To configure a machine at any time other than create or upgrade.
To duplicate functionality that exists or is coming to other tooling, e.g., updating kubelet configuration (c.f. dynamic kubelet configuration), or updating apiserver, controller-manager, scheduler configuration (c.f. component-config effort) after the cluster is deployed.
Cluster API is developed in the open, and is constantly being improved by our users, contributors, and maintainers. It is because of you that we are able to automate cluster lifecycle management for the community. Join us!
If you have questions or want to get the latest project news, you can connect with us in the following ways:
Chat with us on the Kubernetes Slack in the #cluster-api channel
Subscribe to the SIG Cluster Lifecycle Google Group for access to documents and calendars
Join our Cluster API working group sessions where we share the latest project news, demos, answer questions, and triage issues
Pull Requests and feedback on issues are very welcome!
See the issue tracker if you’re unsure where to start, especially the Good first issue and Help wanted tags, and
also feel free to reach out to discuss.
See also our contributor guide and the Kubernetes community page for more details on how to get involved.
Participation in the Kubernetes community is governed by the Kubernetes Code of Conduct .
In this tutorial we’ll cover the basics of how to use Cluster API to create one or more Kubernetes clusters.
There are two major quickstart paths: Using clusterctl or the Cluster API Operator.
This article describes a path that uses the clusterctl CLI tool to handle the lifecycle of a Cluster API management cluster .
The clusterctl command line interface is specifically designed for providing a simple “day 1 experience” and a quick start with Cluster API. It automates fetching the YAML files defining provider components and installing them.
Additionally it encodes a set of best practices in managing providers, that helps the user in avoiding mis-configurations or in managing day 2 operations such as upgrades.
The Cluster API Operator is a Kubernetes Operator built on top of clusterctl and designed to empower cluster administrators to handle the lifecycle of Cluster API providers within a management cluster using a declarative approach. It aims to improve user experience in deploying and managing Cluster API, making it easier to handle day-to-day tasks and automate workflows with GitOps. Visit the CAPI Operator quickstart if you want to experiment with this tool.
Cluster API requires an existing Kubernetes cluster accessible via kubectl. During the installation process the
Kubernetes cluster will be transformed into a management cluster by installing the Cluster API provider components , so it
is recommended to keep it separated from any application workload.
It is a common practice to create a temporary, local bootstrap cluster which is then used to provision
a target management cluster on the selected infrastructure provider .
Choose one of the options below:
Existing Management Cluster
For production use-cases a “real” Kubernetes cluster should be used with appropriate backup and disaster recovery policies and procedures in place. The Kubernetes cluster must be at least v1.20.0.
export KUBECONFIG=<...>
OR
Kind
kind can be used for creating a local Kubernetes cluster for development environments or for
the creation of a temporary bootstrap cluster used to provision a target management cluster on the selected infrastructure provider.
The installation procedure depends on the version of kind; if you are planning to use the Docker infrastructure provider,
please follow the additional instructions in the dedicated tab:
Default Docker KubeVirt
Create the kind cluster:
kind create cluster
Test to ensure the local kind cluster is ready:
kubectl cluster-info
Run the following command to create a kind config file for allowing the Docker provider to access Docker on the host:
cat > kind-cluster-with-extramounts.yaml <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
ipFamily: dual
nodes:
- role: control-plane
extraMounts:
- hostPath: /var/run/docker.sock
containerPath: /var/run/docker.sock
EOF
Then follow the instruction for your kind version using kind create cluster --config kind-cluster-with-extramounts.yaml
to create the management cluster using the above file.
KubeVirt is a cloud native virtualization solution. The virtual machines we’re going to create and use for
the workload cluster’s nodes, are actually running within pods in the management cluster. In order to communicate with
the workload cluster’s API server, we’ll need to expose it. We are using Kind which is a limited environment. The
easiest way to expose the workload cluster’s API server (a pod within a node running in a VM that is itself running
within a pod in the management cluster, that is running inside a Docker container), is to use a LoadBalancer service.
To allow using a LoadBalancer service, we can’t use the kind’s default CNI (kindnet), but we’ll need to install
another CNI, like Calico. In order to do that, we’ll need first to initiate the kind cluster with two modifications:
Disable the default CNI
Add the Docker credentials to the cluster, to avoid the Docker Hub pull rate limit of the calico images; read more
about it in the docker documentation , and in the
kind documentation .
Create a configuration file for kind. Please notice the Docker config file path, and adjust it to your local setting:
cat <<EOF > kind-config.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
# the default CNI will not be installed
disableDefaultCNI: true
nodes:
- role: control-plane
extraMounts:
- containerPath: /var/lib/kubelet/config.json
hostPath: <YOUR DOCKER CONFIG FILE PATH>
EOF
Now, create the kind cluster with the configuration file:
kind create cluster --config=kind-config.yaml
Test to ensure the local kind cluster is ready:
kubectl cluster-info
Now we’ll need to install a CNI. In this example, we’re using calico, but other CNIs should work as well. Please see
calico installation guide
for more details (use the “Manifest” tab). Below is an example of how to install calico version v3.24.4.
Use the Calico manifest to create the required resources; e.g.:
kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.24.4/manifests/calico.yaml
The clusterctl CLI tool handles the lifecycle of a Cluster API management cluster.
Linux macOS homebrew Windows
If you are unsure you can determine your computers architecture by running uname -a
Download for AMD64:
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v1.7.9/clusterctl-linux-amd64 -o clusterctl
Download for ARM64:
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v1.7.9/clusterctl-linux-arm64 -o clusterctl
Download for PPC64LE:
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v1.7.9/clusterctl-linux-ppc64le -o clusterctl
Install clusterctl:
sudo install -o root -g root -m 0755 clusterctl /usr/local/bin/clusterctl
Test to ensure the version you installed is up-to-date:
clusterctl version
If you are unsure you can determine your computers architecture by running uname -a
Download for AMD64:
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v1.7.9/clusterctl-darwin-amd64 -o clusterctl
Download for M1 CPU (”Apple Silicon”) / ARM64:
curl -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v1.7.9/clusterctl-darwin-arm64 -o clusterctl
Make the clusterctl binary executable.
chmod +x ./clusterctl
Move the binary in to your PATH.
sudo mv ./clusterctl /usr/local/bin/clusterctl
Test to ensure the version you installed is up-to-date:
clusterctl version
Install the latest release using homebrew:
brew install clusterctl
Test to ensure the version you installed is up-to-date:
clusterctl version
Go to the working directory where you want clusterctl downloaded.
Download the latest release; on Windows, type:
curl.exe -L https://github.com/kubernetes-sigs/cluster-api/releases/download/v1.7.9/clusterctl-windows-amd64.exe -o clusterctl.exe
Append or prepend the path of that directory to the PATH environment variable.
Test to ensure the version you installed is up-to-date:
clusterctl.exe version
Now that we’ve got clusterctl installed and all the prerequisites in place, let’s transform the Kubernetes cluster
into a management cluster by using clusterctl init.
The command accepts as input a list of providers to install; when executed for the first time, clusterctl init
automatically adds to the list the cluster-api core provider, and if unspecified, it also adds the kubeadm bootstrap
and kubeadm control-plane providers.
Feature gates can be enabled by exporting environment variables before executing clusterctl init.
For example, the ClusterTopology feature, which is required to enable support for managed topologies and ClusterClass,
can be enabled via:
export CLUSTER_TOPOLOGY=true
Additional documentation about experimental features can be found in Experimental Features .
Depending on the infrastructure provider you are planning to use, some additional prerequisites should be satisfied
before getting started with Cluster API. See below for the expected settings for common providers.
Akamai (Linode) AWS Azure CloudStack DigitalOcean Docker Equinix Metal GCP Hetzner Hivelocity IBM Cloud IONOS Cloud K0smotron KubeKey KubeVirt Metal3 Nutanix OCI OpenStack Outscale Proxmox VCD vcluster Virtink vSphere
export LINODE_TOKEN=<your-access-token>
# Initialize the management cluster
clusterctl init --infrastructure linode-linode
Download the latest binary of clusterawsadm from the AWS provider releases . The clusterawsadm command line utility assists with identity and access management (IAM) for Cluster API Provider AWS .
Linux macOS homebrew Windows
Download the latest release; on Linux, type:
curl -L https://github.com/kubernetes-sigs/cluster-api-provider-aws/releases/download/v2.7.1/clusterawsadm-linux-amd64 -o clusterawsadm
Make it executable
chmod +x clusterawsadm
Move the binary to a directory present in your PATH
sudo mv clusterawsadm /usr/local/bin
Check version to confirm installation
clusterawsadm version
Example Usage
export AWS_REGION=us-east-1 # This is used to help encode your environment variables
export AWS_ACCESS_KEY_ID=<your-access-key>
export AWS_SECRET_ACCESS_KEY=<your-secret-access-key>
export AWS_SESSION_TOKEN=<session-token> # If you are using Multi-Factor Auth.
# The clusterawsadm utility takes the credentials that you set as environment
# variables and uses them to create a CloudFormation stack in your AWS account
# with the correct IAM resources.
clusterawsadm bootstrap iam create-cloudformation-stack
# Create the base64 encoded credentials using clusterawsadm.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Finally, initialize the management cluster
clusterctl init --infrastructure aws
Download the latest release; on macOs, type:
curl -L https://github.com/kubernetes-sigs/cluster-api-provider-aws/releases/download/v2.7.1/clusterawsadm-darwin-amd64 -o clusterawsadm
Or if your Mac has an M1 CPU (”Apple Silicon”):
curl -L https://github.com/kubernetes-sigs/cluster-api-provider-aws/releases/download/v2.7.1/clusterawsadm-darwin-arm64 -o clusterawsadm
Make it executable
chmod +x clusterawsadm
Move the binary to a directory present in your PATH
sudo mv clusterawsadm /usr/local/bin
Check version to confirm installation
clusterawsadm version
Example Usage
export AWS_REGION=us-east-1 # This is used to help encode your environment variables
export AWS_ACCESS_KEY_ID=<your-access-key>
export AWS_SECRET_ACCESS_KEY=<your-secret-access-key>
export AWS_SESSION_TOKEN=<session-token> # If you are using Multi-Factor Auth.
# The clusterawsadm utility takes the credentials that you set as environment
# variables and uses them to create a CloudFormation stack in your AWS account
# with the correct IAM resources.
clusterawsadm bootstrap iam create-cloudformation-stack
# Create the base64 encoded credentials using clusterawsadm.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Finally, initialize the management cluster
clusterctl init --infrastructure aws
Install the latest release using homebrew:
brew install clusterawsadm
Check version to confirm installation
clusterawsadm version
Example Usage
export AWS_REGION=us-east-1 # This is used to help encode your environment variables
export AWS_ACCESS_KEY_ID=<your-access-key>
export AWS_SECRET_ACCESS_KEY=<your-secret-access-key>
export AWS_SESSION_TOKEN=<session-token> # If you are using Multi-Factor Auth.
# The clusterawsadm utility takes the credentials that you set as environment
# variables and uses them to create a CloudFormation stack in your AWS account
# with the correct IAM resources.
clusterawsadm bootstrap iam create-cloudformation-stack
# Create the base64 encoded credentials using clusterawsadm.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Finally, initialize the management cluster
clusterctl init --infrastructure aws
Download the latest release; on Windows, type:
curl.exe -L https://github.com/kubernetes-sigs/cluster-api-provider-aws/releases/download/v2.7.1/clusterawsadm-windows-amd64.exe -o clusterawsadm.exe
Append or prepend the path of that directory to the PATH environment variable.
Check version to confirm installation
clusterawsadm.exe version
Example Usage in Powershell
$Env:AWS_REGION="us-east-1" # This is used to help encode your environment variables
$Env:AWS_ACCESS_KEY_ID="<your-access-key>"
$Env:AWS_SECRET_ACCESS_KEY="<your-secret-access-key>"
$Env:AWS_SESSION_TOKEN="<session-token>" # If you are using Multi-Factor Auth.
# The clusterawsadm utility takes the credentials that you set as environment
# variables and uses them to create a CloudFormation stack in your AWS account
# with the correct IAM resources.
clusterawsadm bootstrap iam create-cloudformation-stack
# Create the base64 encoded credentials using clusterawsadm.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
$Env:AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Finally, initialize the management cluster
clusterctl init --infrastructure aws
See the AWS provider prerequisites document for more details.
For more information about authorization, AAD, or requirements for Azure, visit the Azure provider prerequisites document.
export AZURE_SUBSCRIPTION_ID="<SubscriptionId>"
# Create an Azure Service Principal and paste the output here
export AZURE_TENANT_ID="<Tenant>"
export AZURE_CLIENT_ID="<AppId>"
export AZURE_CLIENT_ID_USER_ASSIGNED_IDENTITY=$AZURE_CLIENT_ID # for compatibility with CAPZ v1.16 templates
export AZURE_CLIENT_SECRET="<Password>"
# Settings needed for AzureClusterIdentity used by the AzureCluster
export AZURE_CLUSTER_IDENTITY_SECRET_NAME="cluster-identity-secret"
export CLUSTER_IDENTITY_NAME="cluster-identity"
export AZURE_CLUSTER_IDENTITY_SECRET_NAMESPACE="default"
# Create a secret to include the password of the Service Principal identity created in Azure
# This secret will be referenced by the AzureClusterIdentity used by the AzureCluster
kubectl create secret generic "${AZURE_CLUSTER_IDENTITY_SECRET_NAME}" --from-literal=clientSecret="${AZURE_CLIENT_SECRET}" --namespace "${AZURE_CLUSTER_IDENTITY_SECRET_NAMESPACE}"
# Finally, initialize the management cluster
clusterctl init --infrastructure azure
Create a file named cloud-config in the repo’s root directory, substituting in your own environment’s values
[Global]
api-url = <cloudstackApiUrl>
api-key = <cloudstackApiKey>
secret-key = <cloudstackSecretKey>
Create the base64 encoded credentials by catting your credentials file.
This command uses your environment variables and encodes
them in a value to be stored in a Kubernetes Secret.
export CLOUDSTACK_B64ENCODED_SECRET=`cat cloud-config | base64 | tr -d '\n'`
Finally, initialize the management cluster
clusterctl init --infrastructure cloudstack
export DIGITALOCEAN_ACCESS_TOKEN=<your-access-token>
export DO_B64ENCODED_CREDENTIALS="$(echo -n "${DIGITALOCEAN_ACCESS_TOKEN}" | base64 | tr -d '\n')"
# Initialize the management cluster
clusterctl init --infrastructure digitalocean
The Docker provider is not designed for production use and is intended for development environments only.
The Docker provider requires the ClusterTopology and MachinePool features to deploy ClusterClass-based clusters.
We are only supporting ClusterClass-based cluster-templates in this quickstart as ClusterClass makes it possible to
adapt configuration based on Kubernetes version. This is required to install Kubernetes clusters < v1.24 and
for the upgrade from v1.23 to v1.24 as we have to use different cgroupDrivers depending on Kubernetes version.
# Enable the experimental Cluster topology feature.
export CLUSTER_TOPOLOGY=true
# Initialize the management cluster
clusterctl init --infrastructure docker
# Create the base64 encoded credentials by catting your credentials json.
# This command uses your environment variables and encodes
# them in a value to be stored in a Kubernetes Secret.
export GCP_B64ENCODED_CREDENTIALS=$( cat /path/to/gcp-credentials.json | base64 | tr -d '\n' )
# Finally, initialize the management cluster
clusterctl init --infrastructure gcp
In order to initialize the IBM Cloud Provider you have to expose the environment
variable IBMCLOUD_API_KEY. This variable is used to authorize the infrastructure
provider manager against the IBM Cloud API. To create one from the UI, refer here .
export IBMCLOUD_API_KEY=<you_api_key>
# Finally, initialize the management cluster
clusterctl init --infrastructure ibmcloud
The IONOS Cloud credentials are configured in the IONOSCloudCluster.
Therefore, there is no need to specify them during the provider initialization.
clusterctl init --infrastructure ionoscloud-ionoscloud
For more information, please visit the IONOS Cloud project .
# Initialize the management cluster
clusterctl init --infrastructure k0sproject-k0smotron
# Initialize the management cluster
clusterctl init --infrastructure kubekey
Please visit the KubeVirt project for more information.
As described above, we want to use a LoadBalancer service in order to expose the workload cluster’s API server. In the
example below, we will use MetalLB solution to implement load balancing to our kind
cluster. Other solution should work as well.
Install MetalLB, as described here ; for example:
METALLB_VER=$(curl "https://api.github.com/repos/metallb/metallb/releases/latest" | jq -r ".tag_name")
kubectl apply -f "https://raw.githubusercontent.com/metallb/metallb/${METALLB_VER}/config/manifests/metallb-native.yaml"
kubectl wait pods -n metallb-system -l app=metallb,component=controller --for=condition=Ready --timeout=10m
kubectl wait pods -n metallb-system -l app=metallb,component=speaker --for=condition=Ready --timeout=2m
Now, we’ll create the IPAddressPool and the L2Advertisement custom resources. The script below creates the CRs with
the right addresses, that match to the kind cluster addresses:
GW_IP=$(docker network inspect -f '{{range .IPAM.Config}}{{.Gateway}}{{end}}' kind)
NET_IP=$(echo ${GW_IP} | sed -E 's|^([0-9]+\.[0-9]+)\..*$|\1|g')
cat <<EOF | sed -E "s|172.19|${NET_IP}|g" | kubectl apply -f -
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: capi-ip-pool
namespace: metallb-system
spec:
addresses:
- 172.19.255.200-172.19.255.250
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: empty
namespace: metallb-system
EOF
# get KubeVirt version
KV_VER=$(curl "https://api.github.com/repos/kubevirt/kubevirt/releases/latest" | jq -r ".tag_name")
# deploy required CRDs
kubectl apply -f "https://github.com/kubevirt/kubevirt/releases/download/${KV_VER}/kubevirt-operator.yaml"
# deploy the KubeVirt custom resource
kubectl apply -f "https://github.com/kubevirt/kubevirt/releases/download/${KV_VER}/kubevirt-cr.yaml"
kubectl wait -n kubevirt kv kubevirt --for=condition=Available --timeout=10m
clusterctl init --infrastructure kubevirt
# Initialize the management cluster
clusterctl init --infrastructure openstack
export OSC_SECRET_KEY=<your-secret-key>
export OSC_ACCESS_KEY=<your-access-key>
export OSC_REGION=<you-region>
# Create namespace
kubectl create namespace cluster-api-provider-outscale-system
# Create secret
kubectl create secret generic cluster-api-provider-outscale --from-literal=access_key=${OSC_ACCESS_KEY} --from-literal=secret_key=${OSC_SECRET_KEY} --from-literal=region=${OSC_REGION} -n cluster-api-provider-outscale-system
# Initialize the management cluster
clusterctl init --infrastructure outscale
The Proxmox credentials are optional, when creating a cluster they can be set in the ProxmoxCluster resource,
if you do not set them here.
# The host for the Proxmox cluster
export PROXMOX_URL="https://pve.example:8006"
# The Proxmox token ID to access the remote Proxmox endpoint
export PROXMOX_TOKEN='root@pam!capi'
# The secret associated with the token ID
# You may want to set this in `$XDG_CONFIG_HOME/cluster-api/clusterctl.yaml` so your password is not in
# bash history
export PROXMOX_SECRET="1234-1234-1234-1234"
# Finally, initialize the management cluster
clusterctl init --infrastructure proxmox --ipam in-cluster
For more information about the CAPI provider for Proxmox, see the Proxmox
project .
# Initialize the management cluster
clusterctl init --infrastructure virtink
# The username used to access the remote vSphere endpoint
export VSPHERE_USERNAME="vi-admin@vsphere.local"
# The password used to access the remote vSphere endpoint
# You may want to set this in `$XDG_CONFIG_HOME/cluster-api/clusterctl.yaml` so your password is not in
# bash history
export VSPHERE_PASSWORD="admin!23"
# Finally, initialize the management cluster
clusterctl init --infrastructure vsphere
For more information about prerequisites, credentials management, or permissions for vSphere, see the vSphere
project .
The output of clusterctl init is similar to this:
Fetching providers
Installing cert-manager Version="v1.11.0"
Waiting for cert-manager to be available...
Installing Provider="cluster-api" Version="v1.0.0" TargetNamespace="capi-system"
Installing Provider="bootstrap-kubeadm" Version="v1.0.0" TargetNamespace="capi-kubeadm-bootstrap-system"
Installing Provider="control-plane-kubeadm" Version="v1.0.0" TargetNamespace="capi-kubeadm-control-plane-system"
Installing Provider="infrastructure-docker" Version="v1.0.0" TargetNamespace="capd-system"
Your management cluster has been initialized successfully!
You can now create your first workload cluster by running the following:
clusterctl generate cluster [name] --kubernetes-version [version] | kubectl apply -f -
Throughout this quickstart guide we’ve given instructions on setting parameters using environment variables. For most
environment variables in the rest of the guide, you can also set them in $XDG_CONFIG_HOME/cluster-api/clusterctl.yaml
See clusterctl init
Once the management cluster is ready, you can create your first workload cluster.
The clusterctl generate cluster command returns a YAML template for creating a workload cluster .
The clusterctl generate cluster command uses smart defaults in order to simplify the user experience; for example,
if only the aws infrastructure provider is deployed, it detects and uses that when creating the cluster.
The clusterctl generate cluster command by default uses cluster templates which are provided by the infrastructure
providers. See the provider’s documentation for more information.
See the clusterctl generate cluster command documentation for
details about how to use alternative sources. for cluster templates.
Depending on the infrastructure provider you are planning to use, some additional prerequisites should be satisfied
before configuring a cluster with Cluster API. Instructions are provided for common providers below.
Otherwise, you can look at the clusterctl generate cluster command documentation for details about how to
discover the list of variables required by a cluster templates.
Akamai (Linode) AWS Azure CloudStack DigitalOcean Docker Equinix Metal GCP IBM Cloud IONOS Cloud K0smotron KubeKey KubeVirt Metal3 Nutanix OpenStack Outscale Proxmox Tinkerbell VCD vcluster Virtink vSphere
export LINODE_REGION=us-ord
export LINODE_TOKEN=<your linode PAT>
export LINODE_CONTROL_PLANE_MACHINE_TYPE=g6-standard-2
export LINODE_MACHINE_TYPE=g6-standard-2
See the Akamai (Linode) provider for more information.
export AWS_REGION=us-east-1
export AWS_SSH_KEY_NAME=default
# Select instance types
export AWS_CONTROL_PLANE_MACHINE_TYPE=t3.large
export AWS_NODE_MACHINE_TYPE=t3.large
See the AWS provider prerequisites document for more details.
Make sure you choose a VM size which is available in the desired location for your subscription. To see available SKUs, use az vm list-skus -l <your_location> -r virtualMachines -o table
# Name of the Azure datacenter location. Change this value to your desired location.
export AZURE_LOCATION="centralus"
# Select VM types.
export AZURE_CONTROL_PLANE_MACHINE_TYPE="Standard_D2s_v3"
export AZURE_NODE_MACHINE_TYPE="Standard_D2s_v3"
# [Optional] Select resource group. The default value is ${CLUSTER_NAME}.
export AZURE_RESOURCE_GROUP="<ResourceGroupName>"
A Cluster API compatible image must be available in your CloudStack installation. For instructions on how to build a compatible image
see image-builder (CloudStack)
Prebuilt images can be found here
To see all required CloudStack environment variables execute:
clusterctl generate cluster --infrastructure cloudstack --list-variables capi-quickstart
Apart from the script, the following CloudStack environment variables are required.
# Set this to the name of the zone in which to deploy the cluster
export CLOUDSTACK_ZONE_NAME=<zone name>
# The name of the network on which the VMs will reside
export CLOUDSTACK_NETWORK_NAME=<network name>
# The endpoint of the workload cluster
export CLUSTER_ENDPOINT_IP=<cluster endpoint address>
export CLUSTER_ENDPOINT_PORT=<cluster endpoint port>
# The service offering of the control plane nodes
export CLOUDSTACK_CONTROL_PLANE_MACHINE_OFFERING=<control plane service offering name>
# The service offering of the worker nodes
export CLOUDSTACK_WORKER_MACHINE_OFFERING=<worker node service offering name>
# The capi compatible template to use
export CLOUDSTACK_TEMPLATE_NAME=<template name>
# The ssh key to use to log into the nodes
export CLOUDSTACK_SSH_KEY_NAME=<ssh key name>
A full configuration reference can be found in configuration.md .
A ClusterAPI compatible image must be available in your DigitalOcean account. For instructions on how to build a compatible image
see image-builder .
export DO_REGION=nyc1
export DO_SSH_KEY_FINGERPRINT=<your-ssh-key-fingerprint>
export DO_CONTROL_PLANE_MACHINE_TYPE=s-2vcpu-2gb
export DO_CONTROL_PLANE_MACHINE_IMAGE=<your-capi-image-id>
export DO_NODE_MACHINE_TYPE=s-2vcpu-2gb
export DO_NODE_MACHINE_IMAGE==<your-capi-image-id>
The Docker provider is not designed for production use and is intended for development environments only.
The Docker provider does not require additional configurations for cluster templates.
However, if you require special network settings you can set the following environment variables:
# The list of service CIDR, default ["10.128.0.0/12"]
export SERVICE_CIDR=["10.96.0.0/12"]
# The list of pod CIDR, default ["192.168.0.0/16"]
export POD_CIDR=["192.168.0.0/16"]
# The service domain, default "cluster.local"
export SERVICE_DOMAIN="k8s.test"
It is also possible but not recommended to disable the per-default enabled Pod Security Standard :
export POD_SECURITY_STANDARD_ENABLED="false"
# Name of the GCP datacenter location. Change this value to your desired location
export GCP_REGION="<GCP_REGION>"
export GCP_PROJECT="<GCP_PROJECT>"
# Make sure to use same Kubernetes version here as building the GCE image
export KUBERNETES_VERSION=1.23.3
# This is the image you built. See https://github.com/kubernetes-sigs/image-builder
export IMAGE_ID=projects/$GCP_PROJECT/global/images/<built image>
export GCP_CONTROL_PLANE_MACHINE_TYPE=n1-standard-2
export GCP_NODE_MACHINE_TYPE=n1-standard-2
export GCP_NETWORK_NAME=<GCP_NETWORK_NAME or default>
export CLUSTER_NAME="<CLUSTER_NAME>"
See the GCP provider for more information.
# Required environment variables for VPC
# VPC region
export IBMVPC_REGION=us-south
# VPC zone within the region
export IBMVPC_ZONE=us-south-1
# ID of the resource group in which the VPC will be created
export IBMVPC_RESOURCEGROUP=<your-resource-group-id>
# Name of the VPC
export IBMVPC_NAME=ibm-vpc-0
export IBMVPC_IMAGE_ID=<you-image-id>
# Profile for the virtual server instances
export IBMVPC_PROFILE=bx2-4x16
export IBMVPC_SSHKEY_ID=<your-sshkey-id>
# Required environment variables for PowerVS
export IBMPOWERVS_SSHKEY_NAME=<your-ssh-key>
# Internal and external IP of the network
export IBMPOWERVS_VIP=<internal-ip>
export IBMPOWERVS_VIP_EXTERNAL=<external-ip>
export IBMPOWERVS_VIP_CIDR=29
export IBMPOWERVS_IMAGE_NAME=<your-capi-image-name>
# ID of the PowerVS service instance
export IBMPOWERVS_SERVICE_INSTANCE_ID=<service-instance-id>
export IBMPOWERVS_NETWORK_NAME=<your-capi-network-name>
Please visit the IBM Cloud provider for more information.
A ClusterAPI compatible image must be available in your IONOS Cloud contract.
For instructions on how to build a compatible Image, see our docs .
# The token which is used to authenticate against the IONOS Cloud API
export IONOS_TOKEN=<your-token>
# The datacenter ID where the cluster will be deployed
export IONOSCLOUD_DATACENTER_ID="<your-datacenter-id>"
# The IP of the control plane endpoint
export CONTROL_PLANE_ENDPOINT_IP=10.10.10.4
# The location of the data center where the cluster will be deployed
export CONTROL_PLANE_ENDPOINT_LOCATION=de/txl
# The image ID of the custom image that will be used for the VMs
export IONOSCLOUD_MACHINE_IMAGE_ID="<your-image-id>"
# The SSH key that will be used to access the VMs
export IONOSCLOUD_MACHINE_SSH_KEYS="<your-ssh-key>"
For more configuration options check our list of available variables
# Required environment variables
# The KKZONE is used to specify where to download the binaries. (e.g. "", "cn")
export KKZONE=""
# The ssh name of the all instance Linux user. (e.g. root, ubuntu)
export USER_NAME=<your-linux-user>
# The ssh password of the all instance Linux user.
export PASSWORD=<your-linux-user-password>
# The ssh IP address of the all instance. (e.g. "[{address: 192.168.100.3}, {address: 192.168.100.4}]")
export INSTANCES=<your-linux-ip-address>
# The cluster control plane VIP. (e.g. "192.168.100.100")
export CONTROL_PLANE_ENDPOINT_IP=<your-control-plane-virtual-ip>
Please visit the KubeKey provider for more information.
export CAPK_GUEST_K8S_VERSION="v1.23.10"
export CRI_PATH="/var/run/containerd/containerd.sock"
export NODE_VM_IMAGE_TEMPLATE="quay.io/capk/ubuntu-2004-container-disk:${CAPK_GUEST_K8S_VERSION}"
Please visit the KubeVirt project for more information.
A ClusterAPI compatible image must be available in your Nutanix image library. For instructions on how to build a compatible image
see image-builder .
To see all required Nutanix environment variables execute:
clusterctl generate cluster --infrastructure nutanix --list-variables capi-quickstart
A ClusterAPI compatible image must be available in your OpenStack. For instructions on how to build a compatible image
see image-builder .
Depending on your OpenStack and underlying hypervisor the following options might be of interest:
To see all required OpenStack environment variables execute:
clusterctl generate cluster --infrastructure openstack --list-variables capi-quickstart
The following script can be used to export some of them:
wget https://raw.githubusercontent.com/kubernetes-sigs/cluster-api-provider-openstack/master/templates/env.rc -O /tmp/env.rc
source /tmp/env.rc <path/to/clouds.yaml> <cloud>
Apart from the script, the following OpenStack environment variables are required.
# The list of nameservers for OpenStack Subnet being created.
# Set this value when you need create a new network/subnet while the access through DNS is required.
export OPENSTACK_DNS_NAMESERVERS=<dns nameserver>
# FailureDomain is the failure domain the machine will be created in.
export OPENSTACK_FAILURE_DOMAIN=<availability zone name>
# The flavor reference for the flavor for your server instance.
export OPENSTACK_CONTROL_PLANE_MACHINE_FLAVOR=<flavor>
# The flavor reference for the flavor for your server instance.
export OPENSTACK_NODE_MACHINE_FLAVOR=<flavor>
# The name of the image to use for your server instance. If the RootVolume is specified, this will be ignored and use rootVolume directly.
export OPENSTACK_IMAGE_NAME=<image name>
# The SSH key pair name
export OPENSTACK_SSH_KEY_NAME=<ssh key pair name>
# The external network
export OPENSTACK_EXTERNAL_NETWORK_ID=<external network ID>
A full configuration reference can be found in configuration.md .
A ClusterAPI compatible image must be available in your Outscale account. For instructions on how to build a compatible image
see image-builder .
# The outscale root disk iops
export OSC_IOPS="<IOPS>"
# The outscale root disk size
export OSC_VOLUME_SIZE="<VOLUME_SIZE>"
# The outscale root disk volumeType
export OSC_VOLUME_TYPE="<VOLUME_TYPE>"
# The outscale key pair
export OSC_KEYPAIR_NAME="<KEYPAIR_NAME>"
# The outscale subregion name
export OSC_SUBREGION_NAME="<SUBREGION_NAME>"
# The outscale vm type
export OSC_VM_TYPE="<VM_TYPE>"
# The outscale image name
export OSC_IMAGE_NAME="<IMAGE_NAME>"
A ClusterAPI compatible image must be available in your Proxmox cluster. For instructions on how to build a compatible VM template
see image-builder .
# The node that hosts the VM template to be used to provision VMs
export PROXMOX_SOURCENODE="pve"
# The template VM ID used for cloning VMs
export TEMPLATE_VMID=100
# The ssh authorized keys used to ssh to the machines.
export VM_SSH_KEYS="ssh-ed25519 ..., ssh-ed25519 ..."
# The IP address used for the control plane endpoint
export CONTROL_PLANE_ENDPOINT_IP=10.10.10.4
# The IP ranges for Cluster nodes
export NODE_IP_RANGES="[10.10.10.5-10.10.10.50, 10.10.10.55-10.10.10.70]"
# The gateway for the machines network-config.
export GATEWAY="10.10.10.1"
# Subnet Mask in CIDR notation for your node IP ranges
export IP_PREFIX=24
# The Proxmox network device for VMs
export BRIDGE="vmbr1"
# The dns nameservers for the machines network-config.
export DNS_SERVERS="[8.8.8.8,8.8.4.4]"
# The Proxmox nodes used for VM deployments
export ALLOWED_NODES="[pve1,pve2,pve3]"
For more information about prerequisites and advanced setups for Proxmox, see the Proxmox getting started guide .
A ClusterAPI compatible image must be available in your VCD catalog. For instructions on how to build and upload a compatible image
see CAPVCD
To see all required VCD environment variables execute:
clusterctl generate cluster --infrastructure vcd --list-variables capi-quickstart
export CLUSTER_NAME=kind
export CLUSTER_NAMESPACE=vcluster
export KUBERNETES_VERSION=1.23.4
export HELM_VALUES="service:\n type: NodePort"
Please see the vcluster installation instructions for more details.
To see all required Virtink environment variables execute:
clusterctl generate cluster --infrastructure virtink --list-variables capi-quickstart
See the Virtink provider document for more details.
It is required to use an official CAPV machine images for your vSphere VM templates. See uploading CAPV machine images for instructions on how to do this.
# The vCenter server IP or FQDN
export VSPHERE_SERVER="10.0.0.1"
# The vSphere datacenter to deploy the management cluster on
export VSPHERE_DATACENTER="SDDC-Datacenter"
# The vSphere datastore to deploy the management cluster on
export VSPHERE_DATASTORE="vsanDatastore"
# The VM network to deploy the management cluster on
export VSPHERE_NETWORK="VM Network"
# The vSphere resource pool for your VMs
export VSPHERE_RESOURCE_POOL="*/Resources"
# The VM folder for your VMs. Set to "" to use the root vSphere folder
export VSPHERE_FOLDER="vm"
# The VM template to use for your VMs
export VSPHERE_TEMPLATE="ubuntu-1804-kube-v1.17.3"
# The public ssh authorized key on all machines
export VSPHERE_SSH_AUTHORIZED_KEY="ssh-rsa AAAAB3N..."
# The certificate thumbprint for the vCenter server
export VSPHERE_TLS_THUMBPRINT="97:48:03:8D:78:A9..."
# The storage policy to be used (optional). Set to "" if not required
export VSPHERE_STORAGE_POLICY="policy-one"
# The IP address used for the control plane endpoint
export CONTROL_PLANE_ENDPOINT_IP="1.2.3.4"
For more information about prerequisites, credentials management, or permissions for vSphere, see the vSphere getting started guide .
For the purpose of this tutorial, we’ll name our cluster capi-quickstart.
This creates a YAML file named capi-quickstart.yaml with a predefined list of Cluster API objects; Cluster, Machines,
Machine Deployments, etc.
The file can be eventually modified using your editor of choice.
See clusterctl generate cluster for more details.
When ready, run the following command to apply the cluster manifest.
kubectl apply -f capi-quickstart.yaml
The output is similar to this:
cluster.cluster.x-k8s.io/capi-quickstart created
dockercluster.infrastructure.cluster.x-k8s.io/capi-quickstart created
kubeadmcontrolplane.controlplane.cluster.x-k8s.io/capi-quickstart-control-plane created
dockermachinetemplate.infrastructure.cluster.x-k8s.io/capi-quickstart-control-plane created
machinedeployment.cluster.x-k8s.io/capi-quickstart-md-0 created
dockermachinetemplate.infrastructure.cluster.x-k8s.io/capi-quickstart-md-0 created
kubeadmconfigtemplate.bootstrap.cluster.x-k8s.io/capi-quickstart-md-0 created
The cluster will now start provisioning. You can check status with:
kubectl get cluster
You can also get an “at glance” view of the cluster and its resources by running:
clusterctl describe cluster capi-quickstart
and see an output similar to this:
NAME PHASE AGE VERSION
capi-quickstart Provisioned 8s v1.30.0
To verify the first control plane is up:
kubectl get kubeadmcontrolplane
You should see an output is similar to this:
NAME CLUSTER INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
capi-quickstart-g2trk capi-quickstart true 3 3 3 4m7s v1.30.0
After the first control plane node is up and running, we can retrieve the workload cluster Kubeconfig.
The Kubernetes in-tree cloud provider implementations are being removed in favor of external cloud providers (also referred to as “out-of-tree”). This requires deploying a new component called the cloud-controller-manager which is responsible for running all the cloud specific controllers that were previously run in the kube-controller-manager. To learn more, see this blog post .
Azure OpenStack
Install the official cloud-provider-azure Helm chart on the workload cluster:
helm install --kubeconfig=./capi-quickstart.kubeconfig --repo https://raw.githubusercontent.com/kubernetes-sigs/cloud-provider-azure/master/helm/repo cloud-provider-azure --generate-name --set infra.clusterName=capi-quickstart --set cloudControllerManager.clusterCIDR="192.168.0.0/16"
For more information, see the CAPZ book .
Before deploying the OpenStack external cloud provider, configure the cloud.conf file for integration with your OpenStack environment:
cat > cloud.conf <<EOF
[Global]
auth-url=<your_auth_url>
application-credential-id=<your_credential_id>
application-credential-secret=<your_credential_secret>
region=<your_region>
domain-name=<your_domain_name>
EOF
For more detailed information on configuring the cloud.conf file, see the OpenStack Cloud Controller Manager documentation .
Next, create a Kubernetes secret using this configuration to securely store your cloud environment details.
You can create this secret for example with:
kubectl --kubeconfig=./capi-quickstart.kubeconfig -n kube-system create secret generic cloud-config --from-file=cloud.conf
Now, you are ready to deploy the external cloud provider!
kubectl apply --kubeconfig=./capi-quickstart.kubeconfig -f https://raw.githubusercontent.com/kubernetes/cloud-provider-openstack/master/manifests/controller-manager/cloud-controller-manager-roles.yaml
kubectl apply --kubeconfig=./capi-quickstart.kubeconfig -f https://raw.githubusercontent.com/kubernetes/cloud-provider-openstack/master/manifests/controller-manager/cloud-controller-manager-role-bindings.yaml
kubectl apply --kubeconfig=./capi-quickstart.kubeconfig -f https://raw.githubusercontent.com/kubernetes/cloud-provider-openstack/master/manifests/controller-manager/openstack-cloud-controller-manager-ds.yaml
Alternatively, refer to the helm chart .
Calico is used here as an example.
Azure vcluster KubeVirt Other providers...
Install the official Calico Helm chart on the workload cluster:
helm repo add projectcalico https://docs.tigera.io/calico/charts --kubeconfig=./capi-quickstart.kubeconfig && \
helm install calico projectcalico/tigera-operator --kubeconfig=./capi-quickstart.kubeconfig -f https://raw.githubusercontent.com/kubernetes-sigs/cluster-api-provider-azure/main/templates/addons/calico/values.yaml --namespace tigera-operator --create-namespace
After a short while, our nodes should be running and in Ready state,
let’s check the status using kubectl get nodes:
kubectl --kubeconfig=./capi-quickstart.kubeconfig get nodes
Calico not required for vcluster.
Before deploying the Calico CNI, make sure the VMs are running:
kubectl get vm
If our new VMs are running, we should see a response similar to this:
NAME AGE STATUS READY
capi-quickstart-control-plane-7s945 167m Running True
capi-quickstart-md-0-zht5j 164m Running True
We can also read the virtual machine instances:
kubectl get vmi
The output will be similar to:
NAME AGE PHASE IP NODENAME READY
capi-quickstart-control-plane-7s945 167m Running 10.244.82.16 kind-control-plane True
capi-quickstart-md-0-zht5j 164m Running 10.244.82.17 kind-control-plane True
Since our workload cluster is running within the kind cluster, we need to prevent conflicts between the kind
(management) cluster’s CNI, and the workload cluster CNI. The following modifications in the default Calico settings
are enough for these two CNI to work on (actually) the same environment.
Change the CIDR to a non-conflicting range
Change the value of the CLUSTER_TYPE environment variable to k8s
Change the value of the CALICO_IPV4POOL_IPIP environment variable to Never
Change the value of the CALICO_IPV4POOL_VXLAN environment variable to Always
Add the FELIX_VXLANPORT environment variable with the value of a non-conflicting port, e.g. "6789".
The following script downloads the Calico manifest and modifies the required field. The CIDR and the port values are examples.
curl https://raw.githubusercontent.com/projectcalico/calico/v3.24.4/manifests/calico.yaml -o calico-workload.yaml
sed -i -E 's|^( +)# (- name: CALICO_IPV4POOL_CIDR)$|\1\2|g;'\
's|^( +)# ( value: )"192.168.0.0/16"|\1\2"10.243.0.0/16"|g;'\
'/- name: CLUSTER_TYPE/{ n; s/( +value: ").+/\1k8s"/g };'\
'/- name: CALICO_IPV4POOL_IPIP/{ n; s/value: "Always"/value: "Never"/ };'\
'/- name: CALICO_IPV4POOL_VXLAN/{ n; s/value: "Never"/value: "Always"/};'\
'/# Set Felix endpoint to host default action to ACCEPT./a\ - name: FELIX_VXLANPORT\n value: "6789"' \
calico-workload.yaml
Now, deploy the Calico CNI on the workload cluster:
kubectl --kubeconfig=./capi-quickstart.kubeconfig create -f calico-workload.yaml
After a short while, our nodes should be running and in Ready state, let’s check the status using kubectl get nodes:
kubectl --kubeconfig=./capi-quickstart.kubeconfig get nodes
If the nodes don’t become ready after a long period, read the pods in the kube-system namespace
kubectl --kubeconfig=./capi-quickstart.kubeconfig get pod -n kube-system
If the Calico pods are in image pull error state (ErrImagePull), it’s probably because of the Docker Hub pull rate limit.
We can try to fix that by adding a secret with our Docker Hub credentials, and use it;
see here
for details.
First, create the secret. Please notice the Docker config file path, and adjust it to your local setting.
kubectl --kubeconfig=./capi-quickstart.kubeconfig create secret generic docker-creds \
--from-file=.dockerconfigjson=<YOUR DOCKER CONFIG FILE PATH> \
--type=kubernetes.io/dockerconfigjson \
-n kube-system
Now, if the calico-node pods are with status of ErrImagePull, patch their DaemonSet to make them use the new secret to pull images:
kubectl --kubeconfig=./capi-quickstart.kubeconfig patch daemonset \
-n kube-system calico-node \
-p '{"spec":{"template":{"spec":{"imagePullSecrets":[{"name":"docker-creds"}]}}}}'
After a short while, the calico-node pods will be with Running status. Now, if the calico-kube-controllers pod is also
in ErrImagePull status, patch its deployment to fix the problem:
kubectl --kubeconfig=./capi-quickstart.kubeconfig patch deployment \
-n kube-system calico-kube-controllers \
-p '{"spec":{"template":{"spec":{"imagePullSecrets":[{"name":"docker-creds"}]}}}}'
Read the pods again
kubectl --kubeconfig=./capi-quickstart.kubeconfig get pod -n kube-system
Eventually, all the pods in the kube-system namespace will run, and the result should be similar to this:
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-c969cf844-dgld6 1/1 Running 0 50s
calico-node-7zz7c 1/1 Running 0 54s
calico-node-jmjd6 1/1 Running 0 54s
coredns-64897985d-dspjm 1/1 Running 0 3m49s
coredns-64897985d-pgtgz 1/1 Running 0 3m49s
etcd-capi-quickstart-control-plane-kjjbb 1/1 Running 0 3m57s
kube-apiserver-capi-quickstart-control-plane-kjjbb 1/1 Running 0 3m57s
kube-controller-manager-capi-quickstart-control-plane-kjjbb 1/1 Running 0 3m57s
kube-proxy-b9g5m 1/1 Running 0 3m12s
kube-proxy-p6xx8 1/1 Running 0 3m49s
kube-scheduler-capi-quickstart-control-plane-kjjbb 1/1 Running 0 3m57s
kubectl --kubeconfig=./capi-quickstart.kubeconfig \
apply -f https://raw.githubusercontent.com/projectcalico/calico/v3.26.1/manifests/calico.yaml
After a short while, our nodes should be running and in Ready state,
let’s check the status using kubectl get nodes:
kubectl --kubeconfig=./capi-quickstart.kubeconfig get nodes
NAME STATUS ROLES AGE VERSION
capi-quickstart-vs89t-gmbld Ready control-plane 5m33s v1.30.0
capi-quickstart-vs89t-kf9l5 Ready control-plane 6m20s v1.30.0
capi-quickstart-vs89t-t8cfn Ready control-plane 7m10s v1.30.0
capi-quickstart-md-0-55x6t-5649968bd7-8tq9v Ready <none> 6m5s v1.30.0
capi-quickstart-md-0-55x6t-5649968bd7-glnjd Ready <none> 6m9s v1.30.0
capi-quickstart-md-0-55x6t-5649968bd7-sfzp6 Ready <none> 6m9s v1.30.0
Delete workload cluster.
kubectl delete cluster capi-quickstart
IMPORTANT: In order to ensure a proper cleanup of your infrastructure you must always delete the cluster object. Deleting the entire cluster template with kubectl delete -f capi-quickstart.yaml might lead to pending resources to be cleaned up manually.
Delete management cluster
kind delete cluster
Create a second workload cluster. Simply follow the steps outlined above, but remember to provide a different name for your second workload cluster.
Deploy applications to your workload cluster. Use the CNI deployment steps for pointers.
See the clusterctl documentation for more detail about clusterctl supported actions.
This section provides a quickstart guide for using the Cluster API Operator to create a Kubernetes cluster.
To use the clusterctl quickstart path, visit this quickstart guide .
This is a quickstart guide for getting Cluster API Operator up and running on your Kubernetes cluster.
For more detailed information, please refer to the full documentation.
Instead of using environment variables as clusterctl does, Cluster API Operator uses Kubernetes secrets to store credentials for cloud providers. Refer to provider documentation on which credentials are required.
This example uses AWS provider, but the same approach can be used for other providers.
export CREDENTIALS_SECRET_NAME="credentials-secret"
export CREDENTIALS_SECRET_NAMESPACE="default"
kubectl create secret generic "${CREDENTIALS_SECRET_NAME}" --from-literal=AWS_B64ENCODED_CREDENTIALS="${AWS_B64ENCODED_CREDENTIALS}" --namespace "${CREDENTIALS_SECRET_NAMESPACE}"
Add CAPI Operator & cert manager helm repository:
helm repo add capi-operator https://kubernetes-sigs.github.io/cluster-api-operator
helm repo add jetstack https://charts.jetstack.io --force-update
helm repo update
Install cert manager:
helm install cert-manager jetstack/cert-manager --namespace cert-manager --create-namespace --set installCRDs=true
Deploy Cluster API components with docker provider using a single command during operator installation
The --wait flag is REQUIRED for the helm install command to work. If the --wait flag is not used, the helm install command will not wait for the resources to be created and will return immediately. This will cause the helm install command to fail because the webhooks will not be ready in time. The --timeout flag is optional and can be used to specify the amount of time to wait for the resources to be created.
helm install capi-operator capi-operator/cluster-api-operator --create-namespace -n capi-operator-system --set infrastructure=docker --set cert-manager.enabled=true --set configSecret.name=${CREDENTIALS_SECRET_NAME} --set configSecret.namespace=${CREDENTIALS_SECRET_NAMESPACE} --wait --timeout 90s
Docker provider can be replaced by any provider supported by clusterctl .
Other options for installing Cluster API Operator are described in full documentation .
Deploy latest version of core Cluster API components:
apiVersion: operator.cluster.x-k8s.io/v1alpha2
kind: CoreProvider
metadata:
name: cluster-api
namespace: capi-system
Deploy Cluster API AWS provider with specific version, custom manager options and flags:
---
apiVersion: operator.cluster.x-k8s.io/v1alpha2
kind: InfrastructureProvider
metadata:
name: aws
namespace: capa-system
spec:
version: v2.1.4
configSecret:
name: aws-variables
A Kubernetes cluster that manages the lifecycle of Workload Clusters. A Management Cluster is also where one or more providers run, and where resources such as Machines are stored.
A Kubernetes cluster whose lifecycle is managed by a Management Cluster.
A component responsible for the provisioning of infrastructure/computational resources required by the Cluster or by Machines (e.g. VMs, networking, etc.).
For example, cloud Infrastructure Providers include AWS, Azure, and Google, and bare metal Infrastructure Providers include VMware, MAAS, and metal3.io.
When there is more than one way to obtain resources from the same Infrastructure Provider (such as AWS offering both EC2 and EKS), each way is referred to as a variant.
A component responsible for turning a server into a Kubernetes node as well as for:
Generating the cluster certificates, if not otherwise specified
Initializing the control plane, and gating the creation of other nodes until it is complete
Joining control plane and worker nodes to the cluster
The control plane is a set of components that serve the Kubernetes API and continuously reconcile desired state using control loops .
Self-provisioned : A Kubernetes control plane consisting of pods or machines wholly managed by a single Cluster API deployment.
e.g kubeadm uses static pods for running components such as kube-apiserver , kube-controller-manager and kube-scheduler
on control plane machines.
Pod-based deployments require an external hosting cluster. The control plane components are deployed using standard Deployment and StatefulSet objects and the API is exposed using a Service .
External or Managed control planes are offered and controlled by some system other than Cluster API, such as GKE, AKS, EKS, or IKS.
The default provider uses kubeadm to bootstrap the control plane. As of v1alpha3, it exposes the configuration via the KubeadmControlPlane object. The controller, capi-kubeadm-control-plane-controller-manager, can then create Machine and BootstrapConfig objects based on the requested replicas in the KubeadmControlPlane object.
A CustomResourceDefinition is a built-in resource that lets you extend the Kubernetes API. Each CustomResourceDefinition represents a customization of a Kubernetes installation. The Cluster API provides and relies on several CustomResourceDefinitions:
A “Machine” is the declarative spec for an infrastructure component hosting a Kubernetes Node (for example, a VM). If a new Machine object is created, a provider-specific controller will provision and install a new host to register as a new Node matching the Machine spec. If the Machine’s spec is updated, the controller replaces the host with a new one matching the updated spec. If a Machine object is deleted, its underlying infrastructure and corresponding Node will be deleted by the controller.
Common fields such as Kubernetes version are modeled as fields on the Machine’s spec. Any information that is provider-specific is part of the InfrastructureRef and is not portable between different providers.
From the perspective of Cluster API, all Machines are immutable: once they are created, they are never updated (except for labels, annotations and status), only deleted.
For this reason, MachineDeployments are preferable. MachineDeployments handle changes to machines by replacing them, in the same way core Deployments handle changes to Pod specifications.
A MachineDeployment provides declarative updates for Machines and MachineSets.
A MachineDeployment works similarly to a core Kubernetes Deployment . A MachineDeployment reconciles changes to a Machine spec by rolling out changes to 2 MachineSets, the old and the newly updated.
A MachineSet’s purpose is to maintain a stable set of Machines running at any given time.
A MachineSet works similarly to a core Kubernetes ReplicaSet . MachineSets are not meant to be used directly, but are the mechanism MachineDeployments use to reconcile desired state.
A MachineHealthCheck defines the conditions when a Node should be considered unhealthy.
If the Node matches these unhealthy conditions for a given user-configured time, the MachineHealthCheck initiates remediation of the Node. Remediation of Nodes is performed by deleting the corresponding Machine.
MachineHealthChecks will only remediate Nodes if they are owned by a MachineSet. This ensures that the Kubernetes cluster does not lose capacity, since the MachineSet will create a new Machine to replace the failed Machine.
BootstrapData contains the Machine or Node role-specific initialization data (usually cloud-init) used by the Infrastructure Provider to bootstrap a Machine into a Node.
Taking inspiration from Tim Hockin’s talk at KubeCon NA 2023 , also for the
Cluster API project is important to define the long term vision, the manifesto of “where we are going” and “why”.
This document would hopefully provide valuable context for all users, contributors and companies investing in this project,
as well as act as compass for all reviewers and maintainers currently working on it.
Together we can go far.
The Cluster API community is the foundation for this project’s past, present and future.
The project will continue to encourage and praise active participation and contribution.
We are an active part of a bigger ecosystem
The Cluster API community is an active part of Kubernetes SIG Cluster Lifecycle, of the broader Kubernetes community
and of the CNCF.
CNCF provides the core values this project recognizes and contributes to.
The Kubernetes community provides most of the practices and policies this project abides to or is inspired by.
The project remains true to its original goals and design principles:
Cluster API is a Kubernetes sub-project focused on providing declarative APIs and tooling to simplify provisioning,
upgrading, and operating multiple Kubernetes clusters.
Nowadays, like at the beginning of the project, some concepts from the above statement deserve further clarification.
The Cluster API project motto is “Kubernetes all the way down”, and this boils down to two elements.
The target state of a cluster can be defined using Kubernetes declarative APIs.
The project also implements controllers – Kubernetes reconcile loops – ensuring that desired and current state of the
cluster will remain consistent over time.
The combination of those elements, declarative APIs and controllers, defines “how” this project aims to make Kubernetes
and Cluster API a stable, reliable and consistent platform that just works to enable higher order business value
supported by cloud-native applications.
Kubernetes Cluster lifecycle management is a complex problem space, especially if you consider doing this across so
many different types of infrastructures.
Hiding this complexity behind a simple declarative API is “why” the Cluster API project ultimately exists.
The project is strongly committed to continue its quest in defining a set of common API primitives working consistently
across all infrastructures (one API to rule them all).
Working towards graduating our API to v1 will be the next step in this journey.
While doing so, the project should be inspired by Tim Hockin’s talk, and continue to move forward without increasing
operational and conceptual complexity for Cluster API’s users.
Like Kubernetes, also the Cluster API project claims the right to remain unfinished, because there is still a strong,
foundational need to continuously evolve, improve and adapt to the changing needs of Cluster API’s users and to the
growing Cloud Native ecosystem.
What is important to notice, is that being a project that is “continuously evolving” is not in contrast with another
request from Cluster API’s users, which is about the project being stable, as expected by a system that has “crossed the chasm”.
Those two requests from Cluster API’s users are two sides of the same coin, a reminder that Cluster API must
“evolve responsibly” by ensuring upgrade paths and avoiding (or at least minimizing) disruptions for users.
The Cluster API project will continue to “evolve responsibly” by abiding to the same guarantees that Kubernetes offers
for its own APIs, but also ensuring a continuous and obsessive focus on CI signal, test coverage and test flakes.
Also ensuring a predictable release calendar, clear support windows and compatibility matrix for each release
is a crucial part of this effort to “evolve responsibly”.
Tim Hockins explains the idea of complexity budget very well in his talk:
There is a finite amount of complexity that a project can absorb over a certain amount of time;
when the complexity budget runs out, bad things happen, quality decreases, we can’t fix bugs timely etc.
Since the beginning of the Cluster API project, its maintainers intuitively handled the complexity budget by following
this approach:
“We’ve got to say no to things today, so we can afford to do interesting things tomorrow”.
This is something that is never done lightly, and it is always the result of an open discussion considering the status
of the codebase, the status of the project CI signal, the complexity of the new feature etc. .
Being very pragmatic, also the resources committed to implement and to maintain a feature over time must be considered
when doing such an evaluation, because a model where everything falls on the shoulders of a small set of core
maintainers is not sustainable.
On the other side of this coin, Cluster API maintainer’s also claim the right to reconsider new ideas or ideas
previously put on hold whenever there are the conditions and the required community consensus to work on it.
Probably the most well-known case of this is about Cluster API maintainers repeatedly deferring on change requests
about nodes mutability in the initial phases of the project, while starting to embrace some mutable behavior in recent releases.
Together we can go far.
The Cluster API project is committed to keep working with the broader CAPI community – all the Cluster API providers –
as a single team in order to continuously improve and expand the capability of this solution.
As we learned the hard way, the extensibility model implemented by CAPI to support so many providers requires a
complementary effort to continuously explore new ways to offer a cohesive solution, not a bag of parts.
It is important to continue and renew efforts to make it easier to bootstrap and operate a system composed of many
components, to ensure consistent APIs and behaviors, to ensure quality across the board.
This effort lays its foundation in all the provider maintainers being committed to this goal, while the Cluster API project
will be the venue where common guidelines are discussed and documented, as well as the place of choice where common
components or utilities are developed and hosted.
This document describes the personas for the Cluster API project as driven
from use cases.
We are marking a “proposed priority for project at this time” per use case.
This is not intended to say that these use cases aren’t awesome or important.
They are intended to indicate where we, as a project, have received a great deal
of interest, and as a result where we think we should invest right now to get
the most users for our project. If interest grows in other areas, they will
be elevated. And, since this is an open source project, if you want to drive
feature development for a less-prioritized persona, we absolutely encourage
you to join us and do that.
Managed Kubernetes is an offering in which a provider is automating the
lifecycle management of Kubernetes clusters, including full control planes
that are available to, and used directly by, the customer.
Proposed priority for project at this time: High
There are several projects from several companies that are building out
proposed managed Kubernetes offerings (Project Pacific’s Kubernetes Service
from VMware, Microsoft Azure, Google Cloud, Red Hat) and they have all
expressed a desire to use Cluster API. This looks like a good place to make
sure Cluster API works well, and then expand to other use cases.
Feature matrix
Is Cluster API exposed to this user? Yes Are control plane nodes exposed to this user? Yes How many clusters are being managed via this user? Many Who is the CAPI admin in this scenario? Platform Operator Cloud / On-Prem Both Upgrade strategies desired? Need to gather data from users How does this user interact with Cluster API? API ETCD deployment Need to gather data from users Does this user have a preference for the control plane running on pods vs. vm vs. something else? Need to gather data from users
Examples of a Kubernetes-as-a-Service provider include services such as
Red Hat’s hosted OpenShift, AKS, GKE, and EKS. The cloud services manage the
control plane, often giving those cloud resources away “for free,” and the
customers spin up and down their own worker nodes.
Proposed priority for project at this time: Medium
Existing Kubernetes as a Service providers, e.g. AKS, GKE have indicated
interest in replacing their off-tree automation with Cluster API, however
since they already had to build their own automation and it is currently
“getting the job done,” switching to Cluster API is not a top priority for
them, although it is desirable.
Feature matrix
Is Cluster API exposed to this user? Need to gather data from users Are control plane nodes exposed to this user? No How many clusters are being managed via this user? Many Who is the CAPI admin in this scenario? Platform itself (AKS, GKE, etc.) Cloud / On-Prem Cloud Upgrade strategies desired? tear down/replace (need confirmation from platforms) How does this user interact with Cluster API? API ETCD deployment Need to gather data from users Does this user have a preference for the control plane running on pods vs. vm vs. something else? Need to gather data from users
The Cluster API developer is a developer of Cluster API who needs tools and
services to make their development experience more productive and pleasant.
It’s also important to take a look at the on-boarding experience for new
developers to make sure we’re building out a project that other people can
more easily submit patches and features to, to encourage inclusivity and
welcome new contributors.
Proposed priority for project at this time: Low
We think we’re in a good place right now, and while we welcome contributions
to improve the development experience of the project, it should not be the
primary product focus of the open source development team to make development
better for ourselves.
Feature matrix
Is Cluster API exposed to this user? Yes Are control plane nodes exposed to this user? Yes How many clusters are being managed via this user? Many Who is the CAPI admin in this scenario? Platform Operator Cloud / On-Prem Both Upgrade strategies desired? Need to gather data from users How does this user interact with Cluster API? API ETCD deployment Need to gather data from users Does this user have a preference for the control plane running on pods vs. vm vs. something else? Need to gather data from users
Examples of a raw API consumer is a tool like Prow, a customized enterprise
platform built on top of Cluster API, or perhaps an advanced “give me a
Kubernetes cluster” button exposing some customization that is built using
Cluster API.
Proposed priority for project at this time: Low
Feature matrix
Is Cluster API exposed to this user? Yes Are control plane nodes exposed to this user? Yes How many clusters are being managed via this user? Many Who is the CAPI admin in this scenario? Platform Operator Cloud / On-Prem Both Upgrade strategies desired? Need to gather data from users How does this user interact with Cluster API? API ETCD deployment Need to gather data from users Does this user have a preference for the control plane running on pods vs. vm vs. something else? Need to gather data from users
Examples of this use case, in which a tooling provisioner is using
Cluster API to automate behavior, includes tools such as kOps and kubicorn.
Proposed priority for project at this time: Low
Maintainers of tools such as kOps have indicated interest in using
Cluster API, but they have also indicated they do not have much time to
take on the work. If this changes, this use case would increase in priority.
Feature matrix
Is Cluster API exposed to this user? Need to gather data from tooling maintainers Are control plane nodes exposed to this user? Yes How many clusters are being managed via this user? One (per execution) Who is the CAPI admin in this scenario? Kubernetes Platform Consumer Cloud / On-Prem Cloud Upgrade strategies desired? Need to gather data from users How does this user interact with Cluster API? CLI ETCD deployment (Stacked or external) AND new Does this user have a preference for the control plane running on pods vs. vm vs. something else? Need to gather data from users
This user would be an end user or consumer who is given direct access to
Cluster API via their service provider to manage Kubernetes clusters.
While there are some commercial projects who plan on doing this (Project
Pacific, others), they are doing this as a “super user” feature behind the
backdrop of a “Managed Kubernetes” offering.
Proposed priority for project at this time: Low
This is a use case we should keep an eye on to see how people use Cluster API
directly, but we think the more relevant use case is people building managed
offerings on top at this top.
Feature matrix
Is Cluster API exposed to this user? Yes Are control plane nodes exposed to this user? Yes How many clusters are being managed via this user? Many Who is the CAPI admin in this scenario? Platform Operator Cloud / On-Prem Both Upgrade strategies desired? Need to gather data from users How does this user interact with Cluster API? API ETCD deployment Need to gather data from users Does this user have a preference for the control plane running on pods vs. vm vs. something else? Need to gather data from users
This section provides details for some of the operations that need to be performed
when managing clusters.
This section details some tasks related to certificate management.
Cluster API expects certificates and keys used for bootstrapping to follow the below convention. CABPK generates new certificates using this convention if they do not already exist.
Each certificate must be stored in a single secret named one of:
Name Type Example
[cluster name] -ca CA openssl req -x509 -subj “/CN=Kubernetes API” -new -newkey rsa:2048 -nodes -keyout tls.key -sha256 -days 3650 -out tls.crt [cluster name] -etcd CA openssl req -x509 -subj “/CN=ETCD CA” -new -newkey rsa:2048 -nodes -keyout tls.key -sha256 -days 3650 -out tls.crt [cluster name] -proxy CA openssl req -x509 -subj “/CN=Front-End Proxy” -new -newkey rsa:2048 -nodes -keyout tls.key -sha256 -days 3650 -out tls.crt [cluster name] -sa Key Pair openssl genrsa -out tls.key 2048 && openssl rsa -in tls.key -pubout -out tls.crt
The certificates must also be labeled with the key-value pair cluster.x-k8s.io/cluster-name=[cluster name] (where [cluster name] is the name of the cluster it should be used with).
Note that rotating CA certificates is non-trivial and it is recommended to create a long-lived CA or use a long-lived root/offline CA with a short lived intermediary CA
Example
apiVersion: v1
kind: Secret
metadata:
name: cluster1-ca
labels:
cluster.x-k8s.io/cluster-name: cluster1
type: kubernetes.io/tls
data:
tls.crt: <base 64 encoded PEM>
tls.key: <base 64 encoded PEM>
Create a new Certificate Signing Request (CSR) for the admin user with the system:masters Kubernetes role, or specify any other role under O.
openssl req -subj "/CN=admin/O=system:masters" -new -newkey rsa:2048 -nodes -keyout admin.key -out admin.csr
Sign the CSR using the [cluster-name]-ca key:
openssl x509 -req -in admin.csr -CA tls.crt -CAkey tls.key -CAcreateserial -out admin.crt -days 5 -sha256
Update your kubeconfig with the sign key:
kubectl config set-credentials cluster-admin --client-certificate=admin.crt --client-key=admin.key --embed-certs=true
When using Kubeadm Control Plane provider (KCP) it is possible to configure automatic certificate rotations. KCP does this by triggering a rollout when the certificates on the control plane machines are about to expire.
If configured, the certificate rollout feature is available for all new and existing control plane machines.
To configure a rollout on the KCP machines you need to set .rolloutBefore.certificatesExpiryDays (minimum of 7 days).
Example:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlane
metadata:
name: example-control-plane
spec:
rolloutBefore:
certificatesExpiryDays: 21 # trigger a rollout if certificates expire within 21 days
kubeadmConfigSpec:
clusterConfiguration:
...
initConfiguration:
...
joinConfiguration:
...
machineTemplate:
infrastructureRef:
...
replicas: 1
version: v1.23.3
It is strongly recommended to set the certificatesExpiryDays to a large enough value so that all the machines will have time to complete rollout well in advance before the certificates expire.
KCP uses the value in the corresponding Control Plane machine’s Machine.Status.CertificatesExpiryDate to check if a machine’s certificates are going to expire and if it needs to be rolled out.
Machine.Status.CertificatesExpiryDate gets its value from one of the following 2 places:
machine.cluster.x-k8s.io/certificates-expiry annotation value on the Machine object. This annotation is not applied by default and it can be set by users to manually override the certificate expiry information.machine.cluster.x-k8s.io/certificates-expiry annotation value on the Bootstrap Config object referenced by the machine. This value is automatically set for machines bootstrapped with CABPK that are owned by the KCP resource.
The annotation value is a RFC3339 format timestamp. The annotation value on the machine object, if provided, will take precedence.
It is assumed that all certificates on a control plane node have roughly the same expiration time (+/- a few minutes). KCP decides when a rotation is needed based on the expiry of the kube-apiserver certificate.
If certificates on control plane nodes are rotated manually (e.g. via kubeadm certs renew), please be aware that the rotation is only
complete after all components including the kube-apiserver are using the new certificates. Thus, kube-apiserver, kube-controller-manager, kube-scheduler and etcd have to be restarted after certificate renewal.
To allow KCP to re-discover the expiry date please remove the machine.cluster.x-k8s.io/certificates-expiry annotation from the
KubeadmConfig corresponding to the current machine.
This section provides details about bootstrap providers.
Cluster API bootstrap provider Kubeadm (CABPK) is a component responsible for generating a cloud-init script to
turn a Machine into a Kubernetes Node. This implementation uses kubeadm
for Kubernetes bootstrap.
Assuming you have deployed the CAPI and CAPD controllers, create a Cluster object and its corresponding DockerCluster
infrastructure object.
kind: DockerCluster
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
metadata:
name: my-cluster-docker
---
kind: Cluster
apiVersion: cluster.x-k8s.io/v1beta1
metadata:
name: my-cluster
spec:
infrastructureRef:
kind: DockerCluster
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
name: my-cluster-docker
Now you can start creating machines by defining a Machine, its corresponding DockerMachine object, and
the KubeadmConfig bootstrap object.
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
metadata:
name: my-control-plane1-config
spec:
initConfiguration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
---
kind: DockerMachine
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
metadata:
name: my-control-plane1-docker
---
kind: Machine
apiVersion: cluster.x-k8s.io/v1beta1
metadata:
name: my-control-plane1
labels:
cluster.x-k8s.io/cluster-name: my-cluster
cluster.x-k8s.io/control-plane: "true"
set: controlplane
spec:
bootstrap:
configRef:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
name: my-control-plane1-config
infrastructureRef:
kind: DockerMachine
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
name: my-control-plane1-docker
version: "v1.19.1"
CABPK’s main responsibility is to convert a KubeadmConfig bootstrap object into a cloud-init script that is
going to turn a Machine into a Kubernetes Node using kubeadm.
The cloud-init script will be saved into a secret KubeadmConfig.Status.DataSecretName and then the infrastructure provider
(CAPD in this example) will pick up this value and proceed with the machine creation and the actual bootstrap.
The KubeadmConfig object allows full control of Kubeadm init/join operations by exposing raw InitConfiguration,
ClusterConfiguration and JoinConfiguration objects.
InitConfiguration and JoinConfiguration exposes Patches field which can be used to specify the patches from a directory,
this support is available from K8s 1.22 version onwards.
CABPK will fill in some values if they are left empty with sensible defaults:
KubeadmConfig fieldDefault
clusterConfiguration.KubernetesVersionMachine.Spec.Version[1]clusterConfiguration.clusterNameCluster.metadata.nameclusterConfiguration.controlPlaneEndpointCluster.status.apiEndpoints[0]clusterConfiguration.networking.dnsDomainCluster.spec.clusterNetwork.serviceDomainclusterConfiguration.networking.serviceSubnetCluster.spec.clusterNetwork.service.cidrBlocks[0]clusterConfiguration.networking.podSubnetCluster.spec.clusterNetwork.pods.cidrBlocks[0]joinConfiguration.discoverya short lived BootstrapToken generated by CABPK
IMPORTANT! overriding above defaults could lead to broken Clusters.
[1] if both clusterConfiguration.KubernetesVersion and Machine.Spec.Version are empty, the latest Kubernetes
version will be installed (as defined by the default kubeadm behavior).
Valid combinations of configuration objects are:
for KCP, InitConfiguration and ClusterConfiguration for the first control plane node; JoinConfiguration for additional control plane nodes
for machine deployments, JoinConfiguration for worker nodes
Bootstrap control plane node:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
metadata:
name: my-control-plane1-config
spec:
initConfiguration:
nodeRegistration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
Additional control plane nodes:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
metadata:
name: my-control-plane2-config
spec:
joinConfiguration:
nodeRegistration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
controlPlane: {}
worker nodes:
kind: KubeadmConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
metadata:
name: my-worker1-config
spec:
joinConfiguration:
nodeRegistration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
CABPK supports multiple control plane machines initing at the same time.
The generation of cloud-init scripts of different machines is orchestrated in order to ensure a cluster
bootstrap process that will be compliant with the correct Kubeadm init/join sequence. More in detail:
cloud-config-data generation starts only after Cluster.Status.InfrastructureReady flag is set to true.
at this stage, cloud-config-data will be generated for the first control plane machine only, keeping
on hold additional control plane machines existing in the cluster, if any (kubeadm init).
after the ControlPlaneInitialized conditions on the cluster object is set to true,
the cloud-config-data for all the other machines are generated (kubeadm join/join —control-plane).
The user can choose two approaches for certificate management:
provide required certificate authorities (CAs) to use for kubeadm init/kubeadm join --control-plane; such CAs
should be provided as a Secrets objects in the management cluster.
let KCP to generate the necessary Secrets objects with a self-signed certificate authority for kubeadm
See here for more info about certificate management with kubeadm.
The KubeadmConfig object supports customizing the content of the config-data. The following examples illustrate how to specify these options. They should be adapted to fit your environment and use case.
KubeadmConfig.Files specifies additional files to be created on the machine, either with content inline or by referencing a secret.
files:
- contentFrom:
secret:
key: node-cloud.json
name: ${CLUSTER_NAME}-md-0-cloud-json
owner: root:root
path: /etc/kubernetes/cloud.json
permissions: "0644"
- path: /etc/kubernetes/cloud.json
owner: "root:root"
permissions: "0644"
content: |
{
"cloud": "CustomCloud"
}
KubeadmConfig.PreKubeadmCommands specifies a list of commands to be executed before kubeadm init/join
preKubeadmCommands:
- hostname "{{ ds.meta_data.hostname }}"
- echo "{{ ds.meta_data.hostname }}" >/etc/hostname
KubeadmConfig.PostKubeadmCommands same as above, but after kubeadm init/join
postKubeadmCommands:
- echo "success" >/var/log/my-custom-file.log
KubeadmConfig.Users specifies a list of users to be created on the machine
users:
- name: capiuser
sshAuthorizedKeys:
- '${SSH_AUTHORIZED_KEY}'
sudo: ALL=(ALL) NOPASSWD:ALL
KubeadmConfig.NTP specifies NTP settings for the machine
ntp:
servers:
- IP_ADDRESS
enabled: true
KubeadmConfig.DiskSetup specifies options for the creation of partition tables and file systems on devices.
diskSetup:
filesystems:
- device: /dev/disk/azure/scsi1/lun0
extraOpts:
- -E
- lazy_itable_init=1,lazy_journal_init=1
filesystem: ext4
label: etcd_disk
- device: ephemeral0.1
filesystem: ext4
label: ephemeral0
replaceFS: ntfs
partitions:
- device: /dev/disk/azure/scsi1/lun0
layout: true
overwrite: false
tableType: gpt
KubeadmConfig.Mounts specifies a list of mount points to be setup.
mounts:
- - LABEL=etcd_disk
- /var/lib/etcddisk
KubeadmConfig.Verbosity specifies the kubeadm log level verbosity
verbosity: 10
KubeadmConfig.UseExperimentalRetryJoin replaces a basic kubeadm command with a shell script with retries for joins. This will add about 40KB to userdata.
useExperimentalRetryJoin: true
For more information on cloud-init options, see cloud config examples .
CAPBK has several ways to configure kubelet.
You can use KubeadmConfigSpec.files to put any files on nodes. This example puts a KubeletConfiguration file on nodes via KubeadmConfigSpec.files, and makes kubelet use it via KubeadmConfigSpec.kubeletExtraArgs. You can check available configurations of KubeletConfiguration on Kubelet Configuration (v1beta1) | Kubernetes .
This method is easy to replace the whole kubelet configuration generated by kubeadm, but it is not easy to replace only a part of the kubelet configuration.
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlaneTemplate
metadata:
name: cloudinit-control-plane
namespace: default
spec:
template:
spec:
kubeadmConfigSpec:
files:
# We put a KubeletConfiguration file on nodes via KubeadmConfigSpec.files
# In this example, we directly put the file content in the KubeadmConfigSpec.files.content field.
- path: /etc/kubernetes/kubelet/config.yaml
owner: "root:root"
permissions: "0644"
content: |
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
kubeReserved:
cpu: "1"
memory: "2Gi"
ephemeral-storage: "1Gi"
systemReserved:
cpu: "500m"
memory: "1Gi"
ephemeral-storage: "1Gi"
evictionHard:
memory.available: "500Mi"
nodefs.available: "10%"
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.128.0.10
clusterDomain: cluster.local
containerRuntimeEndpoint: ""
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
initConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Here we configure kubelet to use the KubeletConfiguration file we put on nodes via KubeadmConfigSpec.files
kubeletExtraArgs:
config: "/etc/kubernetes/kubelet/config.yaml"
joinConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Here we configure kubelet to use the KubeletConfiguration file we put on nodes via KubeadmConfigSpec.files
kubeletExtraArgs:
config: "/etc/kubernetes/kubelet/config.yaml"
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
metadata:
name: cloudinit-default-worker-bootstraptemplate
namespace: default
spec:
template:
spec:
files:
# We puts a KubeletConfiguration file on nodes via KubeadmConfigSpec.files
# In this example, we directly put the file content in the KubeadmConfigSpec.files.content field.
- path: /etc/kubernetes/kubelet/config.yaml
owner: "root:root"
permissions: "0644"
content: |
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
kubeReserved:
cpu: "1"
memory: "2Gi"
ephemeral-storage: "1Gi"
systemReserved:
cpu: "500m"
memory: "1Gi"
ephemeral-storage: "1Gi"
evictionHard:
memory.available: "500Mi"
nodefs.available: "10%"
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 0s
enabled: true
x509:
clientCAFile: /etc/kubernetes/pki/ca.crt
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 0s
cacheUnauthorizedTTL: 0s
cgroupDriver: systemd
clusterDNS:
- 10.128.0.10
clusterDomain: cluster.local
containerRuntimeEndpoint: ""
cpuManagerReconcilePeriod: 0s
evictionPressureTransitionPeriod: 0s
fileCheckFrequency: 0s
healthzBindAddress: 127.0.0.1
healthzPort: 10248
httpCheckFrequency: 0s
imageMinimumGCAge: 0s
logging:
flushFrequency: 0
options:
json:
infoBufferSize: "0"
verbosity: 0
memorySwap: {}
nodeStatusReportFrequency: 0s
nodeStatusUpdateFrequency: 0s
rotateCertificates: true
runtimeRequestTimeout: 0s
shutdownGracePeriod: 0s
shutdownGracePeriodCriticalPods: 0s
staticPodPath: /etc/kubernetes/manifests
streamingConnectionIdleTimeout: 0s
syncFrequency: 0s
volumeStatsAggPeriod: 0s
joinConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Here we configure kubelet to use the KubeletConfiguration file we put on nodes via KubeadmConfigSpec.files
kubeletExtraArgs:
config: "/etc/kubernetes/kubelet/config.yaml"
We can pass kubelet command-line flags via KubeadmConfigSpec.kubeletExtraArgs. This example is equivalent to setting --kube-reserved, --system-reserved, and --eviction-hard flags for the kubelet command.
This method is useful when you want to set kubelet flags that are not configurable via the KubeletConfiguration file, however, it is not recommended to use this method to set flags that are configurable via the KubeletConfiguration file.
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlaneTemplate
metadata:
name: kubelet-extra-args-control-plane
namespace: default
spec:
template:
spec:
kubeadmConfigSpec:
initConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Set kubelet flags via KubeadmConfigSpec.kubeletExtraArgs
kubeletExtraArgs:
kube-reserved: cpu=1,memory=2Gi,ephemeral-storage=1Gi
system-reserved: cpu=500m,memory=1Gi,ephemeral-storage=1Gi
eviction-hard: memory.available<500Mi,nodefs.available<10%
joinConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Set kubelet flags via KubeadmConfigSpec.kubeletExtraArgs
kubeletExtraArgs:
kube-reserved: cpu=1,memory=2Gi,ephemeral-storage=1Gi
system-reserved: cpu=500m,memory=1Gi,ephemeral-storage=1Gi
eviction-hard: memory.available<500Mi,nodefs.available<10%
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
metadata:
name: kubelet-extra-args-default-worker-bootstraptemplate
namespace: default
spec:
template:
spec:
joinConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Set kubelet flags via KubeadmConfigSpec.kubeletExtraArgs
kubeletExtraArgs:
kube-reserved: cpu=1,memory=2Gi,ephemeral-storage=1Gi
system-reserved: cpu=500m,memory=1Gi,ephemeral-storage=1Gi
eviction-hard: memory.available<500Mi,nodefs.available<10%
We can use kubeadm’s kubeletconfiguration patch target to patch the kubelet configuration file. In this example, we put a patch file for kubeletconfiguration target in strategic patchtype on nodes via KubeadmConfigSpec.files. For more details, see Customizing components with the kubeadm API | Kubernetes
This method is useful when you want to change the kubelet configuration file partially on specific nodes. For example, you can deploy a partially patched kubelet configuration file on specific nodes based on the default configuration used for kubeadm init or kubeadm join.
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlaneTemplate
metadata:
name: kubeadm-config-template-control-plane
namespace: default
spec:
template:
spec:
kubeadmConfigSpec:
files:
# Here we put a patch file for kubeletconfiguration target in strategic patchtype on nodes via KubeadmConfigSpec.files
# The naming convention of the patch file is kubeletconfiguration{suffix}+{patchtype}.json where {suffix} is an string and {patchtype} is one of the following: strategic, merge, json.
# {suffix} determines the order of the patch files. The patches are applied in the alpha-numerical order of the {suffix}.
- path: /etc/kubernetes/patches/kubeletconfiguration0+strategic.json
owner: "root:root"
permissions: "0644"
content: |
{
"apiVersion": "kubelet.config.k8s.io/v1beta1",
"kind": "KubeletConfiguration",
"kubeReserved": {
"cpu": "1",
"memory": "2Gi",
"ephemeral-storage": "1Gi",
},
"systemReserved": {
"cpu": "500m",
"memory": "1Gi",
"ephemeral-storage": "1Gi",
},
"evictionHard": {
"memory.available": "500Mi",
"nodefs.available": "10%",
},
}
initConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Here we specify the directory that contains the patch files
patches:
directory: /etc/kubernetes/patches
joinConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Here we specify the directory that contains the patch files
patches:
directory: /etc/kubernetes/patches
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
metadata:
name: kubeadm-config-template-default-worker-bootstraptemplate
namespace: default
spec:
template:
spec:
files:
# Here we put a patch file for kubeletconfiguration target in strategic patchtype on nodes via KubeadmConfigSpec.files
# The naming convention of the patch file is kubeletconfiguration{suffix}+{patchtype}.json where {suffix} is an string and {patchtype} is one of the following: strategic, merge, json.
# {suffix} determines the order of the patch files. The patches are applied in the alpha-numerical order of the {suffix}.
- path: /etc/kubernetes/patches/kubeletconfiguration0+strategic.json
owner: "root:root"
permissions: "0644"
content: |
{
"apiVersion": "kubelet.config.k8s.io/v1beta1",
"kind": "KubeletConfiguration",
"kubeReserved": {
"cpu": "1",
"memory": "2Gi",
"ephemeral-storage": "1Gi",
},
"systemReserved": {
"cpu": "500m",
"memory": "1Gi",
"ephemeral-storage": "1Gi",
},
"evictionHard": {
"memory.available": "500Mi",
"nodefs.available": "10%",
},
}
joinConfiguration:
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
# Here we specify the directory that contains the patch files
patches:
directory: /etc/kubernetes/patches
Cluster API bootstrap provider MicroK8s (CABPM) is a component responsible for generating a cloud-init script to turn a Machine into a Kubernetes Node. This implementation uses MicroK8s for Kubernetes bootstrap.
MicroK8s defines a MicroK8sControlPlane definition as well as the MachineDeployment to configure the control plane and worker nodes respectively. The MicroK8sControlPlane is linked in the cluster definition as shown in the following example:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
spec:
controlPlaneRef:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: MicroK8sControlPlane
name: capi-aws-control-plane
A control plane manifest section includes the Kubernetes version, the replica number as well as the MicroK8sConfig:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: MicroK8sControlPlane
spec:
controlPlaneConfig:
initConfiguration:
addons:
- dns
- ingress
replicas: 3
version: v1.23.0
......
The worker nodes are configured through the MachineDeployment object:
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineDeployment
metadata:
name: capi-aws-md-0
namespace: default
spec:
clusterName: capi-aws
replicas: 2
selector:
matchLabels: null
template:
spec:
clusterName: capi-aws
version: v1.23.0
bootstrap:
configRef:
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: MicroK8sConfigTemplate
name: capi-aws-md-0
......
---
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: MicroK8sConfigTemplate
metadata:
name: capi-aws-md-0
namespace: default
spec:
template:
spec: {}
In both the MicroK8sControlPlane and MicroK8sConfigTemplate you can set a MicroK8sConfig object. In the MicroK8sControlPlane case MicroK8sConfig is under MicroK8sConfig.spec.controlPlaneConfig whereas in MicroK8sConfigTemplate it is under MicroK8sConfigTemplate.spec.template.spec.
Some of the configuration options available via MicroK8sConfig are:
MicroK8sConfig.spec.initConfiguration.joinTokenTTLInSecs: the time-to-live (TTL) of the token used to join nodes, defaults to 10 years.MicroK8sConfig.spec.initConfiguration.httpsProxy: the https proxy to be used, defaults to none.MicroK8sConfig.spec.initConfiguration.httpProxy: the http proxy to be used, defaults to none.MicroK8sConfig.spec.initConfiguration.noProxy: the no-proxy to be used, defaults to none.MicroK8sConfig.spec.initConfiguration.addons: the list of addons to be enabled, defaults to dns.MicroK8sConfig.spec.clusterConfiguration.portCompatibilityRemap: option to reuse the security group ports set for kubeadm, defaults to true.
The main purpose of the MicroK8s bootstrap provider is to translate the users needs to a number of cloud-init files applicable for each type of cluster nodes. There are three types of cloud-inits:
The first node cloud-init. That node will be a control plane node and will be the one where the addons are enabled.
The control plane node cloud-init. The control plane nodes need to join a cluster and contribute to its HA.
The worker node cloud-init. These nodes join the cluster as workers.
The cloud-init scripts are saved as secrets that then the infrastructure provider uses during the machine creation. For more information on cloud-init options, see cloud config examples .
If you are upgrading the version of Kubernetes for a cluster managed by Cluster API, check that the running version of
Cluster API on the Management Cluster supports the target Kubernetes version .
You may need to upgrade the version of Cluster API in order to support the target
Kubernetes version.
In addition, you must always upgrade between Kubernetes minor versions in sequence, e.g. if you need to upgrade from
Kubernetes v1.17 to v1.19, you must first upgrade to v1.18.
For kubeadm based clusters, infrastructure providers require a “machine image” containing pre-installed, matching
versions of kubeadm and kubelet, ensure that relevant infrastructure machine templates reference the appropriate
image for the Kubernetes version.
The high level steps to fully upgrading a cluster are to first upgrade the control plane and then upgrade
the worker machines.
To upgrade the control plane machines underlying machine images, the MachineTemplate resource referenced by the
KubeadmControlPlane must be changed. Since MachineTemplate resources are immutable, the recommended approach is to
Copy the existing MachineTemplate.
Modify the values that need changing, such as instance type or image ID.
Create the new MachineTemplate on the management cluster.
Modify the existing KubeadmControlPlane resource to reference the new MachineTemplate resource in the infrastructureRef field.
The next step will trigger a rolling update of the control plane using the new values found in the new MachineTemplate.
To upgrade the Kubernetes control plane version make a modification to the KubeadmControlPlane resource’s Spec.Version field. This will trigger a rolling upgrade of the control plane and, depending on the provider, also upgrade the underlying machine image.
Some infrastructure providers, such as AWS , require
that if a specific machine image is specified, it has to match the Kubernetes version specified in the
KubeadmControlPlane spec. In order to only trigger a single upgrade, the new MachineTemplate should be created first
and then both the Version and InfrastructureTemplate should be modified in a single transaction.
The KubeadmControlPlane and MachineDepoyment resources have a field RolloutAfter that can be
set to a timestamp (RFC-3339) after which a rollout should be triggered regardless of whether there
were any changes to KubeadmControlPlane.Spec/MachineDeployment.Spec.Template or not. This would
roll out replacement nodes which can be useful e.g. to perform certificate rotation, reflect changes
to machine templates, move to new machines, etc.
Note that this field can only be used for triggering a rollout, not for delaying one. Specifically,
a rollout can also happen before the time specified in RolloutAfter if any changes are made to
the spec before that time.
The rollout can be triggered by running the following command:
# Trigger a KubeadmControlPlane rollout.
clusterctl alpha rollout restart kubeadmcontrolplane/my-kcp
# Trigger a MachineDeployment rollout.
clusterctl alpha rollout restart machinedeployment/my-md-0
Upgrades are not limited to just the control plane. This section is not related to Kubeadm control plane specifically,
but is the final step in fully upgrading a Cluster API managed cluster.
It is recommended to manage machines with one or more MachineDeployments. MachineDeployments will
transparently manage MachineSets and Machines to allow for a seamless scaling experience. A modification to the
MachineDeployments spec will begin a rolling update of the machines. Follow
these instructions for changing the
template for an existing MachineDeployment.
MachineDeployments support different strategies for rolling out changes to Machines:
Changes are rolled out by honouring MaxUnavailable and MaxSurge values.
Only values allowed are of type Int or Strings with an integer and percentage symbol e.g “5%”.
Changes are rolled out driven by the user or any entity deleting the old Machines. Only when a Machine is fully deleted a new one will come up.
For a more in-depth look at how MachineDeployments manage scaling events, take a look at the MachineDeployment
controller documentationMachineSet controller
documentation
Cluster API Bootstrap Provider Kubeadm supports using an external etcd cluster for your workload Kubernetes clusters.
Before getting started you should be aware of the expectations that come with using an external etcd cluster.
Cluster API is unable to manage any aspect of the external etcd cluster.
Depending on how you configure your etcd nodes you may incur additional cloud costs in data transfer.
As an example, cross availability zone traffic can cost money on cloud providers. You don’t have to deploy etcd across availability zones, but if you do please be aware of the costs.
To use this, you will need to create an etcd cluster and generate an apiserver-etcd-client certificate and private key. This behaviour can be tested using kubeadmetcdadm
CA certificates are required to setup etcd cluster. If you already have a CA then the CA’s crt and key must be copied to /etc/kubernetes/pki/etcd/ca.crt and /etc/kubernetes/pki/etcd/ca.key.
If you do not already have a CA then run command kubeadm init phase certs etcd-ca. This creates two files:
/etc/kubernetes/pki/etcd/ca.crt/etc/kubernetes/pki/etcd/ca.key
This certificate and private key are used to sign etcd server and peer certificates as well as other client certificates (like the apiserver-etcd-client certificate or the etcd-healthcheck-client certificate). More information on how to setup external etcd with kubeadm can be found here .
Once the etcd cluster is setup, you will need the following files from the etcd cluster:
/etc/kubernetes/pki/apiserver-etcd-client.crt and /etc/kubernetes/pki/apiserver-etcd-client.key/etc/kubernetes/pki/etcd/ca.crt
You’ll use these files to create the necessary Secrets on the management cluster (see the “Creating the required Secrets” section).
etcdadm creates the CA if one does not exist, uses it to sign its server and peer certificates, and finally to sign the API server etcd client certificate. The CA’s crt and key generated using etcdadm are stored in /etc/etcd/pki/ca.crt and /etc/etcd/pki/ca.key. etcdadm also generates a certificate for the API server etcd client; the certificate and private key are found at /etc/etcd/pki/apiserver-etcd-client.crt and /etc/etcd/pki/apiserver-etcd-client.key, respectively.
Once the etcd cluster has been bootstrapped using etcdadm, you will need the following files from the etcd cluster:
/etc/etcd/pki/apiserver-etcd-client.crt and /etc/etcd/pki/apiserver-etcd-client.key/etc/etcd/pki/etcd/ca.crt
You’ll use these files in the next section to create the necessary Secrets on the management cluster.
Regardless of the method used to bootstrap the etcd cluster, you will need to use the certificates copied from the etcd cluster to create some Kubernetes Secrets on the management cluster.
In the commands below to create the Secrets, substitute $CLUSTER_NAME with the name of the workload cluster to be created by CAPI, and substitute $CLUSTER_NAMESPACE with the name of the namespace where the workload cluster will be created. The namespace can be omitted if the workload cluster will be created in the default namespace.
First, you will need to create a Secret containing the API server etcd client certificate and key. This command assumes the certificate and private key are in the current directory; adjust your command accordingly if they are not:
# Kubernetes API server etcd client certificate and key
kubectl create secret tls $CLUSTER_NAME-apiserver-etcd-client \
--cert apiserver-etcd-client.crt \
--key apiserver-etcd-client.key \
--namespace $CLUSTER_NAMESPACE
Next, create a Secret for the etcd cluster’s CA certificate. The kubectl create secret tls command requires both a certificate and a key, but the key isn’t needed by CAPI. Instead, use the kubectl create secret generic command, and note that the file containing the CA certificate must be named tls.crt:
# Etcd's CA crt file to validate the generated client certificates
kubectl create secret generic $CLUSTER_NAME-etcd \
--from-file tls.crt \
--namespace $CLUSTER_NAMESPACE
Note: The above commands will base64 encode the certificate/key files by default.
Alternatively you can base64 encode the files and put them in two secrets. The secrets must be formatted as follows and the cert material must be base64 encoded:
# Kubernetes APIServer etcd client certificate
kind: Secret
apiVersion: v1
metadata:
name: $CLUSTER_NAME-apiserver-etcd-client
namespace: $CLUSTER_NAMESPACE
data:
tls.crt: |
LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURCRENDQWV5Z0F3SUJBZ0lJZFlkclZUMzV0
NW93RFFZSktvWklodmNOQVFFTEJRQXdEekVOTUFzR0ExVUUKQXhNRVpYUmpaREFlRncweE9UQTVN
...
tls.key: |
LS0tLS1CRUdJTiBSU0EgUFJJVkFURSBLRVktLS0tLQpNSUlFb3dJQkFBS0NBUUVBdlFlTzVKOE5j
VCtDeGRubFR3alpuQ3YwRzByY0tETklhZzlSdFdrZ1p4MEcxVm1yClA4Zy9BRkhXVHdxSTUrNi81
...
# Etcd's CA crt file to validate the generated client certificates
kind: Secret
apiVersion: v1
metadata:
name: $CLUSTER_NAME-etcd
namespace: $CLUSTER_NAMESPACE
data:
tls.crt: |
LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURBRENDQWVpZ0F3SUJBZ0lJRDNrVVczaDIy
K013RFFZSktvWklodmNOQVFFTEJRQXdEekVOTUFzR0ExVUUKQXhNRVpYUmpaREFlRncweE9UQTVN
...
The Secrets must be created before creating the workload cluster.
Once the Secrets are in place on the management cluster, the rest of the process leverages standard kubeadm configuration. Configure your ClusterConfiguration for the workload cluster as follows:
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
kind: KubeadmConfig
metadata:
name: CLUSTER_NAME-controlplane-0
namespace: CLUSTER_NAMESPACE
spec:
... # initConfiguration goes here
clusterConfiguration:
etcd:
external:
endpoints:
- https://10.0.0.230:2379
caFile: /etc/kubernetes/pki/etcd/ca.crt
certFile: /etc/kubernetes/pki/apiserver-etcd-client.crt
keyFile: /etc/kubernetes/pki/apiserver-etcd-client.key
... # other clusterConfiguration goes here
Create your workload cluster as normal. The new workload cluster should use the configured external etcd nodes instead of creating co-located etcd Pods on the control plane nodes.
Depending on the provider, additional changes to the workload cluster’s manifest may be necessary to ensure the new CAPI-managed nodes have connectivity to the existing etcd nodes. For example, on AWS you will need to leverage the additionalSecurityGroups field on the AWSMachine and/or AWSMachineTemplate objects to add the CAPI-managed nodes to a security group that has connectivity to the existing etcd cluster. Other mechanisms exist for other providers.
Although the clusterctl generate cluster command exposes a number of different configuration values
for customizing workload cluster YAML manifests, some users may need additional flexibility above
and beyond what clusterctl generate cluster or the example “flavor” templates that some CAPI providers
supply (as an example, see these flavor templates
for the Cluster API Provider for Azure). In the future, a templating solution
may be integrated into clusterctl to help address this need, but in the meantime users can use
kustomize as a solution to this need.
This document provides a few examples of using kustomize with Cluster API. All of these examples
assume that you are using a directory structure that looks something like this:
.
├── base
│ ├── base.yaml
│ └── kustomization.yaml
└── overlays
├── custom-ami
│ ├── custom-ami.json
│ └── kustomization.yaml
└── mhc
├── kustomization.yaml
└── workload-mhc.yaml
In the overlay directories, the “base” (unmodified) Cluster API configuration (perhaps generated using
clusterctl generate cluster) would be referenced as a resource in kustomization.yaml using ../../base.
Users can use kustomize to specify custom OS images for Cluster API nodes. Using the Cluster API
Provider for AWS (CAPA) as an example, the following kustomization.yaml would leverage a JSON 6902 patch
to modify the AMI for nodes in a workload cluster:
---
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- ../../base
patchesJson6902:
- path: custom-ami.json
target:
group: infrastructure.cluster.x-k8s.io
kind: AWSMachineTemplate
name: ".*"
version: v1alpha3
The referenced JSON 6902 patch in custom-ami.json would look something like this:
[
{ "op": "add", "path": "/spec/template/spec/ami", "value": "ami-042db61632f72f145"}
]
This configuration assumes that the workload cluster only uses MachineDeployments. Since
MachineDeployments and the KubeadmControlPlane both leverage AWSMachineTemplates, this kustomize
configuration would catch all nodes in the workload cluster.
Users could also use kustomize to combine additional resources, like a MachineHealthCheck (MHC), with the
base Cluster API manifest. In an overlay directory, specify the following in kustomization.yaml:
---
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- ../../base
- workload-mhc.yaml
The content of the workload-mhc.yaml file would be the definition of a standard MHC:
apiVersion: cluster.x-k8s.io/v1alpha3
kind: MachineHealthCheck
metadata:
name: md-0-mhc
spec:
clusterName: test
# maxUnhealthy: 40%
nodeStartupTimeout: 10m
selector:
matchLabels:
cluster.x-k8s.io/deployment-name: md-0
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
You would want to ensure the clusterName field in the MachineHealthCheck manifest appropriately
matches the name of the workload cluster, taking into account any transformations you may have specified
in kustomization.yaml (like the use of “namePrefix” or “nameSuffix”).
Running kustomize build . with this configuration would append the MHC to the base
Cluster API manifest, thus creating the MHC at the same time as the workload cluster.
The kustomize “namePrefix” and “nameSuffix” transformers are not currently “Cluster API aware.”
Although it is possible to use these transformers with Cluster API manifests, doing so requires separate
patches for Clusters versus infrastructure-specific equivalents (like an AzureCluster or a vSphereCluster).
This can significantly increase the complexity of using kustomize for this use case.
Modifying the transformer configurations for kustomize can make it more effective with Cluster API.
For example, changes to the nameReference transformer in kustomize will enable kustomize to know
about the references between Cluster API objects in a manifest. See
here for more
information on transformer configurations.
Add the following content to the namereference.yaml transformer configuration:
- kind: Cluster
group: cluster.x-k8s.io
version: v1alpha3
fieldSpecs:
- path: spec/clusterName
kind: MachineDeployment
- path: spec/template/spec/clusterName
kind: MachineDeployment
- kind: AWSCluster
group: infrastructure.cluster.x-k8s.io
version: v1alpha3
fieldSpecs:
- path: spec/infrastructureRef/name
kind: Cluster
- kind: KubeadmControlPlane
group: controlplane.cluster.x-k8s.io
version: v1alpha3
fieldSpecs:
- path: spec/controlPlaneRef/name
kind: Cluster
- kind: AWSMachine
group: infrastructure.cluster.x-k8s.io
version: v1alpha3
fieldSpecs:
- path: spec/infrastructureRef/name
kind: Machine
- kind: KubeadmConfig
group: bootstrap.cluster.x-k8s.io
version: v1alpha3
fieldSpecs:
- path: spec/bootstrap/configRef/name
kind: Machine
- kind: AWSMachineTemplate
group: infrastructure.cluster.x-k8s.io
version: v1alpha3
fieldSpecs:
- path: spec/template/spec/infrastructureRef/name
kind: MachineDeployment
- path: spec/infrastructureTemplate/name
kind: KubeadmControlPlane
- kind: KubeadmConfigTemplate
group: bootstrap.cluster.x-k8s.io
version: v1alpha3
fieldSpecs:
- path: spec/template/spec/bootstrap/configRef/name
kind: MachineDeployment
Including this custom configuration in a kustomization.yaml would then enable the use of simple
“namePrefix” and/or “nameSuffix” directives, like this:
---
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- ../../base
configurations:
- namereference.yaml
namePrefix: "blue-"
nameSuffix: "-dev"
Running kustomize build. with this configuration would modify the name of all the Cluster API
objects and the associated referenced objects, adding “blue-” at the beginning and appending “-dev”
at the end.
In general, it’s recommended to upgrade to the latest version of Cluster API to take advantage of bug fixes, new
features and improvements.
If moving between different API versions, there may be additional tasks that you need to complete. See below for
detailed instructions.
Ensure that the version of Cluster API is compatible with the Kubernetes version of the management cluster.
Use clusterctl to upgrade between versions of Cluster API 1.0.x .
This section provides details about control plane providers.
Using the Kubeadm control plane type to manage a control plane provides several ways to upgrade control plane machines.
KCP will generate and manage the admin Kubeconfig for clusters. The client certificate for the admin user is created
with a valid lifespan of a year, and will be automatically regenerated when the cluster is reconciled and has less than
6 months of validity remaining.
See the section on upgrading clusters .
We don’t suggest running workloads on control planes, and highly encourage avoiding it unless absolutely necessary.
However, in the case the user wants to run non-control plane workloads on control plane machines they
are ultimately responsible for ensuring the proper functioning of those workloads, given that KCP is not
aware of the specific requirements for each type of workload (e.g. preserving quorum, shutdown procedures etc.).
In order to do so, the user could leverage on the same assumption that applies to all the
Cluster API Machines:
The Kubernetes node hosted on the Machine will be cordoned & drained before removal (with well
known exceptions like full Cluster deletion).
The Machine will respect PreDrainDeleteHook and PreTerminateDeleteHook. see the
Machine Deletion Phase Hooks proposal
for additional details.
Changes to the following fields of KubeadmControlPlane are propagated in-place to the Machines and do not trigger a full rollout:
.spec.machineTemplate.metadata.labels.spec.machineTemplate.metadata.annotations.spec.nodeDrainTimeout.spec.nodeDeletionTimeout.spec.nodeVolumeDetachTimeout
Changes to the following fields of KubeadmControlPlane are propagated in-place to the InfrastructureMachine and KubeadmConfig:
.spec.machineTemplate.metadata.labels.spec.machineTemplate.metadata.annotations
Note: Changes to these fields will not be propagated to Machines, InfraMachines and KubeadmConfigs that are marked for deletion (example: because of scale down).
Cluster API MicroK8s control plane provider (CACPM) is a component responsible for managing the control plane of the provisioned clusters. This implementation uses MicroK8s for cluster provisioning and management.
Currently the CACPM does not expose any functionality. It serves however the following purposes:
Sets the ProviderID on the provisioned nodes. MicroK8s will not set the provider ID automatically so the control plane provider identifies the VMs’ provider IDs and updates the respective machine objects.
Updates the machine state.
Generates and provisions the kubeconfig file used for accessing the cluster. The kubeconfig file is stored as a secret and the user can retrieve via clusterctl.
Several different components of Cluster API leverage infrastructure machine templates ,
including KubeadmControlPlane, MachineDeployment, and MachineSet. These
MachineTemplate resources should be immutable, unless the infrastructure provider
documentation indicates otherwise for certain fields (see below for more details).
The correct process for modifying an infrastructure machine template is as follows:
Duplicate an existing template.
Users can use kubectl get <MachineTemplateType> <name> -o yaml > file.yaml
to retrieve a template configuration from a running cluster to serve as a starting
point.
Update the desired fields.
Fields that might need to be modified could include the SSH key, the AWS instance
type, or the Azure VM size. Refer to the provider-specific documentation
for more details on the specific fields that each provider requires or accepts.
Give the newly-modified template a new name by modifying the metadata.name field
(or by using metadata.generateName).
Create the new infrastructure machine template on the API server using kubectl.
(If the template was initially created using the command in step 1, be sure to clear
out any extraneous metadata, including the resourceVersion field, before trying to
send it to the API server.)
Once the new infrastructure machine template has been persisted, users may modify
the object that was referencing the infrastructure machine template. For example,
to modify the infrastructure machine template for the KubeadmControlPlane object,
users would modify the spec.infrastructureTemplate.name field. For a MachineDeployment, users would need to modify the spec.template.spec.infrastructureRef.name
field and the controller would orchestrate the upgrade by managing MachineSets pointing to the new and old references. In the case of a MachineSet with no MachineDeployment owner, if its template reference is changed, it will only affect upcoming Machines.
In all cases, the name field should be updated to point to the newly-modified
infrastructure machine template. This will trigger a rolling update. (This same process
is described in the documentation for upgrading the underlying machine image for
KubeadmControlPlane in the “How to upgrade the underlying
machine image” section.)
Some infrastructure providers may , at their discretion, choose to support in-place
modifications of certain infrastructure machine template fields. This may be useful
if an infrastructure provider is able to make changes to running instances/machines,
such as updating allocated memory or CPU capacity. In such cases, however, Cluster
API will not trigger a rolling update.
Several different components of Cluster API leverage bootstrap templates ,
including MachineDeployment, and MachineSet. When used in MachineDeployment or
MachineSet changes to those templates do not trigger rollouts of already existing Machines.
New Machines are created based on the current version of the bootstrap template.
The correct process for modifying a bootstrap template is as follows:
Duplicate an existing template.
Users can use kubectl get <BootstrapTemplateType> <name> -o yaml > file.yaml
to retrieve a template configuration from a running cluster to serve as a starting
point.
Update the desired fields.
Give the newly-modified template a new name by modifying the metadata.name field
(or by using metadata.generateName).
Create the new bootstrap template on the API server using kubectl.
(If the template was initially created using the command in step 1, be sure to clear
out any extraneous metadata, including the resourceVersion field, before trying to
send it to the API server.)
Once the new bootstrap template has been persisted, users may modify
the object that was referencing the bootstrap template. For example,
to modify the bootstrap template for the MachineDeployment object,
users would modify the spec.template.spec.bootstrap.configRef.name field.
The name field should be updated to point to the newly-modified
bootstrap template. This will trigger a rolling update.
Cluster API can be utilized in combination with the Cluster API addon provider for helm (CAAPH) to install and configure a GitOps agent and then the GitOps agent hydrates clusters automatically with various workloads.
Follow the quickstart setup guide for your provider but ensure that CAAPH is installed via including the addon=helm with either:
clusterctl using clusterctl init --infrastructure ### --addon helm orCluster API Operator using helm install capi-operator capi-operator/cluster-api-operator ... --set infrastructure=#### --set addon=helm
Add the labels argoCDChart: enabled and guestbook: enabled to your desired workload cluster yaml file in the Cluster metadata section, for example:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: my-cluster
namespace: default
labels:
argoCDChart: enabled
guestbook: enabled
Then create and kubectl apply -f the following file on the management cluster to install the ArgoCD agent and the sample guestbook app to the workload cluster via the argo helm charts using CAAPH:
apiVersion: addons.cluster.x-k8s.io/v1alpha1
kind: HelmChartProxy
metadata:
name: argocd
spec:
clusterSelector:
matchLabels:
argoCDChart: enabled
repoURL: https://argoproj.github.io/argo-helm
chartName: argo-cd
options:
waitForJobs: true
wait: true
timeout: 5m
install:
createNamespace: true
---
apiVersion: addons.cluster.x-k8s.io/v1alpha1
kind: HelmChartProxy
metadata:
name: argocdguestbook
spec:
clusterSelector:
matchLabels:
guestbook: enabled
repoURL: https://argoproj.github.io/argo-helm
chartName: argocd-apps
options:
waitForJobs: true
wait: true
timeout: 5m
install:
createNamespace: true
valuesTemplate: |
applications:
- name: guestbook
namespace: argocd
finalizers:
- resources-finalizer.argocd.argoproj.io
project: default
sources:
- repoURL: https://github.com/argoproj/argocd-example-apps.git
path: guestbook
targetRevision: HEAD
destination:
server: https://kubernetes.default.svc
namespace: guestbook
syncPolicy:
automated:
prune: false
selfHeal: false
syncOptions:
- CreateNamespace=true
revisionHistoryLimit: null
ignoreDifferences:
- group: apps
kind: Deployment
jsonPointers:
- /spec/replicas
info:
- name: url
value: https://argoproj.github.io/
This will automatically install ArgoCD in the ArgoCD namespace and the guestbook application into the guestbook namespace. Adding or labeling additional clusters with argoCDChart: enabled and guestbook: enabled will automatically install the ArgoCD agent and the guestbook application and there is no need to create additional CAAPH HelmChartProxy entries.
The ArgoCD console can be viewed by connecting to the workload cluster and then doing the following:
# Get the admin password
kubectl get secrets argocd-initial-admin-secret -n argocd --template="{{index .data.password | base64decode}}"
kubectl port-forward service/capiargo-argocd-server -n default 8080:443
# and then open the browser on http://localhost:8080 and accept the certificate
The Guestbook application deployment can be seen once logged into the ArgoCD console. Since the GitOps agent points to the git repository, any changes to the repository will automatically update the workload cluster. The git repository could be configured to utilize the App of Apps pattern to install all platform requirements for the cluster. The App of Apps pattern is a single application that installs all other applications and configurations for the cluster.
This same pattern could also utilize the Flux agent using the Flux helm charts being installed and configured by CAAPH.
This section details some tasks related to automated Machine management.
This section applies only to worker Machines. You can add or remove compute capacity for your cluster workloads by creating or removing Machines. A Machine expresses intent to have a Node with a defined form factor.
Machines can be owned by scalable resources i.e. MachineSet and MachineDeployments.
You can scale MachineSets and MachineDeployments in or out by expressing intent via .spec.replicas or updating the scale subresource e.g kubectl scale machinedeployment foo --replicas=5.
When you delete a Machine directly or by scaling down, the same process takes place in the same order:
The Node backed by that Machine will try to be drained indefinitely and will wait for any volume to be detached from the Node unless you specify a .spec.nodeDrainTimeout.
CAPI uses default kubectl draining implementation with -–ignore-daemonsets=true. If you needed to ensure DaemonSets eviction you’d need to do so manually by also adding proper taints to avoid rescheduling.
The infrastructure backing that Node will try to be deleted indefinitely.
Only when the infrastructure is gone, the Node will try to be deleted indefinitely unless you specify .spec.nodeDeletionTimeout.
This section applies only to worker Machines. Cluster Autoscaler is a tool that automatically adjusts the size of the Kubernetes cluster based
on the utilization of Pods and Nodes in your cluster. For more general information about the
Cluster Autoscaler, please see the
project documentation .
The following instructions are a reproduction of the Cluster API provider specific documentation
from the Autoscaler project documentation .
The cluster autoscaler on Cluster API uses
the cluster-api project to
manage the provisioning and de-provisioning of nodes within a Kubernetes
cluster.
The cluster-api provider requires Kubernetes v1.16 or greater to run the
v1alpha3 version of the API.
To enable the Cluster API provider, you must first specify it in the command
line arguments to the cluster autoscaler binary. For example:
cluster-autoscaler --cloud-provider=clusterapi
Please note, this example only shows the cloud provider options, you will
most likely need other command line flags. For more information you can invoke
cluster-autoscaler --help to see a full list of options.
You must configure node group auto discovery to inform cluster autoscaler which cluster in which to find for scalable node groups.
Limiting cluster autoscaler to only match against resources in the blue namespace
--node-group-auto-discovery=clusterapi:namespace=blue
Limiting cluster autoscaler to only match against resources belonging to Cluster test1
--node-group-auto-discovery=clusterapi:clusterName=test1
Limiting cluster autoscaler to only match against resources matching the provided labels
--node-group-auto-discovery=clusterapi:color=green,shape=square
These can be mixed and matched in any combination, for example to only match resources
in the staging namespace, belonging to the purple cluster, with the label owner=jim:
--node-group-auto-discovery=clusterapi:namespace=staging,clusterName=purple,owner=jim
You will also need to provide the path to the kubeconfig(s) for the management
and workload cluster you wish cluster-autoscaler to run against. To specify the
kubeconfig path for the workload cluster to monitor, use the --kubeconfig
option and supply the path to the kubeconfig. If the --kubeconfig option is
not specified, cluster-autoscaler will attempt to use an in-cluster configuration.
To specify the kubeconfig path for the management cluster to monitor, use the
--cloud-config option and supply the path to the kubeconfig. If the
--cloud-config option is not specified it will fall back to using the kubeconfig
that was provided with the --kubeconfig option.
+-----------------+
| mgmt / workload |
| --------------- |
| autoscaler |
+-----------------+
Use in-cluster config for both management and workload cluster:
cluster-autoscaler --cloud-provider=clusterapi
+--------+ +------------+
| mgmt | | workload |
| | cloud-config | ---------- |
| |<-------------+ autoscaler |
+--------+ +------------+
Use in-cluster config for workload cluster, specify kubeconfig for management cluster:
cluster-autoscaler --cloud-provider=clusterapi \
--cloud-config=/mnt/kubeconfig
+------------+ +----------+
| mgmt | | workload |
| ---------- | kubeconfig | |
| autoscaler +------------>| |
+------------+ +----------+
Use in-cluster config for management cluster, specify kubeconfig for workload cluster:
cluster-autoscaler --cloud-provider=clusterapi \
--kubeconfig=/mnt/kubeconfig \
--clusterapi-cloud-config-authoritative
+--------+ +------------+ +----------+
| mgmt | | ? | | workload |
| | cloud-config | ---------- | kubeconfig | |
| |<--------------+ autoscaler +------------>| |
+--------+ +------------+ +----------+
Use separate kubeconfigs for both management and workload cluster:
cluster-autoscaler --cloud-provider=clusterapi \
--kubeconfig=/mnt/workload.kubeconfig \
--cloud-config=/mnt/management.kubeconfig
+---------------+ +------------+
| mgmt/workload | | ? |
| | kubeconfig | ---------- |
| |<------------+ autoscaler |
+---------------+ +------------+
Use a single provided kubeconfig for both management and workload cluster:
cluster-autoscaler --cloud-provider=clusterapi \
--kubeconfig=/mnt/workload.kubeconfig
To enable the automatic scaling of components in your cluster-api managed
cloud there are a few annotations you need to provide. These annotations
must be applied to either MachineSet , MachineDeployment , or MachinePool
resources depending on the type of cluster-api mechanism that you are using.
There are two annotations that control how a cluster resource should be scaled:
cluster.x-k8s.io/cluster-api-autoscaler-node-group-min-size - This specifies
the minimum number of nodes for the associated resource group. The autoscaler
will not scale the group below this number. Please note that the cluster-api
provider will not scale down to, or from, zero unless that capability is enabled
(see Scale from zero support ).
cluster.x-k8s.io/cluster-api-autoscaler-node-group-max-size - This specifies
the maximum number of nodes for the associated resource group. The autoscaler
will not scale the group above this number.
The autoscaler will monitor any MachineSet, MachineDeployment, or MachinePool containing
both of these annotations.
Note: MachinePool support in cluster-autoscaler requires a provider implementation
that supports the new “MachinePool Machines” feature. MachinePools in Cluster API are
considered an experimental feature and are not enabled by default.
The Cluster API community has defined an opt-in method for infrastructure
providers to enable scaling from zero-sized node groups in the
Opt-in Autoscaling from Zero enhancement .
As defined in the enhancement, each provider may add support for scaling from
zero to their provider, but they are not required to do so. If you are expecting
built-in support for scaling from zero, please check with the Cluster API
infrastructure providers that you are using.
If your Cluster API provider does not have support for scaling from zero, you
may still use this feature through the capacity annotations. You may add these
annotations to your MachineDeployments, or MachineSets if you are not using
MachineDeployments (it is not needed on both), to instruct the cluster
autoscaler about the sizing of the nodes in the node group. At the minimum,
you must specify the CPU and memory annotations, these annotations should
match the expected capacity of the nodes created from the infrastructure.
For example, if my MachineDeployment will create nodes that have “16000m” CPU,
“128G” memory, “100Gi” ephemeral disk storage, 2 NVidia GPUs, and can support
200 max pods, the following annotations will instruct the autoscaler how to
expand the node group from zero replicas:
apiVersion: cluster.x-k8s.io/v1alpha4
kind: MachineDeployment
metadata:
annotations:
cluster.x-k8s.io/cluster-api-autoscaler-node-group-max-size: "5"
cluster.x-k8s.io/cluster-api-autoscaler-node-group-min-size: "0"
capacity.cluster-autoscaler.kubernetes.io/memory: "128G"
capacity.cluster-autoscaler.kubernetes.io/cpu: "16"
capacity.cluster-autoscaler.kubernetes.io/ephemeral-disk: "100Gi"
capacity.cluster-autoscaler.kubernetes.io/gpu-type: "nvidia.com/gpu"
capacity.cluster-autoscaler.kubernetes.io/gpu-count: "2"
capacity.cluster-autoscaler.kubernetes.io/maxPods: "200"
Note the maxPods annotation will default to 110 if it is not supplied.
This value is inspired by the Kubernetes best practices
Considerations for large clusters .
If you are using the opt-in support for scaling from zero as defined by the
Cluster API infrastructure provider, you will need to add the infrastructure
machine template types to your role permissions for the service account
associated with the cluster autoscaler deployment. The service account will
need permission to get, list, and watch the infrastructure machine
templates for your infrastructure provider.
For example, when using the Kubemark provider
you will need to set the following permissions:
rules:
- apiGroups:
- infrastructure.cluster.x-k8s.io
resources:
- kubemarkmachinetemplates
verbs:
- get
- list
- watch
To provide labels or taint information for scale from zero, the optional
capacity annotations may be supplied as a comma separated list, as
demonstrated in the example below:
apiVersion: cluster.x-k8s.io/v1alpha4
kind: MachineDeployment
metadata:
annotations:
cluster.x-k8s.io/cluster-api-autoscaler-node-group-max-size: "5"
cluster.x-k8s.io/cluster-api-autoscaler-node-group-min-size: "0"
capacity.cluster-autoscaler.kubernetes.io/memory: "128G"
capacity.cluster-autoscaler.kubernetes.io/cpu: "16"
capacity.cluster-autoscaler.kubernetes.io/labels: "key1=value1,key2=value2"
capacity.cluster-autoscaler.kubernetes.io/taints: "key1=value1:NoSchedule,key2=value2:NoExecute"
Custom autoscaling options per node group (MachineDeployment/MachinePool/MachineSet) can be specified as annoations with a common prefix:
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineDeployment
metadata:
annotations:
# overrides --scale-down-utilization-threshold global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-scaledownutilizationthreshold: "0.5"
# overrides --scale-down-gpu-utilization-threshold global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-scaledowngpuutilizationthreshold: "0.5"
# overrides --scale-down-unneeded-time global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-scaledownunneededtime: "10m0s"
# overrides --scale-down-unready-time global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-scaledownunreadytime: "20m0s"
# overrides --max-node-provision-time global value for that specific MachineDeployment
cluster.x-k8s.io/autoscaling-options-maxnodeprovisiontime: "20m0s"
Users of single-arch non-amd64 clusters who are using scale from zero
support should also set the CAPI_SCALE_ZERO_DEFAULT_ARCH environment variable
to set the architecture of the nodes they want to default the node group templates to.
The autoscaler will default to amd64 if it is not set, and the node
group templates may not match the nodes’ architecture, specifically when
the workload triggering the scale-up uses a node affinity predicate checking
for the node’s architecture.
By default all Kubernetes resources consumed by the Cluster API provider will
use the group cluster.x-k8s.io, with a dynamically acquired version. In
some situations, such as testing or prototyping, you may wish to change this
group variable. For these situations you may use the environment variable
CAPI_GROUP to change the group that the provider will use.
Please note that setting the CAPI_GROUP environment variable will also cause the
annotations for minimum and maximum size to change.
This behavior will also affect the machine annotation on nodes, the machine deletion annotation,
and the cluster name label. For example, if CAPI_GROUP=test.k8s.io
then the minimum size annotation key will be test.k8s.io/cluster-api-autoscaler-node-group-min-size,
the machine annotation on nodes will be test.k8s.io/machine, the machine deletion
annotation will be test.k8s.io/delete-machine, and the cluster name label will be
test.k8s.io/cluster-name.
When determining the group version for the Cluster API types, by default the autoscaler
will look for the latest version of the group. For example, if MachineDeployments
exist in the cluster.x-k8s.io group at versions v1alpha1 and v1beta1, the
autoscaler will choose v1beta1.
In some cases it may be desirable to specify which version of the API the cluster
autoscaler should use. This can be useful in debugging scenarios, or in situations
where you have deployed multiple API versions and wish to ensure that the autoscaler
uses a specific version.
Setting the CAPI_VERSION environment variable will instruct the autoscaler to use
the version specified. This works in a similar fashion as the API group environment
variable with the exception that there is no default value. When this variable is not
set, the autoscaler will use the behavior described above.
A sample manifest
that will create a deployment running the autoscaler is
available. It can be deployed by passing it through envsubst, providing
these environment variables to set the namespace to deploy into as well as the image and tag to use:
export AUTOSCALER_NS=kube-system
export AUTOSCALER_IMAGE=registry.k8s.io/autoscaling/cluster-autoscaler:v1.29.0
envsubst < examples/deployment.yaml | kubectl apply -f-
The cluster-autoscaler-management role for accessing cluster api scalable resources is scoped to ClusterRole.
This may not be ideal for all environments (eg. Multi tenant environments).
In such cases, it is recommended to scope it to a Role mapped to a specific namespace.
For users using ClusterClass and Managed Topologies the Cluster Topology controller attempts to set MachineDeployment replicas based on the spec.topology.workers.machineDeployments[].replicas field. In order to use the Cluster Autoscaler this field can be left unset in the Cluster definition.
The below Cluster definition shows which field to leave unset:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: "my-cluster"
namespace: default
spec:
clusterNetwork:
services:
cidrBlocks: ["10.128.0.0/12"]
pods:
cidrBlocks: ["192.168.0.0/16"]
serviceDomain: "cluster.local"
topology:
class: "quick-start"
version: v1.24.0
controlPlane:
replicas: 1
workers:
machineDeployments:
- class: default-worker
name: linux
## replicas field is not set.
## replicas: 1
Warning : If the Autoscaler is enabled and the replicas field is set for a MachineDeployment or MachineSet the Cluster may enter a broken state where replicas become unpredictable.
If the replica field is unset in the Cluster definition Autoscaling can be enabled as described above
As with other providers, if the device plugin on nodes that provides GPU
resources takes some time to advertise the GPU resource to the cluster, this
may cause Cluster Autoscaler to unnecessarily scale out multiple times.
To avoid this, you can configure kubelet on your GPU nodes to label the node
before it joins the cluster by passing it the --node-labels flag. For the
CAPI cloudprovider, the label format is as follows:
cluster-api/accelerator=<gpu-type>
<gpu-type> is arbitrary.
It is important to note that if you are using the --gpu-total flag to limit the number
of GPU resources in your cluster that the <gpu-type> value must match
between the command line flag and the node labels. Setting these values incorrectly
can lead to the autoscaler creating too many GPU resources.
For example, if you are using the autoscaler command line flag
--gpu-total=gfx-hardware:1:2 to limit the number of gfx-hardware resources
to a minimum of 1 and maximum of 2, then you should use the kubelet node label flag
--node-labels=cluster-api/accelerator=gfx-hardware.
The Cluster Autoscaler feature to enable balancing similar node groups
(activated with the --balance-similar-node-groups flag) is a powerful and
popular feature. When enabled, the Cluster Autoscaler will attempt to create
new nodes by adding them in a manner that balances the creation between
similar node groups. With Cluster API, these node groups correspond directly
to the scalable resources associated (usually MachineDeployments and MachineSets)
with the nodes in question. In order for the nodes of these scalable resources
to be considered similar by the Cluster Autoscaler, they must have the same
capacity, labels, and taints for the nodes which will be created from them.
To help assist the Cluster Autoscaler in determining which node groups are
similar, the command line flags --balancing-ignore-label and
--balancing-label are provided. For an expanded discussion about balancing
similar node groups and the options which are available, please see the
Cluster Autoscaler FAQ .
Because Cluster API can address many different cloud providers, it is important
to configure the balancing labels to ignore provider-specific labels which
are used for carrying zonal information on Kubernetes nodes. The Cluster
Autoscaler implementation for Cluster API does not assume any labels (aside from
the well-known Kubernetes labels )
to be ignored when running. Users must configure their Cluster Autoscaler deployment
to ignore labels which might be different between nodes, but which do not
otherwise affect node behavior or size (for example when two MachineDeployments
are the same except for their deployment zones). The Cluster API community has
decided not to carry cloud provider specific labels in the Cluster Autoscaler
to reduce the possibility for labels to clash between providers. Additionally,
the community has agreed to promote documentation and the use of the --balancing-ignore-label
flag as the preferred method of deployment to reduce the extended need for
maintenance on the Cluster Autoscaler when new providers are added or updated.
For further context around this decision, please see the
Cluster API Deep Dive into Cluster Autoscaler Node Group Balancing discussion from 2022-09-12 .
The following table shows some of the most common labels used by cloud providers
to designate regional or zonal information on Kubernetes nodes. It is shared
here as a reference for users who might be deploying on these infrastructures.
Cloud Provider Label to ignore Notes
Alibaba Cloud topology.diskplugin.csi.alibabacloud.com/zoneUsed by the Alibaba Cloud CSI driver as a target for persistent volume node affinity AWS alpha.eksctl.io/instance-idUsed by eksctl to identify instances AWS alpha.eksctl.io/nodegroup-nameUsed by eksctl to identify node group names AWS eks.amazonaws.com/nodegroupUsed by EKS to identify node groups AWS k8s.amazonaws.com/eniConfigUsed by the AWS CNI for custom networking AWS lifecycleUsed by AWS as a label for spot instances AWS topology.ebs.csi.aws.com/zoneUsed by the AWS EBS CSI driver as a target for persistent volume node affinity Azure topology.disk.csi.azure.com/zoneUsed as the topology key by the Azure Disk CSI driver Azure agentpoolLegacy label used to specify to which Azure node pool a particular node belongs Azure kubernetes.azure.com/agentpoolUsed by AKS to identify to which node pool a particular node belongs GCE topology.gke.io/zoneUsed to specify the zone of the node IBM Cloud ibm-cloud.kubernetes.io/worker-idUsed by the IBM Cloud Cloud Controller Manager to identify the node IBM Cloud vpc-block-csi-driver-labelsUsed by the IBM Cloud CSI driver as a target for persistent volume node affinity IBM Cloud ibm-cloud.kubernetes.io/vpc-instance-idUsed when a VPC is in use on IBM Cloud
Please note that the MachineDeployment and MachineSet replicas field has special defaulting logic to provide a smooth integration with the autoscaler.
The replica field is defaulted based on the autoscaler min and max size annotations.The goal is to pick a default value which is inside
the (min size, max size) range so the autoscaler can take control of the replicase field.
The defaulting logic is as follows:
if the autoscaler min size and max size annotations are set:
if it’s a new MachineDeployment or MachineSet, use min size
if the replicas field of the old MachineDeployment or MachineSet is < min size, use min size
if the replicas field of the old MachineDeployment or MachineSet is > max size, use max size
if the replicas field of the old MachineDeployment or MachineSet is in the (min size, max size) range, keep the value from the oldMD or oldMS
otherwise, use 1
Before attempting to configure a MachineHealthCheck, you should have a working management cluster with at least one MachineDeployment or MachineSet deployed.
Please note that MachineHealthChecks currently only support Machines that are owned by a MachineSet or a KubeadmControlPlane.
Please review the Limitations and Caveats of a MachineHealthCheck
at the bottom of this page for full details of MachineHealthCheck limitations.
A MachineHealthCheck is a resource within the Cluster API which allows users to define conditions under which Machines within a Cluster should be considered unhealthy.
A MachineHealthCheck is defined on a management cluster and scoped to a particular workload cluster.
When defining a MachineHealthCheck, users specify a timeout for each of the conditions that they define to check on the Machine’s Node.
If any of these conditions are met for the duration of the timeout, the Machine will be remediated.
By default, the action of remediating a Machine should trigger a new Machine to be created to replace the failed one, but providers are allowed to plug in more sophisticated external remediation solutions.
Use the following example as a basis for creating a MachineHealthCheck for worker nodes:
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineHealthCheck
metadata:
name: capi-quickstart-node-unhealthy-5m
spec:
# clusterName is required to associate this MachineHealthCheck with a particular cluster
clusterName: capi-quickstart
# (Optional) maxUnhealthy prevents further remediation if the cluster is already partially unhealthy
maxUnhealthy: 40%
# (Optional) nodeStartupTimeout determines how long a MachineHealthCheck should wait for
# a Node to join the cluster, before considering a Machine unhealthy.
# Defaults to 10 minutes if not specified.
# Set to 0 to disable the node startup timeout.
# Disabling this timeout will prevent a Machine from being considered unhealthy when
# the Node it created has not yet registered with the cluster. This can be useful when
# Nodes take a long time to start up or when you only want condition based checks for
# Machine health.
nodeStartupTimeout: 10m
# selector is used to determine which Machines should be health checked
selector:
matchLabels:
nodepool: nodepool-0
# Conditions to check on Nodes for matched Machines, if any condition is matched for the duration of its timeout, the Machine is considered unhealthy
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
Use this example as the basis for defining a MachineHealthCheck for control plane nodes managed via
the KubeadmControlPlane:
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineHealthCheck
metadata:
name: capi-quickstart-kcp-unhealthy-5m
spec:
clusterName: capi-quickstart
maxUnhealthy: 100%
selector:
matchLabels:
cluster.x-k8s.io/control-plane: ""
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
If you are defining more than one MachineHealthCheck for the same Cluster, make sure that the selectors do not overlap
in order to prevent conflicts or unexpected behaviors when trying to remediate the same set of machines.
KubeadmControlPlane allows to control how remediation happen by defining an optional remediationStrategy;
this feature can be used for preventing unnecessary load on infrastructure provider e.g. in case of quota problems,or for allowing the infrastructure provider to stabilize in case of temporary problems.
apiVersion: cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlane
metadata:
name: my-control-plane
spec:
...
remediationStrategy:
maxRetry: 5
retryPeriod: 2m
minHealthyPeriod: 2h
maxRetry is the maximum number of retries while attempting to remediate an unhealthy machine.
A retry happens when a machine that was created as a replacement for an unhealthy machine also fails.
For example, given a control plane with three machines M1, M2, M3:
M1 become unhealthy; remediation happens, and M1-1 is created as a replacement.
If M1-1 (replacement of M1) has problems while bootstrapping it will become unhealthy, and then be
remediated. This operation is considered a retry - remediation-retry #1.
If M1-2 (replacement of M1-1) becomes unhealthy, remediation-retry #2 will happen, etc.
A retry will only happen after the retryPeriod from the previous retry has elapsed. If retryPeriod is not set (default), a retry will happen immediately.
If a machine is marked as unhealthy after minHealthyPeriod (default 1h) has passed since the previous remediation this is no longer considered a retry because the new issue is assumed unrelated from the previous one.
If maxRetry is not set (default), remediation will be retried infinitely.
To ensure that MachineHealthChecks only remediate Machines when the cluster is healthy,
short-circuiting is implemented to prevent further remediation via the maxUnhealthy and unhealthyRange fields within the MachineHealthCheck spec.
If the user defines a value for the maxUnhealthy field (either an absolute number or a percentage of the total Machines checked by this MachineHealthCheck),
before remediating any Machines, the MachineHealthCheck will compare the value of maxUnhealthy with the number of Machines it has determined to be unhealthy.
If the number of unhealthy Machines exceeds the limit set by maxUnhealthy, remediation will not be performed.
The default value for maxUnhealthy is 100%.
This means the short circuiting mechanism is disabled by default and Machines will be remediated no matter the state of the cluster.
If maxUnhealthy is set to 2:
If 2 or fewer nodes are unhealthy, remediation will be performed
If 3 or more nodes are unhealthy, remediation will not be performed
These values are independent of how many Machines are being checked by the MachineHealthCheck.
If maxUnhealthy is set to 40% and there are 25 Machines being checked:
If 10 or fewer nodes are unhealthy, remediation will be performed
If 11 or more nodes are unhealthy, remediation will not be performed
If maxUnhealthy is set to 40% and there are 6 Machines being checked:
If 2 or fewer nodes are unhealthy, remediation will be performed
If 3 or more nodes are unhealthy, remediation will not be performed
Note, when the percentage is not a whole number, the allowed number is rounded down.
If the user defines a value for the unhealthyRange field (bracketed values that specify a start and an end value), before remediating any Machines,
the MachineHealthCheck will check if the number of Machines it has determined to be unhealthy is within the range specified by unhealthyRange.
If it is not within the range set by unhealthyRange, remediation will not be performed.
If both maxUnhealthy and unhealthyRange are specified, unhealthyRange takes precedence.
If unhealthyRange is set to [3-5] and there are 10 Machines being checked:
If 2 or fewer nodes are unhealthy, remediation will not be performed.
If 6 or more nodes are unhealthy, remediation will not be performed.
In all other cases, remediation will be performed.
Note, the above example had 10 machines as sample set. But, this would work the same way for any other number.
This is useful for dynamically scaling clusters where the number of machines keep changing frequently.
There are scenarios where remediation for a machine may be undesirable (eg. during cluster migration using clusterctl move). For such cases, MachineHealthCheck provides 2 mechanisms to skip machines for remediation.
Implicit skipping when the resource is paused (using cluster.x-k8s.io/paused annotation):
When a cluster is paused, none of the machines in that cluster are considered for remediation.
When a machine is paused, only that machine is not considered for remediation.
A cluster or a machine is usually paused automatically by Cluster API when it detects a migration.
Explicit skipping using cluster.x-k8s.io/skip-remediation annotation:
Users can also skip any machine for remediation by setting the cluster.x-k8s.io/skip-remediation for that machine.
Before deploying a MachineHealthCheck, please familiarise yourself with the following limitations and caveats:
Only Machines owned by a MachineSet or a KubeadmControlPlane can be remediated by a MachineHealthCheck (since a MachineDeployment uses a MachineSet, then this includes Machines that are part of a MachineDeployment)
Machines managed by a KubeadmControlPlane are remediated according to the delete-and-recreate guidelines described in the KubeadmControlPlane proposal
The following rules should be satisfied in order to start remediation of a control plane machine:
One of the following apply:
The cluster MUST not be initialized yet (the failure happens before KCP reaches the initialized state)
The cluster MUST have at least two control plane machines, because this is the smallest cluster size that can be remediated.
Previous remediation (delete and re-create) MUST have been completed. This rule prevents KCP from remediating more machines while the replacement for the previous machine is not yet created.
The cluster MUST have no machines with a deletion timestamp. This rule prevents KCP taking actions while the cluster is in a transitional state.
Remediation MUST preserve etcd quorum. This rule ensures that we will not remove a member that would result in etcd losing a majority of members and thus become unable to field new requests (note: this rule applies only to CP already initialized and with managed etcd)
If the Node for a Machine is removed from the cluster, a MachineHealthCheck will consider this Machine unhealthy and remediate it immediately
If no Node joins the cluster for a Machine after the NodeStartupTimeout, the Machine will be remediated
If a Machine fails for any reason (if the FailureReason is set), the Machine will be remediated immediately
Cluster API now ships with a new experimental package that lives under the exp/ directory. This is a
temporary location for features which will be moved to their permanent locations after graduation. Users can experiment with these features by enabling them using feature gates.
Users can enable/disable features by setting OS environment variables before running clusterctl init, e.g.:
export EXP_SOME_FEATURE_NAME=true
clusterctl init --infrastructure vsphere
As an alternative to environment variables, it is also possible to set variables in the clusterctl config file located at $XDG_CONFIG_HOME/cluster-api/clusterctl.yaml, e.g.:
# Values for environment variable substitution
EXP_SOME_FEATURE_NAME: "true"
In case a variable is defined in both the config file and as an OS environment variable, the environment variable takes precedence.
For more information on how to set variables for clusterctl, see clusterctl Configuration File
Some features like MachinePools may require infrastructure providers to implement a separate CRD that handles the infrastructure side of the feature too.
For such a feature to work, infrastructure providers should also enable their controllers if it is implemented as a feature. If it is not implemented as a feature, no additional step is necessary.
As an example, Cluster API Provider Azure (CAPZ) has support for MachinePool through the infrastructure type AzureMachinePool.
One way is to set experimental variables on the clusterctl config file. For CAPI, these configs are under ./test/e2e/config/... such as docker.yaml:
variables:
CLUSTER_TOPOLOGY: "true"
EXP_RUNTIME_SDK: "true"
EXP_MACHINE_SET_PREFLIGHT_CHECKS: "true"
Another way is to set them as environmental variables before running e2e tests.
On development environments started with Tilt, features can be enabled by setting the feature variables in kustomize_substitutions, e.g.:
kustomize_substitutions:
CLUSTER_TOPOLOGY: 'true'
EXP_RUNTIME_SDK: 'true'
EXP_MACHINE_SET_PREFLIGHT_CHECKS: 'true'
For more details on setting up a development environment with tilt, see Developing Cluster API with Tilt
To enable/disable features on existing management clusters, users can edit the corresponding controller manager
deployments, which will then trigger a restart with the requested features. E.g. for the CAPI controller manager
deployment:
kubectl edit -n capi-system deployment.apps/capi-controller-manager
// Enable/disable available features by modifying Args below.
Args:
--leader-elect
--feature-gates=MachinePool=true,ClusterResourceSet=true
Similarly, to validate if a particular feature is enabled, see the arguments by issuing:
kubectl describe -n capi-system deployment.apps/capi-controller-manager
Following controller manager deployments have to be edited in order to enable/disable their respective experimental features:
Warning : Experimental features are unreliable, i.e., some may one day be promoted to the main repository, or they may be modified arbitrarily or even disappear altogether.
In short, they are not subject to any compatibility or deprecation promise.
The MachinePool feature provides a way to manage a set of machines by defining a common configuration, number of desired machine replicas etc. similar to MachineDeployment,
except MachineSet controllers are responsible for the lifecycle management of the machines for MachineDeployment, whereas in MachinePools,
each infrastructure provider has a specific solution for orchestrating these Machines.
Feature gate name : MachinePool
Variable name to enable/disable the feature gate : EXP_MACHINE_POOL
Infrastructure providers can support this feature by implementing their specific MachinePool such as AzureMachinePool.
More details on MachinePool can be found at:
MachinePool CAEP
For developer docs on the MachinePool controller, see here .
Although MachinePools provide a similar feature to MachineDeployments, MachinePools do so by leveraging an InfraMachinePool which corresponds 1:1 with a resource like VMSS on Azure or Autoscaling Groups on AWS which we treat as a black box. When a MachinePool is scaled up, the InfraMachinePool scales itself up and populates its provider ID list based on the response from the infrastructure provider. On the other hand, when a MachineDeployment is scaled up, new Machines are created which then create an individual InfraMachine, which corresponds to a VM in any infrastructure provider.
MachinePools MachineDeployments
Creates new instances through a single infrastructure resource like VMSS in Azure or Autoscaling Groups in AWS. Creates new instances by creating new Machines, which create individual VM instances on the infra provider. Set of instances is orchestrated by the infrastructure provider. Set of instances is orchestrated by Cluster API using a MachineSet. Each MachinePool corresponds 1:1 with an associated InfraMachinePool. Each MachineDeployment includes a MachineSet, and for each replica, it creates a Machine and InfraMachine. Each MachinePool requires only a single BootstrapConfig. Each MachineDeployment uses an InfraMachineTemplate and a BootstrapConfigTemplate, and each Machine requires a unique BootstrapConfig. Maintains a list of instances in the providerIDList field in the MachinePool spec. This list is populated based on the response from the infrastructure provider. Maintains a list of instances through the Machine resources owned by the MachineSet.
The MachineSetPreflightChecks feature can provide additional safety while creating new Machines and remediating existing unhealthy Machines of a MachineSet.
When a MachineSet creates machines under certain circumstances, the operation fails or leads to a new machine that will be deleted and recreated in a short timeframe,
leading to unwanted Machine churn. Some of these circumstances include, but not limited to, creating a new Machine when Kubernetes version skew could be violated or
joining a Machine when the Control Plane is upgrading leading to failure because of mixed kube-apiserver version or due to the cluster load balancer delays in adapting
to the changes.
Enabling MachineSetPreflightChecks provides safety in such circumstances by making sure that a Machine is only created when it is safe to do so.
Feature gate name : MachineSetPreflightChecks
Variable name to enable/disable the feature gate : EXP_MACHINE_SET_PREFLIGHT_CHECKS
This preflight check ensures that the ControlPlane is currently stable i.e. the ControlPlane is currently neither provisioning nor upgrading.
This preflight check is only performed if:
The Cluster uses a ControlPlane provider.
ControlPlane version is defined (ControlPlane.spec.version is set).
This preflight check ensures that the MachineSet and the ControlPlane conform to the Kubernetes version skew .
This preflight check is only performed if:
The Cluster uses a ControlPlane provider.
ControlPlane version is defined (ControlPlane.spec.version is set).
MachineSet version is defined (MachineSet.spec.template.spec.version is set).
This preflight check ensures that the MachineSet and the ControlPlane conform to the kubeadm version skew .
This preflight check is only performed if:
The Cluster uses a ControlPlane provider.
ControlPlane version is defined (ControlPlane.spec.version is set).
MachineSet version is defined (MachineSet.spec.template.spec.version is set).
MachineSet uses the Kubeadm Bootstrap provider.
Once the feature flag is enabled the preflight checks are enabled for all the MachineSets including new and existing MachineSets.
It is possible to opt-out of one or all of the preflight checks on a per MachineSet basis by specifying a comma-separated list of the preflight checks on the
machineset.cluster.x-k8s.io/skip-preflight-checks annotation on the MachineSet.
Examples:
To opt out of all the preflight checks set the machineset.cluster.x-k8s.io/skip-preflight-checks: All annotation.
To opt out of the ControlPlaneIsStable preflight check set the machineset.cluster.x-k8s.io/skip-preflight-checks: ControlPlaneIsStable annotation.
To opt out of multiple preflight checks set the machineset.cluster.x-k8s.io/skip-preflight-checks: ControlPlaneIsStable,KubernetesVersionSkew annotation.
Because of the metadata propagation rules in Cluster API you can set the machineset.cluster.x-k8s.io/skip-preflight-checks annotation
on a MachineDeployment and it will be automatically set on the MachineSets of that MachineDeployment, including any new MachineSets created when the MachineDeployment performs a rollout.
The ClusterResourceSet feature is introduced to provide a way to automatically apply a set of resources (such as CNI/CSI) defined by users to matching newly-created/existing clusters.
Feature gate name : ClusterResourceSet
Variable name to enable/disable the feature gate : EXP_CLUSTER_RESOURCE_SET
The ClusterResourceSet feature is enabled by default, but can be disabled by setting the EXP_CLUSTER_RESOURCE_SET environment variable to false.
More details on ClusterResourceSet can be found at:
ClusterResourceSet CAEP
Suppose you want to automatically install the relevant external cloud provider on all workload clusters.
This can be accomplished by labeling the clusters with the specific cloud (e.g. AWS, GCP or OpenStack) and then creating a ClusterResourceSet for each.
For example, you could have the following for OpenStack:
apiVersion: addons.cluster.x-k8s.io/v1beta1
kind: ClusterResourceSet
metadata:
name: cloud-provider-openstack
namespace: default
spec:
strategy: Reconcile
clusterSelector:
matchLabels:
cloud: openstack
resources:
- name: cloud-provider-openstack
kind: ConfigMap
- name: cloud-config
kind: Secret
This ClusterResourceSet would apply the content of the Secret cloud-config and of the ConfigMap cloud-provider-openstack in all workload clusters with the label cloud=openstack.
Suppose you have the file cloud.conf that should be included in the Secret and cloud-provider-openstack.yaml that should be in the ConfigMap.
The Secret and ConfigMap can then be created in the following way:
kubectl create secret generic cloud-config --from-file=cloud.conf --type=addons.cluster.x-k8s.io/resource-set
kubectl create configmap cloud-provider-openstack --from-file=cloud-provider-openstack.yaml
Note that it is required that the Secret has the type addons.cluster.x-k8s.io/resource-set for it to be picked up.
The strategy field is immutable so existing CRS can’t be updated directly. However, CAPI won’t delete the managed resources in the target cluster when the CRS is deleted.
So if you want to start using the Reconcile strategy, delete your existing CRS and create it again with the updated strategy.
The ClusterClass feature introduces a new way to create clusters which reduces boilerplate and enables flexible and powerful customization of clusters.
ClusterClass is a powerful abstraction implemented on top of existing interfaces and offers a set of tools and operations to streamline cluster lifecycle management while maintaining the same underlying API.
In order to use the ClusterClass (alpha) experimental feature the Kubernetes Version for the management cluster must be >= 1.22.0.
Feature gate name : ClusterTopology
Variable name to enable/disable the feature gate : CLUSTER_TOPOLOGY
Additional documentation:
A ClusterClass becomes more useful and valuable when it can be used to create many Cluster of a similar
shape. The goal of this document is to explain how ClusterClasses can be written in a way that they are
flexible enough to be used in as many Clusters as possible by supporting variants of the same base Cluster shape.
Table of Contents
The following example shows a basic ClusterClass. It contains templates to shape the control plane,
infrastructure and workers of a Cluster. When a Cluster is using this ClusterClass, the templates
are used to generate the objects of the managed topology of the Cluster.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
controlPlane:
ref:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlaneTemplate
name: docker-clusterclass-v0.1.0
namespace: default
machineInfrastructure:
ref:
kind: DockerMachineTemplate
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
name: docker-clusterclass-v0.1.0
namespace: default
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerClusterTemplate
name: docker-clusterclass-v0.1.0-control-plane
namespace: default
workers:
machineDeployments:
- class: default-worker
template:
bootstrap:
ref:
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
name: docker-clusterclass-v0.1.0-default-worker
namespace: default
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachineTemplate
name: docker-clusterclass-v0.1.0-default-worker
namespace: default
The following example shows a Cluster using this ClusterClass. In this case a KubeadmControlPlane
with the corresponding DockerMachineTemplate, a DockerCluster and a MachineDeployment with
the corresponding KubeadmConfigTemplate and DockerMachineTemplate will be created. This basic
ClusterClass is already very flexible. Via the topology on the Cluster the following can be configured:
.spec.topology.version: the Kubernetes version of the Cluster.spec.topology.controlPlane: ControlPlane replicas and their metadata.spec.topology.workers: MachineDeployments and their replicas, metadata and failure domain
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: my-docker-cluster
spec:
topology:
class: docker-clusterclass-v0.1.0
version: v1.22.4
controlPlane:
replicas: 3
metadata:
labels:
cpLabel: cpLabelValue
annotations:
cpAnnotation: cpAnnotationValue
workers:
machineDeployments:
- class: default-worker
name: md-0
replicas: 4
metadata:
labels:
mdLabel: mdLabelValue
annotations:
mdAnnotation: mdAnnotationValue
failureDomain: region
Best practices:
The ClusterClass name should be generic enough to make sense across multiple clusters, i.e. a
name which corresponds to a single Cluster, e.g. “my-cluster”, is not recommended.
Try to keep the ClusterClass names short and consistent (if you publish multiple ClusterClasses).
As a ClusterClass usually evolves over time and you might want to rebase Clusters from one version
of a ClusterClass to another, consider including a version suffix in the ClusterClass name.
For more information about changing a ClusterClass please see: Changing a ClusterClass .
Prefix the templates used in a ClusterClass with the name of the ClusterClass.
Don’t reuse the same template in multiple ClusterClasses. This is automatically taken care
of by prefixing the templates with the name of the ClusterClass.
For a full example ClusterClass for CAPD you can take a look at
clusterclass-quickstart.yaml
(which is also used in the CAPD quickstart with ClusterClass).
The clusterctl alpha topology plan command can be used to test ClusterClasses; the output will show
you how the resulting Cluster will look like, but without actually creating it.
For more details please see: clusterctl alpha topology plan .
ClusterClass also supports MachinePool workers. They work very similar to MachineDeployments. MachinePools
can be specified in the ClusterClass template under the workers section like so:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
workers:
machinePools:
- class: default-worker
template:
bootstrap:
ref:
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
name: quick-start-default-worker-bootstraptemplate
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachinePoolTemplate
name: quick-start-default-worker-machinepooltemplate
They can then be similarly defined as workers in the cluster template like so:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: my-docker-cluster
spec:
topology:
workers:
machinePools:
- class: default-worker
name: mp-0
replicas: 4
metadata:
labels:
mpLabel: mpLabelValue
annotations:
mpAnnotation: mpAnnotationValue
failureDomain: region
MachineHealthChecks can be configured in the ClusterClass for the control plane and for a
MachineDeployment class. The following configuration makes sure a MachineHealthCheck is
created for the control plane and for every MachineDeployment using the default-worker class.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
controlPlane:
...
machineHealthCheck:
maxUnhealthy: 33%
nodeStartupTimeout: 15m
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
workers:
machineDeployments:
- class: default-worker
...
machineHealthCheck:
unhealthyRange: "[0-2]"
nodeStartupTimeout: 10m
unhealthyConditions:
- type: Ready
status: Unknown
timeout: 300s
- type: Ready
status: "False"
timeout: 300s
As shown above, basic ClusterClasses are already very powerful. But there are cases where
more powerful mechanisms are required. Let’s assume you want to manage multiple Clusters
with the same ClusterClass, but they require different values for a field in one of the
referenced templates of a ClusterClass.
A concrete example would be to deploy Clusters with different registries. In this case,
every cluster needs a Cluster-specific value for .spec.kubeadmConfigSpec.clusterConfiguration.imageRepository
in KubeadmControlPlane. Use cases like this can be implemented with ClusterClass patches.
Defining variables in the ClusterClass
The following example shows how variables can be defined in the ClusterClass.
A variable definition specifies the name and the schema of a variable and if it is
required. The schema defines how a variable is defaulted and validated. It supports
a subset of the schema of CRDs. For more information please see the godoc .
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
variables:
- name: imageRepository
required: true
schema:
openAPIV3Schema:
type: string
description: ImageRepository is the container registry to pull images from.
default: registry.k8s.io
example: registry.k8s.io
The following basic types are supported: string, integer, number and boolean. We are also
supporting complex types, please see the complex variable types section.
Defining patches in the ClusterClass
The variable can then be used in a patch to set a field on a template referenced in the ClusterClass.
The selector specifies on which template the patch should be applied. jsonPatches specifies which JSON
patches should be applied to that template. In this case we set the imageRepository field of the
KubeadmControlPlaneTemplate to the value of the variable imageRepository. For more information
please see the godoc .
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
patches:
- name: imageRepository
definitions:
- selector:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlaneTemplate
matchResources:
controlPlane: true
jsonPatches:
- op: add
path: /spec/template/spec/kubeadmConfigSpec/clusterConfiguration/imageRepository
valueFrom:
variable: imageRepository
Only fields below /spec can be patched.
Only add, remove and replace operations are supported.
It’s only possible to append and prepend to arrays. Insertions at a specific index are
not supported.
Be careful, appending or prepending an array variable to an array leads to a nested array
(for more details please see this issue ).
Setting variable values in the Cluster
After creating a ClusterClass with a variable definition, the user can now provide a value for
the variable in the Cluster as in the example below.
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: my-docker-cluster
spec:
topology:
...
variables:
- name: imageRepository
value: my.custom.registry
If the user does not set the value, but the corresponding variable definition in ClusterClass has
a default value, the value is automatically added to the variables list.
The controller needs to generate names for new objects when a Cluster is getting created
from a ClusterClass. These names have to be unique for each namespace. The naming
strategy enables this by concatenating the cluster name with a random suffix.
It is possible to provide a custom template for the name generation of ControlPlane, MachineDeployment
and MachinePool objects.
The generated names must comply with the RFC 1123 standard.
The naming strategy for ControlPlane supports the following properties:
template: Custom template which is used when generating the name of the ControlPlane object.
The following variables can be referenced in templates:
.cluster.name: The name of the cluster object..random: A random alphanumeric string, without vowels, of length 5.
Example which would match the default behavior:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
controlPlane:
...
namingStrategy:
template: "{{ .cluster.name }}-{{ .random }}"
...
The naming strategy for MachineDeployments supports the following properties:
template: Custom template which is used when generating the name of the MachineDeployment object.
The following variables can be referenced in templates:
.cluster.name: The name of the cluster object..random: A random alphanumeric string, without vowels, of length 5..machineDeployment.topologyName: The name of the MachineDeployment topology (Cluster.spec.topology.workers.machineDeployments[].name)
Example which would match the default behavior:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
controlPlane:
...
workers:
machineDeployments:
- class: default-worker
...
namingStrategy:
template: "{{ .cluster.name }}-{{ .machineDeployment.topologyName }}-{{ .random }}"
The naming strategy for MachinePools supports the following properties:
template: Custom template which is used when generating the name of the MachinePool object.
The following variables can be referenced in templates:
.cluster.name: The name of the cluster object..random: A random alphanumeric string, without vowels, of length 5..machinePool.topologyName: The name of the MachinePool topology (Cluster.spec.topology.workers.machinePools[].name).
Example which would match the default behavior:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
controlPlane:
...
workers:
machinePools:
- class: default-worker
...
namingStrategy:
template: "{{ .cluster.name }}-{{ .machinePool.topologyName }}-{{ .random }}"
This section will explain more advanced features of ClusterClass patches.
If you want to use many variations of MachineDeployments in Clusters, you can either define
a MachineDeployment class for every variation or you can define patches and variables to
make a single MachineDeployment class more flexible. The same applies for MachinePools.
In the following example we make the instanceType of a AWSMachineTemplate customizable.
First we define the workerMachineType variable and the corresponding patch:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: aws-clusterclass-v0.1.0
spec:
...
variables:
- name: workerMachineType
required: true
schema:
openAPIV3Schema:
type: string
default: t3.large
patches:
- name: workerMachineType
definitions:
- selector:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: AWSMachineTemplate
matchResources:
machineDeploymentClass:
names:
- default-worker
jsonPatches:
- op: add
path: /spec/template/spec/instanceType
valueFrom:
variable: workerMachineType
---
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: AWSMachineTemplate
metadata:
name: aws-clusterclass-v0.1.0-default-worker
spec:
template:
spec:
# instanceType: workerMachineType will be set by the patch.
iamInstanceProfile: "nodes.cluster-api-provider-aws.sigs.k8s.io"
---
...
In the Cluster resource the workerMachineType variable can then be set cluster-wide and
it can also be overridden for an individual MachineDeployment or MachinePool.
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: my-aws-cluster
spec:
...
topology:
class: aws-clusterclass-v0.1.0
version: v1.22.0
controlPlane:
replicas: 3
workers:
machineDeployments:
- class: "default-worker"
name: "md-small-workers"
replicas: 3
variables:
overrides:
# Overrides the cluster-wide value with t3.small.
- name: workerMachineType
value: t3.small
# Uses the cluster-wide value t3.large.
- class: "default-worker"
name: "md-large-workers"
replicas: 3
variables:
- name: workerMachineType
value: t3.large
In addition to variables specified in the ClusterClass, the following builtin variables can be
referenced in patches:
builtin.cluster.{name,namespace,uid}builtin.cluster.topology.{version,class}builtin.cluster.network.{serviceDomain,services,pods,ipFamily}
Note: ipFamily is deprecated and will be removed in a future release. see https://github.com/kubernetes-sigs/cluster-api/issues/7521.
builtin.controlPlane.{replicas,version,name,metadata.labels,metadata.annotations}
Please note, these variables are only available when patching control plane or control plane
machine templates.
builtin.controlPlane.machineTemplate.infrastructureRef.name
Please note, these variables are only available when using a control plane with machines and
when patching control plane or control plane machine templates.
builtin.machineDeployment.{replicas,version,class,name,topologyName,metadata.labels,metadata.annotations}
Please note, these variables are only available when patching the templates of a MachineDeployment
and contain the values of the current MachineDeployment topology.
builtin.machineDeployment.{infrastructureRef.name,bootstrap.configRef.name}
Please note, these variables are only available when patching the templates of a MachineDeployment
and contain the values of the current MachineDeployment topology.
builtin.machinePool.{replicas,version,class,name,topologyName,metadata.labels,metadata.annotations}
Please note, these variables are only available when patching the templates of a MachinePool
and contain the values of the current MachinePool topology.
builtin.machinePool.{infrastructureRef.name,bootstrap.configRef.name}
Please note, these variables are only available when patching the templates of a MachinePool
and contain the values of the current MachinePool topology.
Builtin variables can be referenced just like regular variables, e.g.:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
patches:
- name: clusterName
definitions:
- selector:
...
jsonPatches:
- op: add
path: /spec/template/spec/kubeadmConfigSpec/clusterConfiguration/controllerManager/extraArgs/cluster-name
valueFrom:
variable: builtin.cluster.name
Tips & Tricks
Builtin variables can be used to dynamically calculate image names. The version used in the patch
will always be the same as the one we set in the corresponding MachineDeployment or MachinePool
(works the same way with .builtin.controlPlane.version).
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
patches:
- name: customImage
description: "Sets the container image that is used for running dockerMachines."
definitions:
- selector:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachineTemplate
matchResources:
machineDeploymentClass:
names:
- default-worker
jsonPatches:
- op: add
path: /spec/template/spec/customImage
valueFrom:
template: |
kindest/node:{{ .builtin.machineDeployment.version }}
Variables can also be objects, maps and arrays. An object is specified with the type object and
by the schemas of the fields of the object. A map is specified with the type object and the schema
of the map values. An array is specified via the type array and the schema of the array items.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
variables:
- name: httpProxy
schema:
openAPIV3Schema:
type: object
properties:
# Schema of the url field.
url:
type: string
# Schema of the noProxy field.
noProxy:
type: string
- name: mdConfig
schema:
openAPIV3Schema:
type: object
additionalProperties:
# Schema of the map values.
type: object
properties:
osImage:
type: string
- name: dnsServers
schema:
openAPIV3Schema:
type: array
items:
# Schema of the array items.
type: string
Objects, maps and arrays can be used in patches either directly by referencing the variable name,
or by accessing individual fields. For example:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
jsonPatches:
- op: add
path: /spec/template/spec/httpProxy/url
valueFrom:
# Use the url field of the httpProxy variable.
variable: httpProxy.url
- op: add
path: /spec/template/spec/customImage
valueFrom:
# Use the osImage field of the mdConfig variable for the current MD class.
template: "{{ (index .mdConfig .builtin.machineDeployment.class).osImage }}"
- op: add
path: /spec/template/spec/dnsServers
valueFrom:
# Use the entire dnsServers array.
variable: dnsServers
- op: add
path: /spec/template/spec/dnsServer
valueFrom:
# Use the first item of the dnsServers array.
variable: dnsServers[0]
Tips & Tricks
Complex variables can be used to make references in templates configurable, e.g. the identityRef used in AzureCluster.
Of course it’s also possible to only make the name of the reference configurable, including restricting the valid values
to a pre-defined enum.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: azure-clusterclass-v0.1.0
spec:
...
variables:
- name: clusterIdentityRef
schema:
openAPIV3Schema:
type: object
properties:
kind:
type: string
name:
type: string
Even if OpenAPI schema allows defining free form objects, e.g.
variables:
- name: freeFormObject
schema:
openAPIV3Schema:
type: object
User should be aware that the lack of the validation of users provided data could lead to problems
when those values are used in patch or when the generated templates are created (see e.g.
6135 ).
As a consequence we recommend avoiding this practice while we are considering alternatives to make
it explicit for the ClusterClass authors to opt-in in this feature, thus accepting the implied risks.
We already saw above that it’s possible to use variable values in JSON patches. It’s also
possible to calculate values via Go templating or to use hard-coded values.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
patches:
- name: etcdImageTag
definitions:
- selector:
...
jsonPatches:
- op: add
path: /spec/template/spec/kubeadmConfigSpec/clusterConfiguration/etcd
valueFrom:
# This template is first rendered with Go templating, then parsed by
# a YAML/JSON parser and then used as value of the JSON patch.
# For example, if the variable etcdImageTag is set to `3.5.1-0` the
# .../clusterConfiguration/etcd field will be set to:
# {"local": {"imageTag": "3.5.1-0"}}
template: |
local:
imageTag: {{ .etcdImageTag }}
- name: imageRepository
definitions:
- selector:
...
jsonPatches:
- op: add
path: /spec/template/spec/kubeadmConfigSpec/clusterConfiguration/imageRepository
# This hard-coded value is used directly as value of the JSON patch.
value: "my.custom.registry"
Paths can be used in .valueFrom.template and .valueFrom.variable to access nested fields of arrays and objects.
. is used to access a field of an object, e.g. httpProxy.url.[i] is used to access an array element, e.g. dnsServers[0].Because of the way Go templates work, the paths in templates have to start with a dot.
Tips & Tricks
Templates can be used to implement defaulting behavior during JSON patch value calculation. This can be used if the simple
constant default value which can be specified in the schema is not enough.
valueFrom:
# If .vnetName is set, it is used. Otherwise, we will use `{{.builtin.cluster.name}}-vnet`.
template: "{{ if .vnetName }}{{.vnetName}}{{else}}{{.builtin.cluster.name}}-vnet{{end}}"
When writing templates, a subset of functions from the Sprig library can be used to
write expressions, e.g., {{ .name | upper }}. Only functions that are guaranteed to evaluate to the same result
for a given input are allowed (e.g. upper or max can be used, while now or randAlpha cannot be used).
Patches can also be conditionally enabled. This can be done by configuring a Go template via enabledIf.
The patch is then only applied if the Go template evaluates to true. In the following example the httpProxy
patch is only applied if the httpProxy variable is set (and not empty).
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: docker-clusterclass-v0.1.0
spec:
...
variables:
- name: httpProxy
schema:
openAPIV3Schema:
type: string
patches:
- name: httpProxy
enabledIf: "{{ if .httpProxy }}true{{end}}"
definitions:
...
Tips & Tricks :
Hard-coded values can be used to test the impact of a patch during development, gradually roll out patches, etc. .
enabledIf: false
A boolean variable can be used to enable/disable a patch (or “feature”). This can have opt-in or opt-out behavior
depending on the default value of the variable.
enabledIf: "{{ .httpProxyEnabled }}"
Of course the same is possible by adding a boolean variable to a configuration object.
enabledIf: "{{ .httpProxy.enabled }}"
Builtin variables can be leveraged to apply a patch only for a specific Kubernetes version.
enabledIf: '{{ semverCompare "1.21.1" .builtin.controlPlane.version }}'
With semverCompare and coalesce a feature can be enabled in newer versions of Kubernetes for both KubeadmConfigTemplate and KubeadmControlPlane.
enabledIf: '{{ semverCompare "^1.22.0" (coalesce .builtin.controlPlane.version .builtin.machineDeployment.version )}}'
Please be aware that while you can use builtin variables, if you use for example a MachineDeployment-specific variable this
can mean that patches are only applied to some MachineDeployments. enabledIf is evaluated for each template that should be patched
individually.
In some cases the ClusterClass authors want a patch to be computed according to the Kubernetes version in use.
While this is not a problem “per se” and it does not differ from writing any other patch, it is important
to keep in mind that there could be different Kubernetes version in a Cluster at any time, all of them
accessible via built in variables:
builtin.cluster.topology.version defines the Kubernetes version from cluster.topology, and it acts
as the desired Kubernetes version for the entire cluster. However, during an upgrade workflow it could happen that
some objects in the Cluster are still at the older version.builtin.controlPlane.version, represent the desired version for the control plane object; usually this
version changes immediately after cluster.topology.version is updated (unless there are other operations
in progress preventing the upgrade to start).builtin.machineDeployment.version, represent the desired version for each specific MachineDeployment object;
this version changes only after the upgrade for the control plane is completed, and in case of many
MachineDeployments in the same cluster, they are upgraded sequentially.builtin.machinePool.version, represent the desired version for each specific MachinePool object;
this version changes only after the upgrade for the control plane is completed, and in case of many
MachinePools in the same cluster, they are upgraded sequentially.
This info should provide the bases for developing version-aware patches, allowing the patch author to determine when a
patch should adapt to the new Kubernetes version by choosing one of the above variables. In practice the
following rules applies to the most common use cases:
When developing a version-aware patch for the control plane, builtin.controlPlane.version must be used.
When developing a version-aware patch for MachineDeployments, builtin.machineDeployment.version must be used.
When developing a version-aware patch for MachinePools, builtin.machinePool.version must be used.
Tips & Tricks :
Sometimes users need to define variables to be used by version-aware patches, and in this case it is important
to keep in mind that there could be different Kubernetes versions in a Cluster at any time.
A simple approach to solve this problem is to define a map of version-aware variables, with the key of each item
being the Kubernetes version. Patch could then use the proper builtin variables as a lookup entry to fetch
the corresponding values for the Kubernetes version in use by each object.
JSON patches specification RFC6902 requires that the target of
add operation must exist.
As a consequence ClusterClass authors should pay special attention when the following
conditions apply in order to prevent errors when a patch is applied:
the patch tries to add a value to an array (which is a slice in the corresponding go struct)
the slice was defined with omitempty
the slice currently does not exist
A workaround in this particular case is to create the array in the patch instead of adding to the non-existing one.
When creating the slice, existing values would be overwritten so this should only be used when it does not exist.
The following example shows both cases to consider while writing a patch for adding a value to a slice.
This patch targets to add a file to the files slice of a KubeadmConfigTemplate which has omitempty set.
When planning a change to a ClusterClass, users should always take into consideration
how those changes might impact the existing Clusters already using the ClusterClass, if any.
There are two strategies for defining how a ClusterClass change rolls out to existing Clusters:
Roll out ClusterClass changes to existing Cluster in a controlled/incremental fashion.
Roll out ClusterClass changes to all the existing Cluster immediately.
The first strategy is the recommended choice for people starting with ClusterClass; it
requires the users to create a new ClusterClass with the expected changes, and then
rebase each Cluster to use the newly created ClusterClass.
By splitting the change to the ClusterClass and its rollout
to Clusters into separate steps the user will reduce the risk of introducing unexpected
changes on existing Clusters, or at least limit the blast radius of those changes
to a small number of Clusters already rebased (in fact it is similar to a canary deployment).
The second strategy listed above instead requires changing a ClusterClass “in place”, which can
be simpler and faster than creating a new ClusterClass. However, this approach
means that changes are immediately propagated to all the Clusters already using the
modified ClusterClass. Any operation involving many Clusters at the same time has intrinsic risks,
and it can impact heavily on the underlying infrastructure in case the operation triggers
machine rollout across the entire fleet of Clusters.
However, regardless of which strategy you are choosing to implement your changes to a ClusterClass,
please make sure to:
If instead you are interested in understanding more about which kind ofPlan ClusterClass changes documentation or looking at the reference
documentation at the end of this page.
Templates are an integral part of a ClusterClass, and thus the same considerations
described in the previous paragraph apply. When changing
a template referenced in a ClusterClass users should also always plan for how the
change should be propagated to the existing Clusters and choose the strategy that best
suits expectations.
According to the Cluster API operational practices ,
the recommended way for updating templates is by template rotation:
Create a new template
Update the template reference in the ClusterClass
Delete the old template
In case a provider supports in place template mutations, the Cluster API topology controller
will adapt to them during the next reconciliation, but the system is not watching for those changes.
Meaning, when the underlying template is updated the changes
may not be reflected immediately, however they will be picked up during the next full reconciliation.
The maximum time for the next full reconciliation is equal to the CAPI controller
sync period (defaults to 10 minutes).
As already discussed in writing a cluster class , while it is technically possible to
re-use a template across ClusterClasses, this practice is not recommended because it makes it difficult
to reason about the impact of changing such a template can have on existing Clusters.
Also in case of changes to the ClusterClass templates, please make sure to:
You can learn more about this reading the notes in the Plan ClusterClass changes documentation or
looking at the reference documentation at the end of this page.
Rebasing is an operational practice for transitioning a Cluster from one ClusterClass to another,
and the operation can be triggered by simply changing the value in Cluster.spec.topology.class.
Also in this case, please make sure to:
You can learn more about this reading the notes in the Plan ClusterClass changes documentation or
looking at the reference documentation at the end of this page.
When changing a ClusterClass, the system validates the required changes according to
a set of “compatibility rules” in order to prevent changes which would lead to a non-functional
Cluster, e.g. changing the InfrastructureProvider from AWS to Azure.
If the proposed changes are evaluated as dangerous, the operation is rejected.
In the current implementation there are no compatibility rules for changes to provider
templates, so you should refer to the provider documentation to avoid
potentially dangerous changes on those objects.
For additional info see compatibility rules
defined in the ClusterClass proposal.
It is highly recommended to always generate a plan for ClusterClass changes before applying them,
no matter if you are creating a new ClusterClass and rebasing Clusters or if you are changing
your ClusterClass in place.
The clusterctl tool provides a new alpha command for this operation, clusterctl alpha topology plan .
The output of this command will provide you all the details about how those changes would impact
Clusters, but the following notes can help you to understand what you should
expect when planning your ClusterClass changes:
Users should expect the resources in a Cluster (e.g. MachineDeployments) to behave consistently
no matter if a change is applied via a ClusterClass or directly as you do in a Cluster without
a ClusterClass. In other words, if someone changes something on a KCP object triggering a
control plane Machines rollout, you should expect the same to happen when the same change
is applied to the KCP template in ClusterClass.
User should expect the Cluster topology to change consistently irrespective of how the change has been
implemented inside the ClusterClass or applied to the ClusterClass. In other words,
if you change a template field “in place”, or if you rotate the template referenced in the
ClusterClass by pointing to a new template with the same field changed, or if you change the
same field via a patch, the effects on the Cluster are the same.
See reference for more details.
The following table documents the effects each ClusterClass change can have on a Cluster;
Similar considerations apply to changes introduced by changes in Cluster.Topology or by
changes introduced by patches.
NOTE: for people used to operating Cluster API without Cluster Class, it could also help to keep in mind that the
underlying objects like control plane and MachineDeployment act in the same way with and without a ClusterClass.
Changed field Effects on Clusters
infrastructure.ref Corresponding InfrastructureCluster objects are updated (in place update). controlPlane.metadata If labels/annotations are added, changed or deleted the ControlPlane objects are updated (in place update). controlPlane.ref Corresponding ControlPlane objects are updated (in place update). controlPlane.machineInfrastructure.ref If the referenced template has changes only in metadata labels or annotations, the corresponding InfrastructureMachineTemplates are updated (in place update). controlPlane.nodeDrainTimeout If the value is changed the ControlPlane object is updated in-place. controlPlane.nodeVolumeDetachTimeout If the value is changed the ControlPlane object is updated in-place. controlPlane.nodeDeletionTimeout If the value is changed the ControlPlane object is updated in-place. workers.machineDeployments If a new MachineDeploymentClass is added, no changes are triggered to the Clusters. workers.machineDeployments[].template.metadata If labels/annotations are added, changed or deleted the MachineDeployment objects are updated (in place update) and corresponding worker Machines are updated (in-place). workers.machineDeployments[].template.bootstrap.ref If the referenced template has changes only in metadata labels or annotations, the corresponding BootstrapTemplates are updated (in place update). workers.machineDeployments[].template.infrastructure.ref If the referenced template has changes only in metadata labels or annotations, the corresponding InfrastructureMachineTemplates are updated (in place update). workers.machineDeployments[].template.nodeDrainTimeout If the value is changed the MachineDeployment is updated in-place. workers.machineDeployments[].template.nodeVolumeDetachTimeout If the value is changed the MachineDeployment is updated in-place. workers.machineDeployments[].template.nodeDeletionTimeout If the value is changed the MachineDeployment is updated in-place. workers.machineDeployments[].template.minReadySeconds If the value is changed the MachineDeployment is updated in-place.
The topology reconciler enforces values defined in the ClusterClass templates into the topology
owned objects in a Cluster.
More specifically, the topology controller uses Server Side Apply
to write/patch topology owned objects; using SSA allows other controllers to co-author the generated objects,
like e.g. adding info for subnets in CAPA.
The considerations above apply also when using patches, the only difference being that the
set of fields that are enforced should be determined by applying patches on top of the templates.
A corollary of the behaviour described above is that it is technically possible to change fields in the object
which are not derived from the templates and patches, but we advise against using the possibility
or making ad-hoc changes in generated objects unless otherwise needed for a workaround. It is always
preferable to improve ClusterClasses by supporting new Cluster variants in a reusable way.
The spec.topology field added to the Cluster object as part of ClusterClass allows changes made on the Cluster to be propagated across all relevant objects. This means the Cluster object can be used as a single point of control for making changes to objects that are part of the Cluster, including the ControlPlane and MachineDeployments.
A managed Cluster can be used to:
Using a managed topology the operation to upgrade a Kubernetes cluster is a one-touch operation.
Let’s assume we have created a CAPD cluster with ClusterClass and specified Kubernetes v1.21.2 (as documented in the Quick Start guide ). Specifying the version is done when running clusterctl generate cluster. Looking at the cluster, the version of the control plane and the MachineDeployments is v1.21.2.
> kubectl get kubeadmcontrolplane,machinedeployments
NAME CLUSTER INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
kubeadmcontrolplane.controlplane.cluster.x-k8s.io/clusterclass-quickstart-XXXX clusterclass-quickstart true true 1 1 1 0 2m21s v1.21.2
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
machinedeployment.cluster.x-k8s.io/clusterclass-quickstart-linux-workers-XXXX clusterclass-quickstart 1 1 1 0 Running 2m21s v1.21.2
To update the Cluster the only change needed is to the version field under spec.topology in the Cluster object.
Change 1.21.2 to 1.22.0 as below.
kubectl patch cluster clusterclass-quickstart --type json --patch '[{"op": "replace", "path": "/spec/topology/version", "value": "v1.22.0"}]'
The patch will make the following change to the Cluster yaml:
spec:
topology:
class: quick-start
+ version: v1.22.0
- version: v1.21.2
Important Note : A +2 minor Kubernetes version upgrade is not allowed in Cluster Topologies. This is to align with existing control plane providers, like KubeadmControlPlane provider, that limit a +2 minor version upgrade. Example: Upgrading from 1.21.2 to 1.23.0 is not allowed.
The upgrade will take some time to roll out as it will take place machine by machine with older versions of the machines only being removed after healthy newer versions come online.
To watch the update progress run:
watch kubectl get kubeadmcontrolplane,machinedeployments
After a few minutes the upgrade will be complete and the output will be similar to:
NAME CLUSTER INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
kubeadmcontrolplane.controlplane.cluster.x-k8s.io/clusterclass-quickstart-XXXX clusterclass-quickstart true true 1 1 1 0 7m29s v1.22.0
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
machinedeployment.cluster.x-k8s.io/clusterclass-quickstart-linux-workers-XXXX clusterclass-quickstart 1 1 1 0 Running 7m29s v1.22.0
When using a managed topology scaling of MachineDeployments, both up and down, should be done through the Cluster topology.
Assume we have created a CAPD cluster with ClusterClass and Kubernetes v1.23.3 (as documented in the Quick Start guide ). Initially we should have a MachineDeployment with 3 replicas. Running
kubectl get machinedeployments
Will give us:
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
machinedeployment.cluster.x-k8s.io/capi-quickstart-md-0-XXXX capi-quickstart 3 3 3 0 Running 21m v1.23.3
We can scale up or down this MachineDeployment through the Cluster object by changing the replicas field under /spec/topology/workers/machineDeployments/0/replicas
The 0 in the path refers to the position of the target MachineDeployment in the list of our Cluster topology. As we only have one MachineDeployment we’re targeting the first item in the list under /spec/topology/workers/machineDeployments/.
To change this value with a patch:
kubectl patch cluster capi-quickstart --type json --patch '[{"op": "replace", "path": "/spec/topology/workers/machineDeployments/0/replicas", "value": 1}]'
This patch will make the following changes on the Cluster yaml:
spec:
topology:
workers:
machineDeployments:
- class: default-worker
name: md-0
metadata: {}
+ replicas: 1
- replicas: 3
After a minute the MachineDeployment will have scaled down to 1 replica:
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
capi-quickstart-md-0-XXXXX capi-quickstart 1 1 1 0 Running 25m v1.23.3
As well as scaling a MachineDeployment, Cluster operators can edit the labels and annotations applied to a running MachineDeployment using the Cluster topology as a single point of control.
MachineDeployments in a managed Cluster are defined in the Cluster’s topology. Cluster operators can add a MachineDeployment to a living Cluster by adding it to the cluster.spec.topology.workers.machineDeployments field.
Assume we have created a CAPD cluster with ClusterClass and Kubernetes v1.23.3 (as documented in the Quick Start guide ). Initially we should have a single MachineDeployment with 3 replicas. Running
kubectl get machinedeployments
Will give us:
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
machinedeployment.cluster.x-k8s.io/capi-quickstart-md-0-XXXX capi-quickstart 3 3 3 0 Running 21m v1.23.3
A new MachineDeployment can be added to the Cluster by adding a new MachineDeployment spec under /spec/topology/workers/machineDeployments/. To do so we can patch our Cluster with:
kubectl patch cluster capi-quickstart --type json --patch '[{"op": "add", "path": "/spec/topology/workers/machineDeployments/-", "value": {"name": "second-deployment", "replicas": 1, "class": "default-worker"} }]'
This patch will make the below changes on the Cluster yaml:
spec:
topology:
workers:
machineDeployments:
- class: default-worker
metadata: {}
replicas: 3
name: md-0
+ - class: default-worker
+ metadata: {}
+ replicas: 1
+ name: second-deployment
After a minute to scale the new MachineDeployment we get:
NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
capi-quickstart-md-0-XXXX capi-quickstart 1 1 1 0 Running 39m v1.23.3
capi-quickstart-second-deployment-XXXX capi-quickstart 1 1 1 0 Running 99s v1.23.3
Our second deployment uses the same underlying MachineDeployment class default-worker as our initial deployment. In this case they will both have exactly the same underlying machine templates. In order to modify the templates MachineDeployments are based on take a look at Changing a ClusterClass .
A similar process as that described here - removing the MachineDeployment from cluster.spec.topology.workers.machineDeployments - can be used to delete a running MachineDeployment from an active Cluster.
When using a managed topology scaling of ControlPlane Machines, where the Cluster is using a topology that includes ControlPlane MachineInfrastructure, should be done through the Cluster topology.
This is done by changing the ControlPlane replicas field at /spec/topology/controlPlane/replica in the Cluster object. The command is:
kubectl patch cluster capi-quickstart --type json --patch '[{"op": "replace", "path": "/spec/topology/controlPlane/replicas", "value": 1}]'
This patch will make the below changes on the Cluster yaml:
spec:
topology:
controlPlane:
metadata: {}
+ replicas: 1
- replicas: 3
As well as scaling a ControlPlane, Cluster operators can edit the labels and annotations applied to a running ControlPlane using the Cluster topology as a single point of control.
A ClusterClass can use variables and patches in order to allow flexible customization of Clusters derived from a ClusterClass. Variable definition allows two or more Cluster topologies derived from the same ClusterClass to have different specs, with the differences controlled by variables in the Cluster topology.
Assume we have created a CAPD cluster with ClusterClass and Kubernetes v1.23.3 (as documented in the Quick Start guide ). Our Cluster has a variable etcdImageTag as defined in the ClusterClass. The variable is not set on our Cluster. Some variables, depending on their definition in a ClusterClass, may need to be specified by the Cluster operator for every Cluster created using a given ClusterClass.
In order to specify the value of a variable all we have to do is set the value in the Cluster topology.
We can see the current unset variable with:
kubectl get cluster capi-quickstart -o jsonpath='{.spec.topology.variables[1]}'
Which will return something like:
{"name":"etcdImageTag","value":""}
In order to run a different version of etcd in new ControlPlane machines - the part of the spec this variable sets - change the value using the below patch:
kubectl patch cluster capi-quickstart --type json --patch '[{"op": "replace", "path": "/spec/topology/variables/1/value", "value": "3.5.0"}]'
Running the patch makes the following change to the Cluster yaml:
spec:
topology:
variables:
- name: imageRepository
value: registry.k8s.io
- name: etcdImageTag
value: ""
- name: coreDNSImageTag
+ value: "3.5.0"
- value: ""
Retrieving the variable value from the Cluster object, with kubectl get cluster capi-quickstart -o jsonpath='{.spec.topology.variables[1]}' we can see:
{"name":"etcdImageTag","value":"3.5.0"}
Note: Changing the etcd version may have unintended impacts on a running Cluster. For safety the cluster should be reapplied after running the above variable patch.
To perform more significant changes using a Cluster as a single point of control, it may be necessary to change the ClusterClass that the Cluster is based on. This is done by changing the class referenced in /spec/topology/class.
To read more about changing an underlying class please refer to ClusterClass rebase .
Users should always aim at ensuring the stability of the Cluster and of the applications hosted on it while
using spec.topology as a single point of control for making changes to the objects that are part of the Cluster.
Following recommendation apply:
If possible, avoid concurrent changes to control-plane and/or MachineDeployments to prevent
excessive turnover on the underlying infrastructure or bottlenecks in the Cluster trying to move workloads
from one machine to the other.
Keep machine labels and annotation stable, because changing those values requires machines rollouts;
also, please note that machine labels and annotation are not propagated to Kubernetes nodes; see
metadata propagation .
While upgrading a Cluster, if possible avoid any other concurrent change to the Cluster; please note
that you can rely on version-aware patches to ensure
the Cluster adapts to the new Kubernetes version in sync with the upgrade workflow.
For more details about how changes can affect a Cluster, please look at reference .
When applying concurrent changes to a Cluster, the topology controller will immediately act in order to
reconcile to the desired state, and thus proxy all the required changes to the underlying objects which
in turn take action, and this might require rolling out machines (create new, delete old).
As noted above, when executed at scale this might create excessive turnover on the underlying infrastructure
or bottlenecks in the Cluster trying to move workloads from one machine to the other.
Additionally, in case of change of the Kubernetes version and other concurrent changes for Machines deployments
this could lead to double rollout of the worker nodes:
The first rollout triggered by the changes to the machine deployments immediately applied to the underlying objects
(e.g change of labels).
The second rollout triggered by the upgrade workflow changing the MachineDeployment version only after the control
upgrade is completed (see upgrade a cluster above).
Please note that:
Cluster API already implements strategies to ensure changes in a Cluster are executed in a safe way under
most of the circumstances, including users occasionally not acting according to above best practices;
The above-mentioned strategies are currently implemented on the abstraction controlling a single set of machines,
the control-plane (KCP) or the MachineDeployment;
In future Managed topologies could be improved by introducing strategies to ensure a higher safety across all
abstraction controlling Machines in a Cluster, but this work is currently at its initial stage and user feedback
could help in shaping out those improvements.
Similarly, in future we might consider implementing strategies to controlling changes across many Clusters.
There are some special considerations for ClusterClass regarding Cluster API upgrades when the upgrade includes a bump
of the apiVersion of infrastructure, bootstrap or control plane provider CRDs.
The recommended approach is to first upgrade Cluster API and then update the apiVersions in the ClusterClass references afterwards.
By following above steps, there won’t be any disruptions of the reconciliation as the Cluster topology controller is able to reconcile the Cluster
even with the old apiVersions in the ClusterClass.
Note: The apiVersions in ClusterClass cannot be updated before Cluster API because the new apiVersions don’t exist in
the management cluster before the Cluster API upgrade.
In general the Cluster topology controller always uses exactly the versions of the CRDs referenced in the ClusterClass.
This means in the following example the Cluster topology controller will always use v1beta1 when reconciling/applying
patches for the infrastructure ref, even if the DockerClusterTemplate already has a v1beta2 apiVersion.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: quick-start
namespace: default
spec:
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerClusterTemplate
...
When upgrading the apiVersions in references in the ClusterClass the corresponding patches have to be changed accordingly.
This includes bumping the apiVersion in the patch selector and potentially updating the JSON patch to changes in the new
apiVersion of the referenced CRD. The following example shows how to upgrade the ClusterClass in this case.
ClusterClass with the old apiVersion:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: quick-start
spec:
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerClusterTemplate
...
patches:
- name: lbImageRepository
definitions:
- selector:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerClusterTemplate
matchResources:
infrastructureCluster: true
jsonPatches:
- op: add
path: "/spec/template/spec/loadBalancer/imageRepository"
valueFrom:
variable: lbImageRepository
ClusterClass with the new apiVersion:
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: quick-start
spec:
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta2 # apiVersion updated
kind: DockerClusterTemplate
...
patches:
- name: lbImageRepository
definitions:
- selector:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta2 # apiVersion updated
kind: DockerClusterTemplate
matchResources:
infrastructureCluster: true
jsonPatches:
- op: add
# Path has been updated, as in this example imageRepository has been renamed
# to imageRepo in v1beta2 of DockerClusterTemplate.
path: "/spec/template/spec/loadBalancer/imageRepo"
valueFrom:
variable: lbImageRepository
If external patches are used in the ClusterClass, it has to be ensured that all external patches support the new apiVersion
before bumping apiVersions.
The Runtime SDK feature provides an extensibility mechanism that allows systems, products, and services built on top of Cluster API to hook into a workload cluster’s lifecycle.
Please note Runtime SDK is an advanced feature. If implemented incorrectly, a failing Runtime Extension can severely impact the Cluster API runtime.
Feature gate name : RuntimeSDK
Variable name to enable/disable the feature gate : EXP_RUNTIME_SDK
Additional documentation:
Background information:
For Runtime Extension developers:
For Cluster operators:
Please note Runtime SDK is an advanced feature. If implemented incorrectly, a failing Runtime Extension can severely impact the Cluster API runtime.
As a developer building systems on top of Cluster API, if you want to hook into the Cluster’s lifecycle via
a Runtime Hook, you have to implement a Runtime Extension handling requests according to the
OpenAPI specification for the Runtime Hook you are interested in.
Runtime Extensions by design are very powerful and flexible, however given that with great power comes
great responsibility, a few key consideration should always be kept in mind (more details in the following sections):
Runtime Extensions are components that should be designed, written and deployed with great caution given that they
can affect the proper functioning of the Cluster API runtime.
Cluster administrators should carefully vet any Runtime Extension registration, thus preventing malicious components
from being added to the system.
Please note that following similar practices is already commonly accepted in the Kubernetes ecosystem for
Kubernetes API server admission webhooks. Runtime Extensions share the same foundation and most of the same
considerations/concerns apply.
As mentioned above as a developer building systems on top of Cluster API, if you want to hook in the Cluster’s
lifecycle via a Runtime Extension, you have to implement an HTTPS server handling a discovery request and a set
of additional requests according to the OpenAPI specification for the Runtime Hook you are interested in.
The following shows a minimal example of a Runtime Extension server implementation:
package main
import (
"context"
"flag"
"net/http"
"os"
"github.com/spf13/pflag"
cliflag "k8s.io/component-base/cli/flag"
"k8s.io/component-base/logs"
logsv1 "k8s.io/component-base/logs/api/v1"
"k8s.io/klog/v2"
ctrl "sigs.k8s.io/controller-runtime"
runtimecatalog "sigs.k8s.io/cluster-api/exp/runtime/catalog"
runtimehooksv1 "sigs.k8s.io/cluster-api/exp/runtime/hooks/api/v1alpha1"
"sigs.k8s.io/cluster-api/exp/runtime/server"
)
var (
// catalog contains all information about RuntimeHooks.
catalog = runtimecatalog.New()
// Flags.
profilerAddress string
webhookPort int
webhookCertDir string
logOptions = logs.NewOptions()
)
func init() {
// Adds to the catalog all the RuntimeHooks defined in cluster API.
_ = runtimehooksv1.AddToCatalog(catalog)
}
// InitFlags initializes the flags.
func InitFlags(fs *pflag.FlagSet) {
// Initialize logs flags using Kubernetes component-base machinery.
logsv1.AddFlags(logOptions, fs)
// Add test-extension specific flags
fs.StringVar(&profilerAddress, "profiler-address", "",
"Bind address to expose the pprof profiler (e.g. localhost:6060)")
fs.IntVar(&webhookPort, "webhook-port", 9443,
"Webhook Server port")
fs.StringVar(&webhookCertDir, "webhook-cert-dir", "/tmp/k8s-webhook-server/serving-certs/",
"Webhook cert dir.")
}
func main() {
// Creates a logger to be used during the main func.
setupLog := ctrl.Log.WithName("setup")
// Initialize and parse command line flags.
InitFlags(pflag.CommandLine)
pflag.CommandLine.SetNormalizeFunc(cliflag.WordSepNormalizeFunc)
pflag.CommandLine.AddGoFlagSet(flag.CommandLine)
// Set log level 2 as default.
if err := pflag.CommandLine.Set("v", "2"); err != nil {
setupLog.Error(err, "failed to set default log level")
os.Exit(1)
}
pflag.Parse()
// Validates logs flags using Kubernetes component-base machinery and applies them
if err := logsv1.ValidateAndApply(logOptions, nil); err != nil {
setupLog.Error(err, "unable to start extension")
os.Exit(1)
}
// Add the klog logger in the context.
ctrl.SetLogger(klog.Background())
// Initialize the golang profiler server, if required.
if profilerAddress != "" {
klog.Infof("Profiler listening for requests at %s", profilerAddress)
go func() {
klog.Info(http.ListenAndServe(profilerAddress, nil))
}()
}
// Create a http server for serving runtime extensions
webhookServer, err := server.New(server.Options{
Catalog: catalog,
Port: webhookPort,
CertDir: webhookCertDir,
})
if err != nil {
setupLog.Error(err, "error creating webhook server")
os.Exit(1)
}
// Register extension handlers.
if err := webhookServer.AddExtensionHandler(server.ExtensionHandler{
Hook: runtimehooksv1.BeforeClusterCreate,
Name: "before-cluster-create",
HandlerFunc: DoBeforeClusterCreate,
}); err != nil {
setupLog.Error(err, "error adding handler")
os.Exit(1)
}
if err := webhookServer.AddExtensionHandler(server.ExtensionHandler{
Hook: runtimehooksv1.BeforeClusterUpgrade,
Name: "before-cluster-upgrade",
HandlerFunc: DoBeforeClusterUpgrade,
}); err != nil {
setupLog.Error(err, "error adding handler")
os.Exit(1)
}
// Setup a context listening for SIGINT.
ctx := ctrl.SetupSignalHandler()
// Start the https server.
setupLog.Info("Starting Runtime Extension server")
if err := webhookServer.Start(ctx); err != nil {
setupLog.Error(err, "error running webhook server")
os.Exit(1)
}
}
func DoBeforeClusterCreate(ctx context.Context, request *runtimehooksv1.BeforeClusterCreateRequest, response *runtimehooksv1.BeforeClusterCreateResponse) {
log := ctrl.LoggerFrom(ctx)
log.Info("BeforeClusterCreate is called")
// Your implementation
}
func DoBeforeClusterUpgrade(ctx context.Context, request *runtimehooksv1.BeforeClusterUpgradeRequest, response *runtimehooksv1.BeforeClusterUpgradeResponse) {
log := ctrl.LoggerFrom(ctx)
log.Info("BeforeClusterUpgrade is called")
// Your implementation
}
For a full example see our test extension .
Please note that a Runtime Extension server can serve multiple Runtime Hooks (in the example above
BeforeClusterCreate and BeforeClusterUpgrade) at the same time. Each of them are handled at a different path, like the
Kubernetes API server does for different API resources. The exact format of those paths is handled by the server
automatically in accordance to the OpenAPI specification of the Runtime Hooks.
There is an additional Discovery endpoint which is automatically served by the Server. The Discovery endpoint
returns a list of extension handlers to inform Cluster API which Runtime Hooks are implemented by this
Runtime Extension server.
Please note that Cluster API is only able to enforce the correct request and response types as defined by a Runtime Hook version.
Developers are fully responsible for all other elements of the design of a Runtime Extension implementation, including:
To choose which programming language to use; please note that Golang is the language of choice, and we are not planning
to test or provide tooling and libraries for other languages. Nevertheless, given that we rely on Open API and plain
HTTPS calls, other languages should just work but support will be provided at best effort.
To choose if a dedicated or a shared HTTPS Server is used for the Runtime Extension (it can be e.g. also used to serve a
metric endpoint).
When using Golang the Runtime Extension developer can benefit from the following packages (provided by the
sigs.k8s.io/cluster-api module) as shown in the example above:
exp/runtime/hooks/api/v1alpha1 contains the Runtime Hook Golang API types, which are also used to generate the
OpenAPI specification.exp/runtime/catalog provides the Catalog object to register Runtime Hook definitions. The Catalog is then
used by the server package to handle requests. Catalog is similar to the runtime.Scheme of the
k8s.io/apimachinery/pkg/runtime package, but it is designed to store Runtime Hook registrations.exp/runtime/server provides a Server object which makes it easy to implement a Runtime Extension server.
The Server will automatically handle tasks like Marshalling/Unmarshalling requests and responses. A Runtime
Extension developer only has to implement a strongly typed function that contains the actual logic.
While writing a Runtime Extension the following important guidelines must be considered:
Runtime Extension processing adds to reconcile durations of Cluster API controllers. They should respond to requests
as quickly as possible, typically in milliseconds. Runtime Extension developers can decide how long the Cluster API Runtime
should wait for a Runtime Extension to respond before treating the call as a failure (max is 30s) by returning the timeout
during discovery. Of course a Runtime Extension can trigger long-running tasks in the background, but they shouldn’t block
synchronously.
Runtime Extension failure could result in errors in handling the workload clusters lifecycle, and so the implementation
should be robust, have proper error handling, avoid panics, etc. Failure policies can be set up to mitigate the
negative impact of a Runtime Extension on the Cluster API Runtime, but this option can’t be used in all cases
(see Error Management ).
A Runtime Hook can be defined as “blocking” - e.g. the BeforeClusterUpgrade hook allows a Runtime Extension
to prevent the upgrade from starting. A Runtime Extension registered for the BeforeClusterUpgrade hook
can block by returning a non-zero retryAfterSeconds value. Following consideration apply:
The system might decide to retry the same Runtime Extension even before the retryAfterSeconds period expires,
e.g. due to other changes in the Cluster, so retryAfterSeconds should be considered as an approximate maximum
time before the next reconcile.
If there is more than one Runtime Extension registered for the same Runtime Hook and more than one returns
retryAfterSeconds, the shortest non-zero value will be used.
If there is more than one Runtime Extension registered for the same Runtime Hook and at least one returns
retryAfterSeconds, all Runtime Extensions will be called again.
Detailed description of what “blocking” means for each specific Runtime Hooks is documented case by case
in the hook-specific implementation documentation (e.g. Implementing Lifecycle Hook Runtime Extensions ).
It is recommended that Runtime Extensions should avoid side effects if possible, which means they should operate
only on the content of the request sent to them, and not make out-of-band changes. If side effects are required,
rules defined in the following sections apply.
An idempotent Runtime Extension is able to succeed even in case it has already been completed before (the Runtime
Extension checks current state and changes it only if necessary). This is necessary because a Runtime Extension
may be called many times after it already succeeded because other Runtime Extensions for the same hook may not
succeed in the same reconcile.
A practical example that explains why idempotence is relevant is the fact that extensions could be called more
than once for the same lifecycle transition, e.g.
Two Runtime Extensions are registered for the BeforeClusterUpgrade hook.
Before a Cluster upgrade is started both extensions are called, but one of them temporarily blocks the operation
by asking to retry after 30 seconds.
After 30 seconds the system retries the lifecycle transition, and both extensions are called again to re-evaluate
if it is now possible to proceed with the Cluster upgrade.
Each Runtime Extension should accomplish its task without depending on other Runtime Extensions. Introducing
dependencies across Runtime Extensions makes the system fragile, and it is probably a consequence of poor
“Separation of Concerns” between extensions.
A deterministic Runtime Extension is implemented in such a way that given the same input it will always return
the same output.
Some Runtime Hooks, e.g. like external patches, might explicitly request for corresponding Runtime Extensions
to support this property. But we encourage developers to follow this pattern more generally given that it fits
well with practices like unit testing and generally makes the entire system more predictable and easier to troubleshoot.
RuntimeExtension authors should be aware that error messages are surfaced as a conditions in Kubernetes resources
and recorded in Cluster API controller’s logs. As a consequence:
Error message must not contain any sensitive information.
Error message must be deterministic, and must avoid to including timestamps or values changing at every call.
Error message must not contain external errors when it’s not clear if those errors are deterministic (e.g. errors return from cloud APIs).
If an error message is not deterministic and it changes at every call even if the problem is the same, it could
lead to to Kubernetes resources conditions continuously changing, and this generates a denial attack to
controllers processing those resource that might impact system stability.
To register your runtime extension apply the ExtensionConfig resource in the management cluster, including your CA
certs, ClusterIP service associated with the app and namespace, and the target namespace for the given extension. Once
created, the extension will detect the associated service and discover the associated Hooks. For clarification, you can
check the status of the ExtensionConfig. Below is an example of ExtensionConfig -
apiVersion: runtime.cluster.x-k8s.io/v1alpha1
kind: ExtensionConfig
metadata:
annotations:
runtime.cluster.x-k8s.io/inject-ca-from-secret: default/test-runtime-sdk-svc-cert
name: test-runtime-sdk-extensionconfig
spec:
clientConfig:
service:
name: test-runtime-sdk-svc
namespace: default # Note: this assumes the test extension get deployed in the default namespace
port: 443
namespaceSelector:
matchExpressions:
- key: kubernetes.io/metadata.name
operator: In
values:
- default # Note: this assumes the test extension is used by Cluster in the default namespace only
Settings can be added to the ExtensionConfig object in the form of a map with string keys and values. These settings are
sent with each request to hooks registered by that ExtensionConfig. Extension developers can implement behavior in their
extensions to alter behavior based on these settings. Settings should be well documented by extension developers so that
ClusterClass authors can understand usage and expected behaviour.
Settings can be provided for individual external patches by providing them in the ClusterClass .spec.patches[*].external.settings.
This can be used to overwrite settings at the ExtensionConfig level for that patch.
In case a Runtime Extension returns an error, the error will be handled according to the corresponding failure policy
defined in the response of the Discovery call.
If the failure policy is Ignore the error is going to be recorded in the controller’s logs, but the processing
will continue. However we recognize that this failure policy cannot be used in most of the use cases because Runtime
Extension implementers want to ensure that the task implemented by an extension is completed before continuing with
the cluster’s lifecycle.
If instead the failure policy is Fail the system will retry the operation until it passes. The following general
considerations apply:
It is the responsibility of Cluster API components to surface Runtime Extension errors using conditions.
Operations will be retried with an exponential backoff or whenever the state of a Cluster changes (we are going to rely
on controller runtime exponential backoff/watches).
If there is more than one Runtime Extension registered for the same Runtime Hook and at least one of them fails,
all the registered Runtime Extension will be retried. See Idempotence
Additional considerations about errors that apply only to a specific Runtime Hook will be documented in the hook-specific
implementation documentation.
After you implemented and deployed a Runtime Extension you can manually test it by sending HTTP requests.
This can be for example done via kubectl:
Via kubectl create --raw:
# Send a Discovery Request to the webhook-service in namespace default with protocol https on port 443:
kubectl create --raw '/api/v1/namespaces/default/services/https:webhook-service:443/proxy/hooks.runtime.cluster.x-k8s.io/v1alpha1/discovery' \
-f <(echo '{"apiVersion":"hooks.runtime.cluster.x-k8s.io/v1alpha1","kind":"DiscoveryRequest"}') | jq
Via kubectl proxy and curl:
# Open a proxy with kubectl and then use curl to send the request
## First terminal:
kubectl proxy
## Second terminal:
curl -X 'POST' 'http://127.0.0.1:8001/api/v1/namespaces/default/services/https:webhook-service:443/proxy/hooks.runtime.cluster.x-k8s.io/v1alpha1/discovery' \
-d '{"apiVersion":"hooks.runtime.cluster.x-k8s.io/v1alpha1","kind":"DiscoveryRequest"}' | jq
For more details about the API of the Runtime Extensions please see Swagger UI .
For more details on proxy support please see Proxies in Kubernetes .
Please note Runtime SDK is an advanced feature. If implemented incorrectly, a failing Runtime Extension can severely impact the Cluster API runtime.
The lifecycle hooks allow hooking into the Cluster lifecycle. The following diagram provides an overview:
Please see the corresponding CAEP
for additional background information.
All guidelines defined in Implementing Runtime Extensions apply to the
implementation of Runtime Extensions for lifecycle hooks as well.
In summary, Runtime Extensions are components that should be designed, written and deployed with great caution given
that they can affect the proper functioning of the Cluster API runtime. A poorly implemented Runtime Extension could
potentially block lifecycle transitions from happening.
Following recommendations are especially relevant:
This hook is called after the Cluster object has been created by the user, immediately before all the objects which
are part of a Cluster topology(*) are going to be created. Runtime Extension implementers can use this hook to
determine/prepare add-ons for the Cluster and block the creation of those objects until everything is ready.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: BeforeClusterCreateRequest
settings: <Runtime Extension settings>
cluster:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: test-cluster
namespace: test-ns
spec:
...
status:
...
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: BeforeClusterCreateResponse
status: Success # or Failure
message: "error message if status == Failure"
retryAfterSeconds: 10
For additional details, you can see the full schema in Swagger UI .
(*) The objects which are part of a Cluster topology are the infrastructure Cluster, the Control Plane, the
MachineDeployments and the templates derived from the ClusterClass.
This hook is called after the Control Plane for the Cluster is marked as available for the first time. Runtime Extension
implementers can use this hook to execute tasks, for example component installation on workload clusters, that are only
possible once the Control Plane is available. This hook does not block any further changes to the Cluster.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: AfterControlPlaneInitializedRequest
settings: <Runtime Extension settings>
cluster:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: test-cluster
namespace: test-ns
spec:
...
status:
...
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: AfterControlPlaneInitializedResponse
status: Success # or Failure
message: "error message if status == Failure"
For additional details, you can see the full schema in Swagger UI .
This hook is called after the Cluster object has been updated with a new spec.topology.version by the user, and
immediately before the new version is going to be propagated to the control plane (*). Runtime Extension implementers
can use this hook to execute pre-upgrade add-on tasks and block upgrades of the ControlPlane and Workers.
Note: While the upgrade is blocked changes made to the Cluster Topology will be delayed propagating to the underlying
objects while the object is waiting for upgrade. Example: modifying ControlPlane/MachineDeployments (think scale up),
or creating new MachineDeployments will be delayed until the target ControlPlane/MachineDeployment is ready to pick up the upgrade.
This ensures that the ControlPlane and MachineDeployments do not perform a rollout prematurely while waiting to be rolled out again for the version upgrade (no double rollouts).
This also ensures that any version specific changes are only pushed to the underlying objects also at the correct version.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: BeforeClusterUpgradeRequest
settings: <Runtime Extension settings>
cluster:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: test-cluster
namespace: test-ns
spec:
...
status:
...
fromKubernetesVersion: "v1.21.2"
toKubernetesVersion: "v1.22.0"
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: BeforeClusterUpgradeResponse
status: Success # or Failure
message: "error message if status == Failure"
retryAfterSeconds: 10
For additional details, you can see the full schema in Swagger UI .
(*) Under normal circumstances spec.topology.version gets propagated to the control plane immediately; however
if previous upgrades or worker machine rollouts are still in progress, the system waits for those operations
to complete before starting the new upgrade.
This hook is called after the control plane has been upgraded to the version specified in spec.topology.version,
and immediately before the new version is going to be propagated to the MachineDeployments of the Cluster.
Runtime Extension implementers can use this hook to execute post-upgrade add-on tasks and block upgrades to workers
until everything is ready.
Note: While the MachineDeployments upgrade is blocked changes made to existing MachineDeployments and creating new MachineDeployments
will be delayed while the object is waiting for upgrade. Example: modifying MachineDeployments (think scale up),
or creating new MachineDeployments will be delayed until the target MachineDeployment is ready to pick up the upgrade.
This ensures that the MachineDeployments do not perform a rollout prematurely while waiting to be rolled out again for the version upgrade (no double rollouts).
This also ensures that any version specific changes are only pushed to the underlying objects also at the correct version.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: AfterControlPlaneUpgradeRequest
settings: <Runtime Extension settings>
cluster:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: test-cluster
namespace: test-ns
spec:
...
status:
...
kubernetesVersion: "v1.22.0"
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: AfterControlPlaneUpgradeResponse
status: Success # or Failure
message: "error message if status == Failure"
retryAfterSeconds: 10
For additional details, you can see the full schema in Swagger UI .
This hook is called after the Cluster, control plane and workers have been upgraded to the version specified in
spec.topology.version. Runtime Extensions implementers can use this hook to execute post-upgrade add-on tasks.
This hook does not block any further changes or upgrades to the Cluster.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: AfterClusterUpgradeRequest
settings: <Runtime Extension settings>
cluster:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: test-cluster
namespace: test-ns
spec:
...
status:
...
kubernetesVersion: "v1.22.0"
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: AfterClusterUpgradeResponse
status: Success # or Failure
message: "error message if status == Failure"
For additional details, refer to the Draft OpenAPI spec .
This hook is called after the Cluster deletion has been triggered by the user and immediately before the topology
of the Cluster is going to be deleted. Runtime Extension implementers can use this hook to execute
cleanup tasks for the add-ons and block deletion of the Cluster and descendant objects until everything is ready.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: BeforeClusterDeleteRequest
settings: <Runtime Extension settings>
cluster:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: test-cluster
namespace: test-ns
spec:
...
status:
...
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: BeforeClusterDeleteResponse
status: Success # or Failure
message: "error message if status == Failure"
retryAfterSeconds: 10
For additional details, you can see the full schema in Swagger UI .
Please note Runtime SDK is an advanced feature. If implemented incorrectly, a failing Runtime Extension can severely impact the Cluster API runtime.
Three different hooks are called as part of Topology Mutation - two in the Cluster topology reconciler and one in the ClusterClass reconciler.
Cluster topology reconciliation
GeneratePatches : GeneratePatches is responsible for generating patches for the entire Cluster topology.ValidateTopology : ValidateTopology is called after all patches have been applied and thus allow to validate
the resulting objects.
ClusterClass reconciliation
DiscoverVariables : DiscoverVariables is responsible for providing variable definitions for a specific external patch.
Please see the corresponding CAEP
for additional background information.
Inline patches have the following advantages:
Inline patches are easier when getting started with ClusterClass as they are built into
the Cluster API core controller, no external component have to be developed and managed.
External patches have the following advantages:
External patches can be individually written, unit tested and released/versioned.
External patches can leverage the full feature set of a programming language and
are thus not limited to the capabilities of JSON patches and Go templating.
External patches can use external data (e.g. from cloud APIs) during patch generation.
External patches can be easily reused across ClusterClasses.
The DiscoverVariables hook can be used to supply variable definitions for use in external patches. These variable definitions are added to
the status of any applicable ClusterClasses. Clusters using the ClusterClass can then set values for those variables.
External variable definitions are discovered by calling the DiscoverVariables runtime hook. This hook is called from the ClusterClass reconciler.
Once discovered the variable definitions are validated and stored in ClusterClass status.
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
# metadata
spec:
# Inline variable definitions
variables:
# This variable is unique and can be accessed globally.
- name: no-proxy
required: true
schema:
openAPIV3Schema:
type: string
default: "internal.com"
example: "internal.com"
description: "comma-separated list of machine or domain names excluded from using the proxy."
# This variable is also defined by an external DiscoverVariables hook.
- name: http-proxy
schema:
openAPIV3Schema:
type: string
default: "proxy.example.com"
example: "proxy.example.com"
description: "proxy for http calls."
# External patch definitions.
patches:
- name: lbImageRepository
external:
generateExtension: generate-patches.k8s-upgrade-with-runtimesdk
validateExtension: validate-topology.k8s-upgrade-with-runtimesdk
## Call variable discovery for this patch.
discoverVariablesExtension: discover-variables.k8s-upgrade-with-runtimesdk
status:
# observedGeneration is used to check that the current version of the ClusterClass is the same as that when the Status was previously written.
# if metadata.generation isn't the same as observedGeneration Cluster using the ClusterClass should not reconcile.
observedGeneration: xx
# variables contains a list of all variable definitions, both inline and from external patches, that belong to the ClusterClass.
variables:
- name: no-proxy
definitions:
- from: inline
required: true
schema:
openAPIV3Schema:
type: string
default: "internal.com"
example: "internal.com"
description: "comma-separated list of machine or domain names excluded from using the proxy."
- name: http-proxy
# definitionsConflict is true if there are non-equal definitions for a variable.
definitionsConflict: true
definitions:
- from: inline
schema:
openAPIV3Schema:
type: string
default: "proxy.example.com"
example: "proxy.example.com"
description: "proxy for http calls."
- from: lbImageRepository
schema:
openAPIV3Schema:
type: string
default: "different.example.com"
example: "different.example.com"
description: "proxy for http calls."
Variable definitions can be inline in the ClusterClass or from any number of external DiscoverVariables hooks. The source
of a variable definition is recorded in the from field in ClusterClass .status.variables.
Variables that are defined by an external DiscoverVariables hook will have the name of the patch they are associated with as the value of from.
Variables that are defined in the ClusterClass .spec.variables will have inline as the value of from.
Note: inline is a reserved name for patches. It cannot be used as the name of an external patch to avoid conflicts.
If all variables that share a name have equivalent schemas the variable definitions are not in conflict. These variables can
be set without providing definitionFrom value - see below . The CAPI components will
consider variable definitions to be equivalent when they share a name and their schema is exactly equal.
Setting variables that are defined with external variable definitions requires attention to be paid to variable definition conflicts, as exposed in the ClusterClass status.
Variable values are set in Cluster .spec.topology.variables.
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
#metadata
spec:
topology:
variables:
# `definitionFrom` is not needed as this variable does not have conflicting definitions.
- name: no-proxy
value: "internal.domain.com"
# variables with the same name but different definitions require values for each individual schema.
- name: http-proxy
definitionFrom: inline
value: http://proxy.example2.com:1234
- name: http-proxy
definitionFrom: lbImageRepository
value:
host: proxy.example2.com
port: 1234
Some considerations:
In general a single external patch extension is simpler than many, as only one extension
then has to be built, deployed and managed.
A single extension also requires less HTTP round-trips between the CAPI controller and the extension(s).
With a single extension it is still possible to implement multiple logical features using different variables.
When implementing multiple logical features in one extension it’s recommended that they can be conditionally
enabled/disabled via variables (either via certain values or by their existence).
Conway’s law might make it not feasible in large organizations
to use a single extension. In those cases it’s important that boundaries between extensions are clearly defined.
For general Runtime Extension developer guidelines please refer to the guidelines in Implementing Runtime Extensions .
This section outlines considerations specific to Topology Mutation hooks.
Input validation : An External Patch Extension must always validate its input, i.e. it must validate that
all variables exist, have the right type and it must validate the kind and apiVersion of the templates which
should be patched.Timeouts : As External Patch Extensions are called during each Cluster topology reconciliation, they must
respond as fast as possible (<=200ms) to avoid delaying individual reconciles and congestion.Availability : An External Patch Extension must be always available, otherwise Cluster topologies won’t be
reconciled anymore.Side Effects : An External Patch Extension must not make out-of-band changes. If necessary external data can
be retrieved, but be aware of performance impact.Deterministic results : For a given request (a set of templates and variables) an External Patch Extension must
always return the same response (a set of patches). Otherwise the Cluster topology will never reach a stable state.Idempotence : An External Patch Extension must only return patches if changes to the templates are required,
i.e. unnecessary patches when the template is already in the desired state must be avoided.Avoid Dependencies : An External Patch Extension must be independent of other External Patch Extensions. However
if dependencies cannot be avoided, it is possible to control the order in which patches are executed via the ClusterClass.Error messages : For a given request (a set of templates and variables) an External Patch Extension must
always return the same error message. Otherwise the system might become unstable due to controllers being overloaded
by continuous changes to Kubernetes resources as these messages are reported as conditions. See error messages .
Distinctive variable names : Names should be carefully chosen, and if possible generic names should be avoided.
Using a generic name could lead to conflicts if the variables defined for this patch are used in combination with other
patches providing variables with the same name.Avoid breaking changes to variable definitions : Changing a variable definition can lead to problems on existing
clusters because reconciliation will stop if variable values do not match the updated definition. When more than one variable
with the same name is defined, changes to variable definitions can require explicit values for each patch.
Updates to the variable definition should be carefully evaluated, and very well documented in extension release notes,
so ClusterClass authors can evaluate impacts of changes before performing an upgrade.
A GeneratePatches call generates patches for the entire Cluster topology. Accordingly the request contains all
templates, the global variables and the template-specific variables. The response contains generated patches.
Generating patches for a Cluster topology is done via a single call to allow External Patch Extensions a
holistic view of the entire Cluster topology. Additionally this allows us to reduce the number of round-trips.
Each item in the request will contain the template as a raw object. Additionally information about where
the template is used is provided via holderReference.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: GeneratePatchesRequest
settings: <Runtime Extension settings>
variables:
- name: <variable-name>
value: <variable-value>
...
items:
- uid: 7091de79-e26c-4af5-8be3-071bc4b102c9
holderReference:
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineDeployment
namespace: default
name: cluster-md1-xyz
fieldPath: spec.template.spec.infrastructureRef
object:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: AWSMachineTemplate
spec:
...
variables:
- name: <variable-name>
value: <variable-value>
...
The response contains patches instead of full objects to reduce the payload.
Templates in the request and patches in the response will be correlated via UIDs.
Like inline patches, external patches are only allowed to change fields in spec.template.spec.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: GeneratePatchesResponse
status: Success # or Failure
message: "error message if status == Failure"
items:
- uid: 7091de79-e26c-4af5-8be3-071bc4b102c9
patchType: JSONPatch
patch: <JSON-patch>
For additional details, you can see the full schema in Swagger UI .
We are considering to introduce a library to facilitate development of External Patch Extensions. It would provide capabilities like:
Accessing builtin variables
Extracting certain templates from a GeneratePatches request (e.g. all bootstrap templates)
If you are interested in contributing to this library please reach out to the maintainer team or
feel free to open an issue describing your idea or use case.
A ValidateTopology call validates the topology after all patches have been applied. The request contains all
templates of the Cluster topology, the global variables and the template-specific variables. The response
contains the result of the validation.
The request is the same as the GeneratePatches request except it doesn’t have uid fields. We don’t
need them as we don’t have to correlate patches in the response.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: ValidateTopologyRequest
settings: <Runtime Extension settings>
variables:
- name: <variable-name>
value: <variable-value>
...
items:
- holderReference:
apiVersion: cluster.x-k8s.io/v1beta1
kind: MachineDeployment
namespace: default
name: cluster-md1-xyz
fieldPath: spec.template.spec.infrastructureRef
object:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: AWSMachineTemplate
spec:
...
variables:
- name: <variable-name>
value: <variable-value>
...
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: ValidateTopologyResponse
status: Success # or Failure
message: "error message if status == Failure"
For additional details, you can see the full schema in Swagger UI .
A DiscoverVariables call returns definitions for one or more variables.
The request is a simple call to the Runtime hook.
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: DiscoverVariablesRequest
settings: <Runtime Extension settings>
apiVersion: hooks.runtime.cluster.x-k8s.io/v1alpha1
kind: DiscoverVariablesResponse
status: Success # or Failure
message: ""
variables:
- name: etcdImageTag
required: true
schema:
openAPIV3Schema:
type: string
default: "3.5.3-0"
example: "3.5.3-0"
description: "etcdImageTag sets the tag for the etcd image."
- name: preLoadImages
required: false
schema:
openAPIV3Schema:
default: []
type: array
items:
type: string
description: "preLoadImages sets the images for the Docker machines to preload."
- name: podSecurityStandard
required: false
schema:
openAPIV3Schema:
type: object
properties:
enabled:
type: boolean
default: true
description: "enabled enables the patches to enable Pod Security Standard via AdmissionConfiguration."
enforce:
type: string
default: "baseline"
description: "enforce sets the level for the enforce PodSecurityConfiguration mode. One of privileged, baseline, restricted."
audit:
type: string
default: "restricted"
description: "audit sets the level for the audit PodSecurityConfiguration mode. One of privileged, baseline, restricted."
warn:
type: string
default: "restricted"
description: "warn sets the level for the warn PodSecurityConfiguration mode. One of privileged, baseline, restricted."
...
For additional details, you can see the full schema in Swagger UI .
TODO: Add openAPI definition to the SwaggerUI
There are some special considerations regarding Cluster API upgrades when the upgrade includes a bump
of the apiVersion of infrastructure, bootstrap or control plane provider CRDs.
When calling external patches the Cluster topology controller is always sending the templates in the apiVersion of the references
in the ClusterClass.
While inline patches are always referring to one specific apiVersion, external patch implementations are more flexible. They can
be written in a way that they are able to handle multiple apiVersions of a CRD. This can be done by calculating patches differently
depending on which apiVersion is received by the external patch implementation.
This allows users more flexibility during Cluster API upgrades:
Variant 1: External patch implementation supporting two apiVersions at the same time
Update Cluster API
Update the external patch implementation to be able to handle custom resources with the old and the new apiVersion
Update the references in ClusterClasses to use the new apiVersion
Note In this variant it doesn’t matter if Cluster API or the external patch implementation is updated first.
Variant 2: Deploy an additional instance of the external patch implementation which can handle the new apiVersion
Upgrade Cluster API
Deploy the new external patch implementation which is able to handle the new apiVersion
Update ClusterClasses to use the new apiVersion and the new external patch implementation
Remove the old external patch implementation as it’s not used anymore
Note In this variant it doesn’t matter if Cluster API is updated or the new external patch implementation is deployed first.
Please note Runtime SDK is an advanced feature. If implemented incorrectly, a failing Runtime Extension can severely impact the Cluster API runtime.
Cluster API requires that each Runtime Extension must be deployed using an endpoint accessible from the Cluster API
controllers. The recommended deployment model is to deploy a Runtime Extension in the management cluster by:
Packing the Runtime Extension in a container image.
Using a Kubernetes Deployment to run the above container inside the Management Cluster.
Using a Cluster IP Service to make the Runtime Extension instances accessible via a stable DNS name.
Using a cert-manager generated Certificate to protect the endpoint.
Register the Runtime Extension using ExtensionConfig.
For an example, please see our test extension
which follows, as closely as possible, the kubebuilder setup used for controllers in Cluster API.
There are a set of important guidelines that must be considered while choosing the deployment method:
It is recommended that Runtime Extensions should leverage some form of load-balancing, to provide high availability
and performance benefits. You can run multiple Runtime Extension servers behind a Kubernetes Service to leverage the
load-balancing that services support.
The security model for each Runtime Extension should be carefully defined, similar to any other application deployed
in the Cluster. If the Runtime Extension requires access to the apiserver the deployment must use a dedicated service
account with limited RBAC permission. Otherwise no service account should be used.
On top of that, the container image for the Runtime Extension should be carefully designed in order to avoid
privilege escalation (e.g using distroless base images).
The Pod spec in the Deployment manifest should enforce security best practices (e.g. do not use privileged pods).
Alternative deployment methods can be used as long as the HTTPs endpoint is accessible, like e.g.:
deploying the HTTPS Server as a part of another component, e.g. a controller.
deploying the HTTPS Server outside the Management Cluster.
In those cases recommendations about availability and identity and access management still apply.
The default configuration engine for bootstrapping workload cluster machines is cloud-init . Ignition is an alternative engine used by Linux distributions such as Flatcar Container Linux and Fedora CoreOS and therefore should be used when choosing an Ignition-based distribution as the underlying OS for workload clusters.
This initial implementation uses Ignition v2 and was tested with Flatcar Container Linux only. Future releases are expected to add Ignition v3 support and cover more Linux distributions.
If using ignition with CAPD you should take care of setting kubeletExtraArgs for the kindest/node image in use,
because default CAPD templates do not include anymore those settings since when the cloud-init shim for CAPD is automatically taking care of this.
An example of how to set kubeletExtraArgs for the kindest/node can be found under cluster-api/test/e2e/data/infrastructure-docker/main/cluster-template-ignition.
Hopefully, this will be automated for Ignition too in a future release.
This guide explains how to deploy an AWS workload cluster using Ignition.
kubectl installed locallyclusterawsadm installed locally - download from the releases page of the AWS providerkind and Docker installed locally (when using kind to create a management cluster)
Follow this section of the quick start guide to deploy a Kubernetes cluster or connect to an existing one.
Follow this section of the quick start guide to install clusterctl.
Before workload clusters can be deployed, Cluster API components must be deployed to the management cluster.
Initialize the management cluster:
export AWS_REGION=us-east-1
export AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE
export AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
# Workload clusters need to call the AWS API as part of their normal operation.
# The following command creates a CloudFormation stack which provisions the
# necessary IAM resources to be used by workload clusters.
clusterawsadm bootstrap iam create-cloudformation-stack
# The management cluster needs to call the AWS API in order to manage cloud
# resources for workload clusters. The following command tells clusterctl to
# store the AWS credentials provided before in a Kubernetes secret where they
# can be retrieved by the AWS provider running on the management cluster.
export AWS_B64ENCODED_CREDENTIALS=$(clusterawsadm bootstrap credentials encode-as-profile)
# Enable the feature gates controlling Ignition bootstrap.
export EXP_KUBEADM_BOOTSTRAP_FORMAT_IGNITION=true # Used by the kubeadm bootstrap provider
export EXP_BOOTSTRAP_FORMAT_IGNITION=true # Used by the AWS provider
# Initialize the management cluster.
clusterctl init --infrastructure aws
# Deploy the workload cluster in the following AWS region.
export AWS_REGION=us-east-1
# Authorize the following SSH public key on cluster nodes.
export AWS_SSH_KEY_NAME=my-key
# Ignition bootstrap data needs to be stored in an S3 bucket so that nodes can
# read them at boot time. Store Ignition bootstrap data in the following bucket.
export AWS_S3_BUCKET_NAME=my-bucket
# Set the EC2 machine size for controllers and workers.
export AWS_CONTROL_PLANE_MACHINE_TYPE=t3a.small
export AWS_NODE_MACHINE_TYPE=t3a.small
clusterctl generate cluster ignition-cluster \
--from https://github.com/kubernetes-sigs/cluster-api-provider-aws/blob/main/templates/cluster-template-flatcar.yaml \
--kubernetes-version v1.28.0 \
--worker-machine-count 2 \
> ignition-cluster.yaml
NOTE: Only certain Kubernetes versions have pre-built Kubernetes AMIs. See list of published pre-built Kubernetes AMIs.
kubectl apply -f ignition-cluster.yaml
Wait for the control plane of the workload cluster to become initialized:
kubectl get kubeadmcontrolplane ignition-cluster-control-plane
This could take a while. When the control plane is initialized, the INITIALIZED field should be true:
NAME CLUSTER INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
ignition-cluster-control-plane ignition-cluster true 1 1 1 7m7s v1.22.2
Generate a kubeconfig for the workload cluster:
clusterctl get kubeconfig ignition-cluster > ./kubeconfig
Set kubectl to use the generated kubeconfig:
export KUBECONFIG=$(pwd)/kubeconfig
Verify connectivity with the workload cluster’s API server:
kubectl cluster-info
Sample output:
Kubernetes control plane is running at https://ignition-cluster-apiserver-284992524.us-east-1.elb.amazonaws.com:6443
CoreDNS is running at https://ignition-cluster-apiserver-284992524.us-east-1.elb.amazonaws.com:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
A CNI plugin must be deployed to the workload cluster for the cluster to become ready. We use Calico here, however other CNI plugins could be used, too.
kubectl apply -f https://docs.projectcalico.org/v3.20/manifests/calico.yaml
Ensure all cluster nodes become ready:
kubectl get nodes
Sample output:
NAME STATUS ROLES AGE VERSION
ip-10-0-122-154.us-east-1.compute.internal Ready control-plane,master 14m v1.22.2
ip-10-0-127-59.us-east-1.compute.internal Ready <none> 13m v1.22.2
ip-10-0-89-169.us-east-1.compute.internal Ready <none> 13m v1.22.2
Delete the workload cluster (from a shell connected to the management cluster):
kubectl delete cluster ignition-cluster
Cluster API has multiple infrastructure providers which can be used to deploy workload clusters.
The following infrastructure providers already have Ignition support:
Ignition support will be added to more providers in the future.
Cluster API supports running multiple infrastructure/bootstrap/control plane providers on the same management cluster. It’s highly recommended to rely on
clusterctl init command in this case. clusterctl will help ensure that all providers support the same
API Version of Cluster API (contract).
Currently, the case of running multiple providers is not covered in Cluster API E2E test suite. It’s recommended to set up a custom validation pipeline of
your specific combination of providers before deploying it on a production environment.
You will need to have the following tools installed:
Each release of the Cluster API project includes the following container images:
cluster-api-controller
kubeadm-bootstrap-controller
kubeadm-control-plane-controller
clusterctl
All of the four images are hosted by registry.k8s.io . In order to verify the authenticity of the images, you can use cosign verify command with the appropriate image name and version:
$ cosign verify registry.k8s.io/cluster-api/cluster-api-controller:v1.5.0 --certificate-identity krel-trust@k8s-releng-prod.iam.gserviceaccount.com --certificate-oidc-issuer https://accounts.google.com | jq .
Verification for registry.k8s.io/cluster-api/cluster-api-controller:v1.5.0 --
The following checks were performed on each of these signatures:
- The cosign claims were validated
- Existence of the claims in the transparency log was verified offline
- The code-signing certificate was verified using trusted certificate authority certificates
[
{
"critical": {
"identity": {
"docker-reference": "registry.k8s.io/cluster-api/cluster-api-controller"
},
"image": {
"docker-manifest-digest": "sha256:f34016d3a494f9544a16137c9bba49d8756c574a0a1baf96257903409ef82f77"
},
"type": "cosign container image signature"
},
"optional": {
"1.3.6.1.4.1.57264.1.1": "https://accounts.google.com",
"Bundle": {
"SignedEntryTimestamp": "MEYCIQDtxr/v3uRl2QByVfYo1oopruADSaH3E4wThpmkibJs8gIhAIe0odbk99na5GBdYGjJ6IwpFzhlTlicgWOrsgxZH8LC",
"Payload": {
"body": "eyJhcGlWZXJzaW9uIjoiMC4wLjEiLCJraW5kIjoiaGFzaGVkcmVrb3JkIiwic3BlYyI6eyJkYXRhIjp7Imhhc2giOnsiYWxnb3JpdGhtIjoic2hhMjU2IiwidmFsdWUiOiIzMDMzNzY0MTQwZmI2OTE5ZjRmNDg2MDgwMDZjYzY1ODU2M2RkNjE0NWExMzVhMzE5MmQyYTAzNjE1OTRjMTRlIn19LCJzaWduYXR1cmUiOnsiY29udGVudCI6Ik1FUUNJQ3RtcGdHN3RDcXNDYlk0VlpXNyt6Rm5tYWYzdjV4OTEwcWxlWGppdTFvbkFpQS9JUUVSSDErdit1a0hrTURSVnZnN1hPdXdqTTN4REFOdEZyS3NUMHFzaUE9PSIsInB1YmxpY0tleSI6eyJjb250ZW50IjoiTFMwdExTMUNSVWRKVGlCRFJWSlVTVVpKUTBGVVJTMHRMUzB0Q2sxSlNVTTJha05EUVc1SFowRjNTVUpCWjBsVldqYzNUbGRSV1VacmQwNTVRMk13Y25GWWJIcHlXa3RyYURjMGQwTm5XVWxMYjFwSmVtb3dSVUYzVFhjS1RucEZWazFDVFVkQk1WVkZRMmhOVFdNeWJHNWpNMUoyWTIxVmRWcEhWakpOVWpSM1NFRlpSRlpSVVVSRmVGWjZZVmRrZW1SSE9YbGFVekZ3WW01U2JBcGpiVEZzV2tkc2FHUkhWWGRJYUdOT1RXcE5kMDU2U1RGTlZHTjNUa1JOTlZkb1kwNU5hazEzVG5wSk1VMVVZM2hPUkUwMVYycEJRVTFHYTNkRmQxbElDa3R2V2tsNmFqQkRRVkZaU1V0dldrbDZhakJFUVZGalJGRm5RVVZ4VEdveFJsSmhLM2RZTUVNd0sxYzFTVlZWUW14UmRsWkNWM2xLWTFRcmFWaERjV01LWTA4d1prVmpNV2s0TVUxSFQwRk1lVXB2UXpGNk5TdHVaRGxFUnpaSGNFSmpOV0ZJYXpoU1QxaDBOV2h6U21wa1VVdFBRMEZhUVhkblowZE5UVUUwUndwQk1WVmtSSGRGUWk5M1VVVkJkMGxJWjBSQlZFSm5UbFpJVTFWRlJFUkJTMEpuWjNKQ1owVkdRbEZqUkVGNlFXUkNaMDVXU0ZFMFJVWm5VVlYxTVRoMENqWjVWMWxNVlU5RVR5dEVjek52VVU1RFNsYzNZMUJWZDBoM1dVUldVakJxUWtKbmQwWnZRVlV6T1ZCd2VqRlphMFZhWWpWeFRtcHdTMFpYYVhocE5Ga0tXa1E0ZDFGQldVUldVakJTUVZGSUwwSkVXWGRPU1VWNVlUTktiR0pETVRCamJsWjZaRVZDY2s5SVRYUmpiVlp6V2xjMWJreFlRbmxpTWxGMVlWZEdkQXBNYldSNldsaEtNbUZYVG14WlYwNXFZak5XZFdSRE5XcGlNakIzUzFGWlMwdDNXVUpDUVVkRWRucEJRa0ZSVVdKaFNGSXdZMGhOTmt4NU9XaFpNazUyQ21SWE5UQmplVFZ1WWpJNWJtSkhWWFZaTWpsMFRVTnpSME5wYzBkQlVWRkNaemM0ZDBGUlowVklVWGRpWVVoU01HTklUVFpNZVRsb1dUSk9kbVJYTlRBS1kzazFibUl5T1c1aVIxVjFXVEk1ZEUxSlIwdENaMjl5UW1kRlJVRmtXalZCWjFGRFFraDNSV1ZuUWpSQlNGbEJNMVF3ZDJGellraEZWRXBxUjFJMFl3cHRWMk16UVhGS1MxaHlhbVZRU3pNdmFEUndlV2RET0hBM2J6UkJRVUZIU21wblMxQmlkMEZCUWtGTlFWSjZRa1pCYVVKSmJXeGxTWEFyTm05WlpVWm9DbWRFTTI1Uk5sazBSV2g2U25SVmMxRTRSSEJrWTFGeU5FSk1XRE41ZDBsb1FVdFhkV05tYmxCUk9GaExPWGRZYkVwcVNWQTBZMFpFT0c1blpIazRkV29LYldreGN6RkRTamczTW1zclRVRnZSME5EY1VkVFRUUTVRa0ZOUkVFeVkwRk5SMUZEVFVoaU9YRjBSbGQxT1VGUU1FSXpaR3RKVkVZNGVrazRZVEkxVUFwb2IwbFBVVlJLVWxKeGFsVmlUMkUyVnpOMlRVZEJOWFpKTlZkVVJqQkZjREZwTWtGT2QwbDNSVko0TW5ocWVtWjNjbmRPYmxoUVpEQjRjbmd3WWxoRENtUmpOV0Z4WWxsWlVsRXdMMWhSVVdONFRFVnRkVGwzUnpGRlYydFNNWE01VEdaUGVHZDNVMjRLTFMwdExTMUZUa1FnUTBWU1ZFbEdTVU5CVkVVdExTMHRMUW89In19fX0=",
"integratedTime": 1690304684,
"logIndex": 28719030,
"logID": "c0d23d6ad406973f9559f3ba2d1ca01f84147d8ffc5b8445c224f98b9591801d"
}
},
"Issuer": "https://accounts.google.com",
"Subject": "krel-trust@k8s-releng-prod.iam.gserviceaccount.com",
"org.kubernetes.kpromo.version": "kpromo-v4.0.3-5-ge99897c"
}
}
]
With CAPI v1.6 we introduced new flags to allow serving metrics, the pprof endpoint and an endpoint to dynamically change log levels securely in production.
This feature is enabled per default via:
args:
- "--diagnostics-address=${CAPI_DIAGNOSTICS_ADDRESS:=:8443}"
As soon as the feature is enabled the metrics endpoint is served via https and protected via authentication and authorization. This works the same way as
metrics in core Kubernetes components: Metrics in Kubernetes .
To continue serving metrics via http the following configuration can be used:
args:
- "--diagnostics-address=localhost:8080"
- "--insecure-diagnostics"
The same can be achieved via clusterctl:
export CAPI_DIAGNOSTICS_ADDRESS: "localhost:8080"
export CAPI_INSECURE_DIAGNOSTICS: "true"
clusterctl init ...
Note : If insecure serving is configured the pprof and log level endpoints are disabled for security reasons.
A ServiceAccount token is now required to scrape metrics. The corresponding ServiceAccount needs permissions on the /metrics path.
This can be achieved e.g. by following the Kubernetes documentation .
With the Prometheus Helm chart it is as easy as using the following config for the Prometheus job scraping the Cluster API controllers:
scheme: https
authorization:
type: Bearer
credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
# The diagnostics endpoint is using a self-signed certificate, so we don't verify it.
insecure_skip_verify: true
For more details please see our Prometheus development setup: Prometheus
Note : The Prometheus Helm chart deploys the required ClusterRole out-of-the-box.
First deploy the following RBAC configuration:
cat << EOT | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: default-metrics
rules:
- nonResourceURLs:
- "/metrics"
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: default-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: default-metrics
subjects:
- kind: ServiceAccount
name: default
namespace: default
EOT
Then let’s open a port-forward, create a ServiceAccount token and scrape the metrics:
# Terminal 1
kubectl -n capi-system port-forward deployments/capi-controller-manager 8443
# Terminal 2
TOKEN=$(kubectl create token default)
curl https://localhost:8443/metrics --header "Authorization: Bearer $TOKEN" -k
Parca can be used to continuously scrape profiles from CAPI providers. For more details please see our Parca
development setup: parca
First deploy the following RBAC configuration:
cat << EOT | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: default-pprof
rules:
- nonResourceURLs:
- "/debug/pprof/*"
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: default-pprof
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: default-pprof
subjects:
- kind: ServiceAccount
name: default
namespace: default
EOT
Then let’s open a port-forward, create a ServiceAccount token and scrape the profile:
# Terminal 1
kubectl -n capi-system port-forward deployments/capi-controller-manager 8443
# Terminal 2
TOKEN=$(kubectl create token default)
# Get a goroutine dump
curl "https://localhost:8443/debug/pprof/goroutine?debug=2" --header "Authorization: Bearer $TOKEN" -k > ./goroutine.txt
# Get a profile
curl "https://localhost:8443/debug/pprof/profile?seconds=10" --header "Authorization: Bearer $TOKEN" -k > ./profile.out
go tool pprof -http=:8080 ./profile.out
First deploy the following RBAC configuration:
cat << EOT | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: default-loglevel
rules:
- nonResourceURLs:
- "/debug/flags/v"
verbs:
- put
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: default-loglevel
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: default-loglevel
subjects:
- kind: ServiceAccount
name: default
namespace: default
EOT
Then let’s open a port-forward, create a ServiceAccount token and change the log level to 8:
# Terminal 1
kubectl -n capi-system port-forward deployments/capi-controller-manager 8443
# Terminal 2
TOKEN=$(kubectl create token default)
curl "https://localhost:8443/debug/flags/v" --header "Authorization: Bearer $TOKEN" -X PUT -d '8' -k
This section provides security guidelines useful to provision clusters which are
secure by default to follow the secure defaults guidelines for cloud native apps .
Pod Security Admission allows applying Pod Security Standards during creation of pods at the cluster level.
The flavor development-topology for the Docker provider used in Quick Start already includes a basic Pod Security Standard configuration.
It is using ClusterClass variables and patches to inject the configuration.
By adding the following variables and patches Pod Security Standards can be added to every ClusterClass which references a Kubeadm based control plane .
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
spec:
variables:
- name: podSecurityStandard
required: false
schema:
openAPIV3Schema:
type: object
properties:
enabled:
type: boolean
default: true
description: "enabled enables the patches to enable Pod Security Standard via AdmissionConfiguration."
enforce:
type: string
default: "baseline"
description: "enforce sets the level for the enforce PodSecurityConfiguration mode. One of privileged, baseline, restricted."
pattern: "privileged|baseline|restricted"
audit:
type: string
default: "restricted"
description: "audit sets the level for the audit PodSecurityConfiguration mode. One of privileged, baseline, restricted."
pattern: "privileged|baseline|restricted"
warn:
type: string
default: "restricted"
description: "warn sets the level for the warn PodSecurityConfiguration mode. One of privileged, baseline, restricted."
pattern: "privileged|baseline|restricted"
...
The version field in Pod Security Admission Config defaults to latest.
The kube-system namespace is exempt from Pod Security Standards enforcement, because it runs control-plane pods that need higher privileges.
The following snippet contains the patch to be added to the ClusterClass.
Due to limitations of ClusterClass with patches there are two versions for this patch.
After adding the variables and patches the Pod Security Standards would be applied by default.
It is also possible to disable this patch or configure different levels for the configuration
using variables.
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: "my-cluster"
spec:
...
topology:
...
class: my-secure-cluster-class
variables:
- name: podSecurityStandard
value:
enabled: true
enforce: "restricted"
The clusterctl CLI tool handles the lifecycle of a Cluster API management cluster .
The clusterctl command line interface is specifically designed for providing a simple “day 1 experience” and a
quick start with Cluster API. It automates fetching the YAML files defining provider components and installing them.
Additionally it encodes a set of best practices in managing providers, that helps the user in avoiding
mis-configurations or in managing day 2 operations such as upgrades.
Below you can find a list of main clusterctl commands:
For the full list of clusterctl commands please refer to commands .
While using providers hosted on GitHub, clusterctl is calling GitHub API which are rate limited; for normal usage free tier is enough but when using clusterctl extensively users might hit the rate limit.
To avoid rate limiting for the public repos set the GITHUB_TOKEN environment variable. To generate a token follow this documentation. The token only needs repo scope for clusterctl.
Per default clusterctl will use a go proxy to detect the available versions to prevent additional
API calls to the GitHub API. It is possible to configure the go proxy url using the GOPROXY variable as
for go itself (defaults to https://proxy.golang.org).
To immediately fallback to the GitHub client and not use a go proxy, the environment variable could get set to
GOPROXY=off or GOPROXY=direct.
If a provider does not follow Go’s semantic versioning, clusterctl may fail when detecting the correct version.
In such cases, disabling the go proxy functionality via GOPROXY=off should be considered.
Instructions are available in the Quick Start .
The clusterctl init command installs the Cluster API components and transforms the Kubernetes cluster
into a management cluster.
This document provides more detail on how clusterctl init works and on the supported options for customizing your
management cluster.
The clusterctl init command accepts in input a list of providers to install.
You can use the clusterctl config repositories command to get a list of supported providers and their repository configuration.
If the provider of your choice is missing, you can customize the list of supported providers by using the
clusterctl configuration file.
Important! The Cluster API project supports ecosystem growth and extensibility. The clusterctl CLI carries a list of
predefined providers sponsored by SIG Cluster Lifecycle, and out-of-organization third party open-source repositories.
Each repository is the responsibility of the respective maintainers, including their quality standards and support.
The clusterctl init command automatically adds the cluster-api core provider, the kubeadm bootstrap provider, and
the kubeadm control-plane provider to the list of providers to install. This allows users to use a concise command syntax for initializing a management cluster.
For example, to get a fully operational management cluster with the aws infrastructure provider, the cluster-api core provider, the kubeadm bootstrap, and the kubeadm control-plane provider, use the command:
clusterctl init --infrastructure aws
The cluster-api core provider, the kubeadm bootstrap provider, and the kubeadm control-plane provider are automatically installed only if:
The user doesn’t explicitly require to install a core/bootstrap/control-plane provider using the --core flag, the --bootstrap flag or the --control-plane flags;
There is not an instance of a CoreProvider already installed in the cluster;
Please note that the second rule allows to execute clusterctl init more times: the first call actually initializes
the management cluster, while the subsequent calls can be used to add more providers.
To skip automatic provider installation use --bootstrap "-" or --control-plane "-".
Note it is not possible to skip automatic installation of the cluster-api core provider.
The clusterctl init command by default installs the latest version available
for each selected provider.
You can specify the provider version by appending a version tag to the provider name, e.g. aws:v0.4.1.
Pinning the version provides better control over what clusterctl chooses to install
(usually required in an enterprise environment). Version pinning should always be used when using image overrides , or when relying on internal repositories with a separated
software supply chain, or a custom versioning schema.
clusterctl init does not install pre-release versions by default. For
example, if a provider has releases v0.7.0-alpha.0 and v0.6.6, the latest
release installed will be v0.6.6.
You can specify the provider version by appending a version tag to the
provider name, e.g. vsphere:v0.7.0-alpha.0.
The clusterctl init command by default installs each provider in the default target namespace defined by each provider, e.g. capi-system for the Cluster API core provider.
See the provider documentation for more details.
You can specify the target namespace by using the --target-namespace flag.
Please, note that the --target-namespace flag applies to all the providers to be installed during a clusterctl init operation.
The clusterctl init command forbids users from installing two instances of the same provider in the
same target namespace.
To access provider specific information, such as the components YAML to be used for installing a provider,
clusterctl init accesses the provider repositories , that are well-known places where the release assets for
a provider are published.
Per default clusterctl will use a go proxy to detect the available versions to prevent additional
API calls to the GitHub API. It is possible to configure the go proxy url using the GOPROXY variable as
for go itself (defaults to https://proxy.golang.org).
To immediately fallback to the GitHub client and not use a go proxy, the environment variable could get set to
GOPROXY=off or GOPROXY=direct.
If a provider does not follow Go’s semantic versioning, clusterctl may fail when detecting the correct version.
In such cases, disabling the go proxy functionality via GOPROXY=off should be considered.
See clusterctl configuration for more info about provider repository configurations.
If, for any reasons, the user wants to replace the assets available on a provider repository with a locally available asset,
the user is required to save the file under $XDG_CONFIG_HOME/cluster-api/overrides/<provider-label>/<version>/<file-name.yaml>.
$XDG_CONFIG_HOME/cluster-api/overrides/infrastructure-aws/v0.5.2/infrastructure-components.yaml
Providers can use variables in the components YAML published in the provider’s repository.
During clusterctl init, those variables are replaced with environment variables or with variables read from the
clusterctl configuration .
Users can refer to the provider documentation for the list of variables to be set or use the
clusterctl generate provider --<provider-type> <provider-name> --describe command to get a list of expected variable names.
When installing a provider, the clusterctl init command executes a set of steps to simplify
the lifecycle management of the provider’s components.
All the provider’s components are labeled, so they can be easily identified in
subsequent moments of the provider’s lifecycle, e.g. upgrades.
labels:
- clusterctl.cluster.x-k8s.io: ""
- cluster.x-k8s.io/provider: "<provider-name>"
An additional Provider object is created in the target namespace where the provider is installed.
This object keeps track of the provider version, and other useful information
for the inventory of the providers currently installed in the management cluster.
The clusterctl.cluster.x-k8s.io labels, the cluster.x-k8s.io/provider labels and the Provider objects MUST NOT be altered.
If this happens, there are no guarantees about the proper functioning of clusterctl.
Cluster API providers require a cert-manager version supporting the cert-manager.io/v1 API to be installed in the cluster.
While doing init, clusterctl checks if there is a version of cert-manager already installed. If not, clusterctl will
install a default version (currently cert-manager v1.16.1). See clusterctl configuration for
available options to customize this operation.
Please note that, if clusterctl installs cert-manager, it will take care of its lifecycle, eventually upgrading it
during clusterctl upgrade. Instead, if cert-manager is provided by the users, the user is responsible for
upgrading this component when required.
Follow this
The clusterctl generate cluster command returns a YAML template for creating a workload cluster.
For example
clusterctl generate cluster my-cluster --kubernetes-version v1.28.0 --control-plane-machine-count=3 --worker-machine-count=3 > my-cluster.yaml
Generates a YAML file named my-cluster.yaml with a predefined list of Cluster API objects; Cluster, Machines,
Machine Deployments, etc. to be deployed in the current namespace (in case, use the --target-namespace flag to
specify a different target namespace).
Then, the file can be modified using your editor of choice; when ready, run the following command
to apply the cluster manifest.
kubectl apply -f my-cluster.yaml
The clusterctl generate cluster command uses smart defaults in order to simplify the user experience; in the example above,
it detects that there is only an aws infrastructure provider in the current management cluster and so it automatically
selects a cluster template from the aws provider’s repository.
In case there is more than one infrastructure provider, the following syntax can be used to select which infrastructure
provider to use for the workload cluster:
clusterctl generate cluster my-cluster --kubernetes-version v1.28.0 \
--infrastructure aws > my-cluster.yaml
or
clusterctl generate cluster my-cluster --kubernetes-version v1.28.0 \
--infrastructure aws:v0.4.1 > my-cluster.yaml
The infrastructure provider authors can provide different types of cluster templates, or flavors; use the --flavor flag
to specify which flavor to use; e.g.
clusterctl generate cluster my-cluster --kubernetes-version v1.28.0 \
--flavor high-availability > my-cluster.yaml
Please refer to the providers documentation for more info about available flavors.
clusterctl uses the provider’s repository as a primary source for cluster templates; the following alternative sources
for cluster templates can be used as well:
Use the --from-config-map flag to read cluster templates stored in a Kubernetes ConfigMap; e.g.
clusterctl generate cluster my-cluster --kubernetes-version v1.28.0 \
--from-config-map my-templates > my-cluster.yaml
Also following flags are available --from-config-map-namespace (defaults to current namespace) and --from-config-map-key
(defaults to template).
Use the --from flag to read cluster templates stored in a GitHub repository, raw template URL, in a local file system folder,
or from the standard input; e.g.
clusterctl generate cluster my-cluster --kubernetes-version v1.28.0 \
--from https://github.com/my-org/my-repository/blob/main/my-template.yaml > my-cluster.yaml
or
clusterctl generate cluster my-cluster --kubernetes-version v1.28.0 \
--from https://foo.bar/my-template.yaml > my-cluster.yaml
or
clusterctl generate cluster my-cluster --kubernetes-version v1.28.0 \
--from ~/my-template.yaml > my-cluster.yaml
or
cat ~/my-template.yaml | clusterctl generate cluster my-cluster --kubernetes-version v1.28.0 \
--from - > my-cluster.yaml
If the selected cluster template expects some environment variables, the user should ensure those variables are set in advance.
E.g. if the AWS_CREDENTIALS variable is expected for a cluster template targeting the aws infrastructure, you
should ensure the corresponding environment variable to be set before executing clusterctl generate cluster.
Please refer to the providers documentation for more info about the required variables or use the
clusterctl generate cluster --list-variables flag to get a list of variables names required by a cluster template.
The clusterctl configuration file can be used as alternative to environment variables.
Generate templates for provider components.
clusterctl fetches the provider components from the provider repository and performs variable substitution.
Variable values are either sourced from the clusterctl config file or
from environment variables
Usage: clusterctl generate provider [flags]
Current usage of the command is as follows:
# Generates a yaml file for creating provider with variable values using
# components defined in the provider repository.
clusterctl generate provider --infrastructure aws
# Generates a yaml file for creating provider for a specific version with variable values using
# components defined in the provider repository.
clusterctl generate provider --infrastructure aws:v0.4.1
# Displays information about a specific infrastructure provider.
# If applicable, prints out the list of required environment variables.
clusterctl generate provider --infrastructure aws --describe
# Displays information about a specific version of the infrastructure provider.
clusterctl generate provider --infrastructure aws:v0.4.1 --describe
# Generates a yaml file for creating provider for a specific version.
# No variables will be processed and substituted using this flag
clusterctl generate provider --infrastructure aws:v0.4.1 --raw
The clusterctl generate yaml command processes yaml using clusterctl’s yaml
processor.
The intent of this command is to allow users who may have specific templates
to leverage clusterctl’s yaml processor for variable substitution. For
example, this command can be leveraged in local and CI scripts or for
development purposes.
clusterctl ships with a simple yaml processor that performs variable
substitution that takes into account default values.
Under the hood, clusterctl’s yaml processor uses
drone/envsubst to replace variables and uses the defaults if
necessary.
Variable values are either sourced from the clusterctl config file or
from environment variables.
Current usage of the command is as follows:
# Generates a configuration file with variable values using a template from a
# specific URL as well as a GitHub URL.
clusterctl generate yaml --from https://github.com/foo-org/foo-repository/blob/main/cluster-template.yaml
clusterctl generate yaml --from https://foo.bar/cluster-template.yaml
# Generates a configuration file with variable values using
# a template stored locally.
clusterctl generate yaml --from ~/workspace/cluster-template.yaml
# Prints list of variables used in the local template
clusterctl generate yaml --from ~/workspace/cluster-template.yaml --list-variables
# Prints list of variables from template passed in via stdin
cat ~/workspace/cluster-template.yaml | clusterctl generate yaml --from - --list-variables
# Default behavior for this sub-command is to read from stdin.
# Generate configuration from stdin
cat ~/workspace/cluster-template.yaml | clusterctl generate yaml
This command prints the kubeconfig of an existing workload cluster into stdout.
This functionality is available in clusterctl v0.3.9 or newer.
Get the kubeconfig of a workload cluster named foo.
clusterctl get kubeconfig foo
Get the kubeconfig of a workload cluster named foo in the namespace bar
clusterctl get kubeconfig foo --namespace bar
Get the kubeconfig of a workload cluster named foo using a specific context bar
clusterctl get kubeconfig foo --kubeconfig-context bar
The clusterctl describe cluster command provides an “at a glance” view of a Cluster API cluster designed
to help the user in quickly understanding if there are problems and where.
For example clusterctl describe cluster capi-quickstart will provide an output similar to:
The “at a glance” view is based on the idea that clusterctl should avoid overloading the user with information,
but instead surface problems, if any.
In practice, if you look at the ControlPlane node, you might notice that the underlying machines
are grouped together, because all of them have the same state (Ready equal to True), so it is not
necessary to repeat the same information three times.
If this is not the case, and machines have different states, the visualization is going to use different lines:
You might also notice that the visualization does not represent the infrastructure machine or the
bootstrap object linked to a machine, unless their state differs from the machine’s state.
By default, the visualization generated by clusterctl describe cluster hides details for the sake
of simplicity and shortness. However, if required, the user can ask for showing all the detail:
By using --grouping=false, the user can force the visualization to show all the machines
on separated lines, no matter if they have the same state or not:
By using the --echo flag, the user can force the visualization to show infrastructure machines and
bootstrap objects linked to machines, no matter if they have the same state or not:
It is also possible to force the visualization to show all the conditions for an object (instead of showing
only the ready condition). e.g. with --show-conditions KubeadmControlPlane you get:
Please note that this option is flexible, and you can pass a comma separated list of kind or kind/name for
which the command should show all the object’s conditions (use ‘all’ to show conditions for everything).
The clusterctl move command allows to move the Cluster API objects defining workload clusters, like e.g. Cluster, Machines,
MachineDeployments, etc. from one management cluster to another management cluster.
Before running clusterctl move, the user should take care of preparing the target management cluster, including also installing
all the required provider using clusterctl init.
The version of the providers installed in the target management cluster should be at least the same version of the
corresponding provider in the source cluster.
You can use:
clusterctl move --to-kubeconfig="path-to-target-kubeconfig.yaml"
To move the Cluster API objects existing in the current namespace of the source management cluster; in case if you want
to move the Cluster API objects defined in another namespace, you can use the --namespace flag.
The discovery mechanism for determining the objects to be moved is in the provider contract
Before moving a Cluster, clusterctl sets the Cluster.Spec.Paused field to true stopping
the controllers from reconciling the workload cluster in the source management cluster .
clusterctl will wait until the clusterctl.cluster.x-k8s.io/block-move annotation is not
present on any resource targeted by the move operation.
The Cluster object created in the target management cluster instead will be actively reconciled as soon as the move
process completes.
clusterctl move has been designed and developed around the bootstrap use case described below, and currently this is the only
use case verified by Cluster API E2E tests.
If someone intends to use clusterctl move outside of this scenario, it’s recommended to set up a custom validation pipeline of
it before using the command on a production environment.
Also, it is important to notice that move has not been designed for being used as a backup/restore solution and it has
several limitation for this scenario, like e.g. the implementation assumes the cluster must be stable
while doing the move operation, and possible race conditions happening while the cluster is upgrading, scaling up,
remediating etc. has never been investigated nor addressed.
In order to avoid further confusion about this point, clusterctl backup and clusterctl restore commands have been
removed because they were built on top of clusterctl move logic and they were sharing the same limitations.
User can use clusterctl move --to-directory and clusterctl move --from-directory instead; this will hopefully
make it clear those operation have the same limitations of the move command.
Every object’s Status subresource, including every nested field (e.g. Status.Conditions), is never restored during a move operation. A Status subresource should never contain fields that cannot be recreated or derived from information in spec, metadata, or external systems.
Provider implementers should not store non-ephemeral data in the Status.
Status should be able to be fully rebuilt by controllers by observing the current state of resources.
Pivoting is a process for moving the provider components and declared Cluster API resources from a source management
cluster to a target management cluster.
This can now be achieved with the following procedure:
Use clusterctl init to install the provider components into the target management cluster
Use clusterctl move to move the cluster-api resources from a Source Management cluster to a Target Management cluster
The pivot process can be bounded with the creation of a temporary bootstrap cluster
used to provision a target Management cluster.
This can now be achieved with the following procedure:
Create a temporary bootstrap cluster, e.g. using kind or minikube
Use clusterctl init to install the provider components
Use clusterctl generate cluster ... | kubectl apply -f - to provision a target management cluster
Wait for the target management cluster to be up and running
Get the kubeconfig for the new target management cluster
Use clusterctl init with the new cluster’s kubeconfig to install the provider components
Use clusterctl move to move the Cluster API resources from the bootstrap cluster to the target management cluster
Delete the bootstrap cluster
Note: It’s required to have at least one worker node to schedule Cluster API workloads (i.e. controllers).
A cluster with a single control plane node won’t be sufficient due to the NoSchedule taint. If a worker node isn’t available, clusterctl init will timeout.
With --dry-run option you can dry-run the move action by only printing logs without taking any actual actions. Use log level verbosity -v to see different levels of information.
The clusterctl upgrade command can be used to upgrade the version of the Cluster API providers (CRDs, controllers)
installed into a management cluster.
The clusterctl upgrade plan command can be used to identify possible targets for upgrades.
clusterctl upgrade plan
Produces an output similar to this:
Checking cert-manager version...
Cert-Manager will be upgraded from "v1.5.0" to "v1.5.3"
Checking new release availability...
Management group: capi-system/cluster-api, latest release available for the v1beta1 API Version of Cluster API (contract):
NAME NAMESPACE TYPE CURRENT VERSION NEXT VERSION
bootstrap-kubeadm capi-kubeadm-bootstrap-system BootstrapProvider v0.4.0 v1.0.0
control-plane-kubeadm capi-kubeadm-control-plane-system ControlPlaneProvider v0.4.0 v1.0.0
cluster-api capi-system CoreProvider v0.4.0 v1.0.0
infrastructure-docker capd-system InfrastructureProvider v0.4.0 v1.0.0
You can now apply the upgrade by executing the following command:
clusterctl upgrade apply --contract v1beta1
The output contains the latest release available for each API Version of Cluster API (contract)
available at the moment.
clusterctl upgrade plan does not display pre-release versions by default. For
example, if a provider has releases v0.7.0-alpha.0 and v0.6.6 available, the latest
release available for upgrade will be v0.6.6.
After choosing the desired option for the upgrade, you can run the following
command to upgrade all the providers in the management cluster. This upgrades
all the providers to the latest stable releases.
clusterctl upgrade apply --contract v1beta1
The upgrade process is composed by three steps:
Check the cert-manager version, and if necessary, upgrade it.
Delete the current version of the provider components, while preserving the namespace where the provider components
are hosted and the provider’s CRDs.
Install the new version of the provider components.
Please note that clusterctl does not upgrade Cluster API objects (Clusters, MachineDeployments, Machine etc.); upgrading
such objects are the responsibility of the provider’s controllers.
It is also possible to explicitly upgrade one or more components to specific versions.
clusterctl upgrade apply \
--core cluster-api:v1.2.4 \
--infrastructure docker:v1.2.4
Cluster API only tests a subset of possible clusterctl upgrade paths as otherwise the test matrix would be overwhelming.
Untested upgrade paths are not blocked by clusterctl and should work in general, they are just not tested. Users
intending to use an upgrade path not tested by us should do their own validation to ensure the operation works correctly.
The following is an example of the tested upgrade paths for v1.5:
From To Note
v1.0 v1.5 v1.0 is the first release with the v1beta1 contract. v1.3 v1.5 v1.3 is v1.5 - 2. v1.4 v1.5 v1.4 is v1.5 - 1.
The idea is to always test upgrade from v1.0 and the previous two minor releases.
The current implementation of the upgrade process does not preserve controllers flags that are not set through the
components YAML/at the installation time.
User is required to re-apply flag values after the upgrade completes.
In order to upgrade to a provider’s pre-release version, we can do
the following:
clusterctl upgrade apply \
--core cluster-api:v1.0.0 \
--bootstrap kubeadm:v1.0.0 \
--control-plane kubeadm:v1.0.0 \
--infrastructure docker:v1.0.0-rc.0
In this case, all the provider’s versions must be explicitly stated.
Use clusterctl CLI options to target the desired version .
The following shows an example of upgrading bootrap, kubeadm and core components to version v1.6.0-rc.1:
TARGET_VERSION=v1.6.0-rc.1
clusterctl upgrade apply \
--bootstrap=kubeadm:${TARGET_VERSION} \
--control-plane=kubeadm:${TARGET_VERSION} \
--core=cluster-api:${TARGET_VERSION}
Cluster API publishes nightly versions of the project componenents’ manifests from the main branch to a Google storage bucket for user consumption. The syntax for the URL is: https://storage.googleapis.com/artifacts.k8s-staging-cluster-api.appspot.com/components/nightly_main_<YYYYMMDD>/<COMPENENT_NAME>-components.yaml.
For example, to retrieve the core component manifest published January 1, 2024, the following URL can be used: https://storage.googleapis.com/artifacts.k8s-staging-cluster-api.appspot.com/components/nightly_main_20240101/core-components.yaml.
The clusterctl delete command deletes the provider components from the management cluster.
The operation is designed to prevent accidental deletion of user created objects. For example:
clusterctl delete --infrastructure aws
This command deletes the AWS infrastructure provider components, while preserving
the namespace where the provider components are hosted and the provider’s CRDs.
If you want to delete the namespace where the provider components are hosted, you can use the --include-namespace flag.
Be aware that this operation deletes all the object existing in a namespace, not only the provider’s components.
If you want to delete the provider’s CRDs, and all the components related to CRDs like e.g. the ValidatingWebhookConfiguration etc.,
you can use the --include-crd flag.
Be aware that this operation deletes all the objects of Kind’s defined in the provider’s CRDs, e.g. when deleting
the aws provider, it deletes all the AWSCluster, AWSMachine etc.
If you want to delete all the providers in a single operation, you can use the --all flag.
clusterctl delete --all
The clusterctl completion command outputs shell completion code for the
specified shell (bash or zsh). The shell code must be evaluated to provide
interactive completion of clusterctl commands.
To install bash-completion on macOS, use Homebrew:
brew install bash-completion
Once installed, bash_completion must be evaluated. This can be done by adding
the following line to the ~/.bash_profile.
[[ -r "$(brew --prefix)/etc/profile.d/bash_completion.sh" ]] && . "$(brew --prefix)/etc/profile.d/bash_completion.sh"
If bash-completion is not installed on Linux, please install the
‘bash-completion’ package via your distribution’s package manager.
You now have to ensure that the clusterctl completion script gets sourced in
all your shell sessions. There are multiple ways to achieve this:
The clusterctl completion script for Zsh can be generated with the command
clusterctl completion zsh.
If shell completion is not already enabled in your environment you will need to
enable it. You can execute the following once:
echo "autoload -U compinit; compinit" >> ~/.zshrc
To load completions for each session, execute once:
clusterctl completion zsh > "${fpath[1]}/_clusterctl"
You will need to start a new shell for this setup to take effect.
The clusterctl alpha rollout command manages the rollout of a Cluster API resource. It consists of several sub-commands which are documented below.
Currently, only the following Cluster API resources are supported by the rollout command:
kubeadmcontrolplanes
machinedeployments
Use the restart sub-command to force an immediate rollout. Note that rollout refers to the replacement of existing machines with new machines using the desired rollout strategy (default: rolling update). For example, here the MachineDeployment my-md-0 will be immediately rolled out:
clusterctl alpha rollout restart machinedeployment/my-md-0
Use the undo sub-command to rollback to an earlier revision. For example, here the MachineDeployment my-md-0 will be rolled back to revision number 3. If the --to-revision flag is omitted, the MachineDeployment will be rolled back to the revision immediately preceding the current one. If the desired revision does not exist, the undo will return an error.
clusterctl alpha rollout undo machinedeployment/my-md-0 --to-revision=3
Use the pause sub-command to pause a Cluster API resource. The command is a NOP if the resource is already paused. Note that internally, this command sets the Paused field within the resource spec (e.g. MachineDeployment.Spec.Paused) to true.
clusterctl alpha rollout pause machinedeployment/my-md-0
Use the resume sub-command to resume a currently paused Cluster API resource. The command is a NOP if the resource is currently not paused.
clusterctl alpha rollout resume machinedeployment/my-md-0
Paused resources will not be reconciled by a controller. By resuming a resource, we allow it to be reconciled again.
“clusterctl alpha topology plan” is deprecated and will be removed in one of the upcoming releases. For more details, please see #10138 .
The clusterctl alpha topology plan command can be used to get a plan of how a Cluster topology evolves given
file(s) containing resources to be applied to a Cluster.
The input file(s) could contain a new/modified Cluster, a new/modified ClusterClass and/or new/modified templates,
depending on the use case you are going to plan for (see more details below).
The topology plan output would provide details about objects that will be created, updated and deleted of a target cluster;
If instead the command detects that the change impacts many Clusters, the users will be required to select one to focus on (see flags below).
clusterctl alpha topology plan -f input.yaml -o output/
This command can be used with or without a management cluster. In case the command is used without a management cluster
the input should have all the objects needed.
The topology controllers uses Server Side Apply
to support use cases where other controllers are co-authoring the same objects, but this kind of interactions can’t be recreated
in a dry-run scenario.
As a consequence Dry-Run can give some false positives/false negatives when trying to have a preview of
changes to a set of existing topology owned objects. In other worlds this limitation impacts all the use cases described
below except for “Designing a new ClusterClass”.
More specifically:
DryRun doesn’t consider OpenAPI schema extension like +ListMap this can lead to false positives when topology
dry run is simulating a change to an existing slice (DryRun always reverts external changes, like server side apply when +ListMap=atomic).
DryRun doesn’t consider existing metadata.managedFields, and this can lead to false negatives when topology dry run
is simulating a change where a field is dropped from a template (DryRun always preserve dropped fields, like
server side apply when the field has more than one manager).
Please note that clusterctl doesn’t support Runtime SDK yet. This means that ClusterClasses with external patches are not yet supported.
When designing a new ClusterClass users might want to preview the Cluster generated using such ClusterClass.
The clusterctl alpha topology plan command can be used to do so:
clusterctl alpha topology plan -f example-cluster-class.yaml -f example-cluster.yaml -o output/
example-cluster-class.yaml holds the definitions of the ClusterClass and all the associated templates.
View example-cluster-class.yaml
apiVersion: cluster.x-k8s.io/v1beta1
kind: ClusterClass
metadata:
name: example-cluster-class
namespace: default
spec:
controlPlane:
ref:
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlaneTemplate
name: example-cluster-control-plane
namespace: default
machineInfrastructure:
ref:
kind: DockerMachineTemplate
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
name: "example-cluster-control-plane"
namespace: default
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerClusterTemplate
name: example-cluster
namespace: default
workers:
machineDeployments:
- class: "default-worker"
template:
bootstrap:
ref:
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
name: example-docker-worker-bootstraptemplate
infrastructure:
ref:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachineTemplate
name: example-docker-worker-machinetemplate
---
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerClusterTemplate
metadata:
name: example-cluster
namespace: default
spec:
template:
spec: {}
---
kind: KubeadmControlPlaneTemplate
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
metadata:
name: "example-cluster-control-plane"
namespace: default
spec:
template:
spec:
machineTemplate:
nodeDrainTimeout: 1s
kubeadmConfigSpec:
clusterConfiguration:
apiServer:
certSANs: [ localhost, 127.0.0.1 ]
initConfiguration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
joinConfiguration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
---
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachineTemplate
metadata:
name: "example-cluster-control-plane"
namespace: default
spec:
template:
spec:
extraMounts:
- containerPath: "/var/run/docker.sock"
hostPath: "/var/run/docker.sock"
---
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachineTemplate
metadata:
name: "example-docker-worker-machinetemplate"
namespace: default
spec:
template:
spec: {}
---
apiVersion: bootstrap.cluster.x-k8s.io/v1beta1
kind: KubeadmConfigTemplate
metadata:
name: "example-docker-worker-bootstraptemplate"
namespace: default
spec:
template:
spec:
joinConfiguration:
nodeRegistration: {} # node registration parameters are automatically injected by CAPD according to the kindest/node image in use.
example-cluster.yaml holds the definition of example-cluster Cluster.
View example-cluster.yaml
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: "example-cluster"
namespace: "default"
labels:
cni: kindnet
spec:
clusterNetwork:
services:
cidrBlocks: ["10.128.0.0/12"]
pods:
cidrBlocks: ["192.168.0.0/16"]
serviceDomain: "cluster.local"
topology:
class: example-cluster-class
version: v1.21.2
controlPlane:
metadata: {}
replicas: 1
workers:
machineDeployments:
- class: "default-worker"
name: "md-0"
replicas: 1
Produces an output similar to this:
The following ClusterClasses will be affected by the changes:
* default/example-cluster-class
The following Clusters will be affected by the changes:
* default/example-cluster
Changes for Cluster "default/example-cluster":
NAMESPACE KIND NAME ACTION
default DockerCluster example-cluster-rnx2q created
default DockerMachineTemplate example-cluster-control-plane-dfnvz created
default DockerMachineTemplate example-cluster-md-0-infra-qz9qk created
default KubeadmConfigTemplate example-cluster-md-0-bootstrap-m29vz created
default KubeadmControlPlane example-cluster-b2lhc created
default MachineDeployment example-cluster-md-0-pqscg created
default Secret example-cluster-shim created
default Cluster example-cluster modified
Created objects are written to directory "output/created"
Modified objects are written to directory "output/modified"
The contents of the output directory are similar to this:
output
├── created
│ ├── DockerCluster_default_example-cluster-rnx2q.yaml
│ ├── DockerMachineTemplate_default_example-cluster-control-plane-dfnvz.yaml
│ ├── DockerMachineTemplate_default_example-cluster-md-0-infra-qz9qk.yaml
│ ├── KubeadmConfigTemplate_default_example-cluster-md-0-bootstrap-m29vz.yaml
│ ├── KubeadmControlPlane_default_example-cluster-b2lhc.yaml
│ ├── MachineDeployment_default_example-cluster-md-0-pqscg.yaml
│ └── Secret_default_example-cluster-shim.yaml
└── modified
├── Cluster_default_example-cluster.diff
├── Cluster_default_example-cluster.jsonpatch
├── Cluster_default_example-cluster.modified.yaml
└── Cluster_default_example-cluster.original.yaml
When making changes to a Cluster topology the clusterctl alpha topology plan can be used to analyse how the underlying objects will be affected.
clusterctl alpha topology plan -f modified-example-cluster.yaml -o output/
The modified-example-cluster.yaml scales up the control plane to 3 replicas and adds additional labels to the machine deployment.
View modified-example-cluster.yaml
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: "example-cluster"
namespace: default
labels:
cni: kindnet
spec:
clusterNetwork:
services:
cidrBlocks: ["10.128.0.0/12"]
pods:
cidrBlocks: ["192.168.0.0/16"]
serviceDomain: "cluster.local"
topology:
class: example-cluster-class
version: v1.21.2
controlPlane:
metadata: {}
# Scale up the control plane from 1 -> 3.
replicas: 3
workers:
machineDeployments:
- class: "default-worker"
# Apply additional labels.
metadata:
labels:
test-label: md-0-label
name: "md-0"
replicas: 1
Produces an output similar to this:
Detected a cluster with Cluster API installed. Will use it to fetch missing objects.
No ClusterClasses will be affected by the changes.
The following Clusters will be affected by the changes:
* default/example-cluster
Changes for Cluster "default/example-cluster":
NAMESPACE KIND NAME ACTION
default KubeadmControlPlane example-cluster-l7kx8 modified
default MachineDeployment example-cluster-md-0-j58ln modified
Modified objects are written to directory "output/modified"
The command can be used to plan if a Cluster can be successfully rebased to a different ClusterClass.
Rebasing a Cluster to a different ClusterClass:
# Rebasing from `example-cluster-class` to `another-cluster-class`.
clusterctl alpha topology plan -f rebase-example-cluster.yaml -o output/
The example-cluster Cluster is rebased from example-cluster-class to another-cluster-class. In this example another-cluster-class is assumed to be available in the management cluster.
View rebase-example-cluster.yaml
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: "example-cluster"
namespace: "default"
labels:
cni: kindnet
spec:
clusterNetwork:
services:
cidrBlocks: ["10.128.0.0/12"]
pods:
cidrBlocks: ["192.168.0.0/16"]
serviceDomain: "cluster.local"
topology:
# ClusterClass changed from 'example-cluster-class' -> 'another-cluster-class'.
class: another-cluster-class
version: v1.21.2
controlPlane:
metadata: {}
replicas: 1
workers:
machineDeployments:
- class: "default-worker"
name: "md-0"
replicas: 1
If the target ClusterClass is compatible with the original ClusterClass the output be similar to:
Detected a cluster with Cluster API installed. Will use it to fetch missing objects.
No ClusterClasses will be affected by the changes.
The following Clusters will be affected by the changes:
* default/example-cluster
Changes for Cluster "default/example-cluster":
NAMESPACE KIND NAME ACTION
default DockerCluster example-cluster-7t7pl modified
default DockerMachineTemplate example-cluster-control-plane-lt6kw modified
default DockerMachineTemplate example-cluster-md-0-infra-cjxs4 modified
default KubeadmConfigTemplate example-cluster-md-0-bootstrap-m9sg8 modified
default KubeadmControlPlane example-cluster-l7kx8 modified
Modified objects are written to directory "output/modified"
Instead, if the command detects that the rebase operation would lead to a non-functional cluster (ClusterClasses are incompatible), the output will be similar to:
Detected a cluster with Cluster API installed. Will use it to fetch missing objects.
Error: failed defaulting and validation on input objects: failed to run defaulting and validation on Clusters: failed validation of cluster.x-k8s.io/v1beta1, Kind=Cluster default/example-cluster: Cluster.cluster.x-k8s.io "example-cluster" is invalid: spec.topology.workers.machineDeployments[0].class: Invalid value: "default-worker": MachineDeploymentClass with name "default-worker" does not exist in ClusterClass "another-cluster-class"
In this example rebasing will lead to a non-functional Cluster because the ClusterClass is missing a worker class that is used by the Cluster.
When planning for a change on a ClusterClass you might want to understand what effects the change will have on existing clusters.
clusterctl alpha topology plan -f modified-first-cluster-class.yaml -o output/
When multiple clusters are affected, only the list of Clusters and ClusterClasses is presented.
Detected a cluster with Cluster API installed. Will use it to fetch missing objects.
The following ClusterClasses will be affected by the changes:
* default/first-cluster-class
The following Clusters will be affected by the changes:
* default/first-cluster
* default/second-cluster
No target cluster identified. Use --cluster to specify a target cluster to get detailed changes.
To get the full list of changes for the “first-cluster”:
clusterctl alpha topology plan -f modified-first-cluster-class.yaml -o output/ -c "first-cluster"
Output will be similar to the full summary output provided in other examples.
The topology plan operation is composed of the following steps:
Set the namespace on objects in the input with missing namespace.
Run the Defaulting and Validation webhooks on the Cluster and ClusterClass objects in the input.
Dry run the topology reconciler on the target cluster.
Capture all changes observed during reconciliation.
The input file(s) with the target changes. Supports multiple input files.
The objects in the input should follow these rules:
All the objects in the input should belong to the same namespace.
Should not have multiple Clusters.
Should not have multiple ClusterClasses.
If some of the objects have a defined namespace and some do not, the objects are considered as belonging to different namespaces
which is not allowed.
All templates in the inputs should be fully valid and have all the default values set. topology plan will not run any defaulting
or validation on these objects. Defaulting and validation is only run on Cluster and ClusterClass objects.
All the objects in the input of the same Group.Kind should have the same apiVersion.
Example: Two InfraMachineTemplates with apiVersions infrastructure.cluster.x-k8s.io/v1beta1 and infrastructure.cluster.x-k8s.io/v1alpha4 are not allowed.
The API version of resource in the input should be compatible with the current version of Cluster API contract.
Information about the objects that are created and updated is written to this directory.
For objects that are modified the following files are written to disk:
Original object
Final object
JSON patch between the original and the final objects
Diff of the original and final objects
When multiple clusters are affected by the input, --cluster can be used to specify a target cluster.
If only one cluster is affected or if a Cluster is in the input it defaults as the target cluster.
Namespace used for objects with missing namespaces in the input.
If not provided, the namespace defined in kubeconfig is used. If a kubeconfig is not available the value default is used.
Display the list of providers and their repository configurations.
clusterctl ships with a list of known providers; if necessary, edit
$XDG_CONFIG_HOME/cluster-api/clusterctl.yaml file to add a new provider or to customize existing ones.
Help provides help for any command in the application.
Simply type clusterctl help [command] for full details.
Print clusterctl version.
Lists the container images required for initializing the management cluster.
The clusterctl config file is located at $XDG_CONFIG_HOME/cluster-api/clusterctl.yaml.
It can be used to:
Customize the list of providers and provider repositories.
Provide configuration values to be used for variable substitution when installing providers or creating clusters.
Define image overrides for air-gapped environments.
The clusterctl CLI is designed to work with providers implementing the clusterctl Provider Contract .
Each provider is expected to define a provider repository, a well-known place where release assets are published.
By default, clusterctl ships with providers sponsored by SIG Cluster
Lifecycle. Use clusterctl config repositories to get a list of supported
providers and their repository configuration.
Users can customize the list of available providers using the clusterctl configuration file, as shown in the following example:
providers:
# add a custom provider
- name: "my-infra-provider"
url: "https://github.com/myorg/myrepo/releases/latest/infrastructure-components.yaml"
type: "InfrastructureProvider"
# override a pre-defined provider
- name: "cluster-api"
url: "https://github.com/myorg/myforkofclusterapi/releases/latest/core-components.yaml"
type: "CoreProvider"
# add a custom provider on a self-hosted GitLab (host should start with "gitlab.")
- name: "my-other-infra-provider"
url: "https://gitlab.example.com/api/v4/projects/myorg%2Fmyrepo/packages/generic/myrepo/v1.2.3/infrastructure-components.yaml"
type: "InfrastructureProvider"
# override a pre-defined provider on a self-hosted GitLab (host should start with "gitlab.")
- name: "kubeadm"
url: "https://gitlab.example.com/api/v4/projects/external-packages%2Fcluster-api/packages/generic/cluster-api/v1.1.3/bootstrap-components.yaml"
type: "BootstrapProvider"
See provider contract for instructions about how to set up a provider repository.
Note : It is possible to use the ${HOME} and ${CLUSTERCTL_REPOSITORY_PATH} environment variables in url.
When installing a provider clusterctl reads a YAML file that is published in the provider repository. While executing
this operation, clusterctl can substitute certain variables with the ones provided by the user.
The same mechanism also applies when clusterctl reads the cluster templates YAML published in the repository, e.g.
when injecting the Kubernetes version to use, or the number of worker machines to create.
The user can provide values using OS environment variables, but it is also possible to add
variables in the clusterctl config file:
# Values for environment variable substitution
AWS_B64ENCODED_CREDENTIALS: XXXXXXXX
The format of keys should always be UPPERCASE_WITH_UNDERSCORE for both OS environment variables and in the clusterctl
config file (NOTE: this limitation derives from Viper , the library we are using internally to retrieve variables).
In case a variable is defined both in the config file and as an OS environment variable,
the environment variable takes precedence.
While doing init, clusterctl checks if there is a version of cert-manager already installed. If not, clusterctl will
install a default version.
By default, cert-manager will be fetched from https://github.com/cert-manager/cert-manager/releases; however, if the user
wants to use a different repository, it is possible to use the following configuration:
cert-manager:
url: "/Users/foo/.config/cluster-api/dev-repository/cert-manager/latest/cert-manager.yaml"
Note : It is possible to use the ${HOME} and ${CLUSTERCTL_REPOSITORY_PATH} environment variables in url.
Similarly, it is possible to override the default version installed by clusterctl by configuring:
cert-manager:
...
version: "v1.1.1"
For situations when resources are limited or the network is slow, the cert-manager wait time to be running can be customized by adding a field to the clusterctl config file, for example:
cert-manager:
...
timeout: 15m
The value string is a possibly signed sequence of decimal numbers, each with optional fraction and a unit suffix, such as “300ms”, “-1.5h” or “2h45m”. Valid time units are “ns”, “us” (or “µs”), “ms”, “s”, “m”, “h”.
If no value is specified, or the format is invalid, the default value of 10 minutes will be used.
Please note that the configuration above will be considered also when doing clusterctl upgrade plan or clusterctl upgrade plan.
You may want to migrate to a user-managed cert-manager further down the line, after initialising cert-manager on the management cluster through clusterctl.
clusterctl looks for the label clusterctl.cluster.x-k8s.io/core=cert-manager on all api resources in the cert-manager namespace. If it finds the label, clusterctl will manage the cert-manager deployment. You can list all the resources with that label by running:
kubectl api-resources --verbs=list -o name | xargs -n 1 kubectl get --show-kind --ignore-not-found -A --selector=clusterctl.cluster.x-k8s.io/core=cert-manager
If you want to manage and install your own cert-manager, you’ll need to remove this label from all API resources.
Cluster API has a direct dependency on cert-manager. It’s possible you could encounter issues if you use a different version to the Cluster API default version.
Follow this
Overrides only provide file replacements; instead, provider version resolution is based only on the actual repository structure.
clusterctl uses an overrides layer to read in injected provider components,
cluster templates and metadata. By default, it reads the files from
$XDG_CONFIG_HOME/cluster-api/overrides.
The directory structure under the overrides directory should follow the
template:
<providerType-providerName>/<version>/<fileName>
For example,
├── bootstrap-kubeadm
│ └── v1.1.5
│ └── bootstrap-components.yaml
├── cluster-api
│ └── v1.1.5
│ └── core-components.yaml
├── control-plane-kubeadm
│ └── v1.1.5
│ └── control-plane-components.yaml
└── infrastructure-aws
└── v0.5.0
├── cluster-template-dev.yaml
└── infrastructure-components.yaml
For developers who want to generate the overrides layer, see
Build artifacts locally .
Once these overrides are specified, clusterctl will use them instead of
getting the values from the default or specified providers.
One example usage of the overrides layer is that it allows you to deploy
clusters with custom templates that may not be available from the official
provider repositories.
For example, you can now do:
clusterctl generate cluster mycluster --flavor dev --infrastructure aws:v0.5.0 -v5
The -v5 provides verbose logging which will confirm the usage of the
override file.
Using Override="cluster-template-dev.yaml" Provider="infrastructure-aws" Version="v0.5.0"
Another example, if you would like to deploy a custom version of CAPA, you can
make changes to infrastructure-components.yaml in the overrides folder and
run,
clusterctl init --infrastructure aws:v0.5.0 -v5
...
Using Override="infrastructure-components.yaml" Provider="infrastructure-aws" Version="v0.5.0"
...
If you prefer to have the overrides directory at a different location (e.g.
/Users/foobar/workspace/dev-releases) you can specify the overrides
directory in the clusterctl config file as
overridesFolder: /Users/foobar/workspace/dev-releases
Note : It is possible to use the ${HOME} and ${CLUSTERCTL_REPOSITORY_PATH} environment variables in overridesFolder.
Image override is an advanced feature and wrong configuration can easily lead to non-functional clusters.
It’s strongly recommended to test configurations on dev/test environments before using this functionality in production.
This feature must always be used in conjunction with
version tag when executing clusterctl commands.
When working in air-gapped environments, it’s necessary to alter the manifests to be installed in order to pull
images from a local/custom image repository instead of public ones (e.g. gcr.io, or quay.io).
The clusterctl configuration file can be used to instruct clusterctl to override images automatically.
This can be achieved by adding an images configuration entry as shown in the example:
images:
all:
repository: myorg.io/local-repo
Please note that the image override feature allows for more fine-grained configuration, allowing to set image
overrides for specific components, for example:
images:
all:
repository: myorg.io/local-repo
cert-manager:
tag: v1.5.3
In this example we are overriding the image repository for all the components and the image tag for
all the images in the cert-manager component.
If required to alter only a specific image you can use:
images:
all:
repository: myorg.io/local-repo
cert-manager/cert-manager-cainjector:
tag: v1.5.3
To have more verbose logs you can use the -v flag when running the clusterctl and set the level of the logging verbose with a positive integer number, ie. -v 3.
If you do not want to use the flag every time you issue a command you can set the environment variable CLUSTERCTL_LOG_LEVEL or set the variable in the clusterctl config file located by default at $XDG_CONFIG_HOME/cluster-api/clusterctl.yaml.
clusterctl automatically checks for new versions every time it is used. If you do not want clusterctl to check for new updates you can set the environment variable CLUSTERCTL_DISABLE_VERSIONCHECK to "true" or set the variable in the clusterctl config file located by default at $XDG_CONFIG_HOME/cluster-api/clusterctl.yaml.
The clusterctl command is designed to work with all the providers compliant with the following rules.
Each provider MUST define a provider repository , that is a well-known place where the release assets for
a provider are published.
The provider repository MUST contain the following files:
The metadata YAML
The components YAML
Additionally, the provider repository SHOULD contain the following files:
Workload cluster templates
Optionally, the provider repository can include the following files:
The clusterctl command ships with a pre-defined list of provider repositories that allows a simpler “out-of-the-box” user experience.
As a provider implementer, if you are interested in being added to this list, please see next paragraph.
As a Cluster API project, we always have been more than happy to give visibility to all the open source CAPI providers
by allowing provider’s maintainers to add their own project to the pre-defined list of provider shipped with clusterctl.
Provider’s maintainer are the ultimately responsible for their own project.
Adding a provider to the clusterctl provider list does not imply any form of quality assessment, market screening,
entitlement, recognition or support by the Cluster API maintainers.
This is the process to add a new provider to the pre-defined list of providers shipped with clusterctl:
As soon as possible, create an issue to the Cluster API repository declaring the intent to add a new provider;
each provider must have a unique name & type in the pre-defined list of providers shipped with clusterctl; the provider’s name
must be declared in the issue above and abide to the following naming convention:
The name must consist of lower case alphanumeric characters or ‘-’, and must start and end with an alphanumeric character.
The name length should not exceed 63 characters.
For providers not in the kubernetes-sigs org, in order to prevent conflicts the clusterctl name must be prefixed with
the provider’s GitHub org name followed by - (see note below).
Create a PR making the necessary changes to clusterctl and the Cluster API book, e.g. #9798 ,
9720 .
The Cluster API maintainers will review issues/PRs for adding new providers. If the PR merges before code freeze deadline
for the next Cluster API minor release, changes will be included in the release, otherwise in the next minor
release. Maintainers will also consider if possible/convenient to backport to the current Cluster API minor release
branch to include it in the next patch release.
Closed source provider can not be added to the pre-defined list of provider shipped with clusterctl, however,
those providers could be used with clusterctl by changing the clusterctl configuration .
The need to add a prefix for providers not in the kubernetes-sigs org applies to all the providers being added to
clusterctl‘s pre-defined list of provider starting from January 2024. This rule doesn’t apply retroactively
to the existing pre-defined providers, but we reserve the right to reconsider this in the future.
Please note that the need to add a prefix for providers not in the kubernetes-sigs org does not apply to providers added by
changing the clusterctl configuration .
You can use a GitHub release to package your provider artifacts for other people to use.
A GitHub release can be used as a provider repository if:
The release tag is a valid semantic version number
The components YAML, the metadata YAML and eventually the workload cluster templates are included into the release assets.
See the GitHub docs for more information
about how to create a release.
Per default clusterctl will use a go proxy to detect the available versions to prevent additional
API calls to the GitHub API. It is possible to configure the go proxy url using the GOPROXY variable as
for go itself (defaults to https://proxy.golang.org).
To immediately fallback to the GitHub client and not use a go proxy, the environment variable could get set to
GOPROXY=off or GOPROXY=direct.
If a provider does not follow Go’s semantic versioning, clusterctl may fail when detecting the correct version.
In such cases, disabling the go proxy functionality via GOPROXY=off should be considered.
You can use a GitLab generic packages for provider artifacts.
A provider url should be in the form
https://{host}/api/v4/projects/{projectSlug}/packages/generic/{packageName}/{defaultVersion}/{componentsPath}, where:
{host} should start with gitlab. (gitlab.com, gitlab.example.org, ...){projectSlug} is either a project id (42) or escaped full path (myorg%2Fmyrepo){defaultVersion} is a valid semantic version numberThe components YAML, the metadata YAML and eventually the workload cluster templates are included into the same package version
See the GitLab docs for more information
about how to create a generic package.
This can be used in conjunction with GitLabracadabra
to avoid direct internet access from clusterctl, and use GitLab as artifacts repository. For example,
for the core provider:
Use the following action file :
external-packages/cluster-api:
packages_enabled: true
package_mirrors:
- github:
full_name: kubernetes-sigs/cluster-api
tags:
- v1.2.3
assets:
- clusterctl-linux-amd64
- core-components.yaml
- bootstrap-components.yaml
- control-plane-components.yaml
- metadata.yaml
Use the following clusterctl configuration
providers:
# override a pre-defined provider on a self-host GitLab
- name: "cluster-api"
url: "https://gitlab.example.com/api/v4/projects/external-packages%2Fcluster-api/packages/generic/cluster-api/v1.2.3/core-components.yaml"
type: "CoreProvider"
Limitation: Provider artifacts hosted on GitLab don’t support getting all versions.
As a consequence, you need to set version explicitly for upgrades.
clusterctl supports reading from a repository defined on the local file system.
A local repository can be defined by creating a <provider-label> folder with a <version> sub-folder for each hosted release;
the sub-folder name MUST be a valid semantic version number. e.g.
~/local-repository/infrastructure-aws/v0.5.2
Each version sub-folder MUST contain the corresponding components YAML, the metadata YAML and eventually the workload cluster templates.
The provider is required to generate a metadata YAML file and publish it to the provider’s repository.
The metadata YAML file documents the release series of each provider and maps each release series to an API Version of Cluster API (contract).
For example, for Cluster API:
apiVersion: clusterctl.cluster.x-k8s.io/v1alpha3
kind: Metadata
releaseSeries:
- major: 0
minor: 3
contract: v1alpha3
- major: 0
minor: 2
contract: v1alpha2
For clusterctl versions pre-v1alpha4, if provider implementers only update the clusterctl’s built-in metadata and don’t provide a metadata.yaml in a new release, users are forced to update clusterctl
to the latest released version in order to properly install the provider.
As a related example, see the details in issue 3418 .
To address the above explained issue, the embedded metadata within clusterctl has been removed (as of v1alpha4) to prevent the reliance on using the latest version of clusterctl in order to pull newer provider releases.
For more information see the details in issue 3515 .
The provider is required to generate a components YAML file and publish it to the provider’s repository.
This file is a single YAML with all the components required for installing the provider itself (CRDs, Controller, RBAC etc.).
The following rules apply:
It is strongly recommended that:
Core providers release a file called core-components.yaml
Infrastructure providers release a file called infrastructure-components.yaml
Bootstrap providers release a file called bootstrap-components.yaml
Control plane providers release a file called control-plane-components.yaml
IPAM providers release a file called ipam-components.yaml
Runtime extensions providers release a file called runtime-extension-components.yaml
Add-on providers release a file called addon-components.yaml
The instance components should contain one Namespace object, which will be used as the default target namespace
when creating the provider components.
All the objects in the components YAML MUST belong to the target namespace, with the exception of objects that
are not namespaced, like ClusterRoles/ClusterRoleBinding and CRD objects.
If the generated component YAML doesn’t contain a Namespace object, the user will be required to provide one to clusterctl init
using the --target-namespace flag.
In case there is more than one Namespace object in the components YAML, clusterctl will generate an error and abort
the provider installation.
Each provider is expected to deploy controllers/runtime extension server using a Deployment.
While defining the Deployment Spec, the container that executes the controller/runtime extension server binary MUST be called manager.
For controllers only, the manager MUST support a --namespace flag for specifying the namespace where the controller
will look for objects to reconcile; however, clusterctl will always install providers watching for all namespaces
(--namespace=""); for more details see support for multiple instances
for more context.
While defining Pods for Deployments, canonical names should be used for images.
The components YAML can contain environment variables matching the format ${VAR}; it is highly
recommended to prefix the variable name with the provider name e.g. ${AWS_CREDENTIALS}
clusterctl currently supports variables with leading/trailing spaces such
as: ${ VAR }, ${ VAR},${VAR }. However, these formats will be deprecated
in the near future. e.g. v1alpha4.
Formats such as ${VAR$FOO} are not supported.
clusterctl uses the library drone/envsubst to perform
variable substitution.
# If `VAR` is not set or empty, the default value is used. This is true for
# all the following formats.
${VAR:=default}
${VAR=default}
${VAR:-default}
Other functions such as substring replacement are also supported by the
library. See drone/envsubst for more information.
Additionally, each provider should create user facing documentation with the list of required variables and with all the additional
notes that are required to assist the user in defining the value for each variable.
The components YAML components should be labeled with
cluster.x-k8s.io/provider and the name of the provider. This will enable an
easier transition from kubectl apply to clusterctl.
As a reference you can consider the labels applied to the following
providers.
Provider Name Label
CAPI cluster.x-k8s.io/provider=cluster-api CABPK cluster.x-k8s.io/provider=bootstrap-kubeadm CABPM cluster.x-k8s.io/provider=bootstrap-microk8s CABPKK3S cluster.x-k8s.io/provider=bootstrap-kubekey-k3s CABPOCNE cluster.x-k8s.io/provider=bootstrap-ocne CABPK0S cluster.x-k8s.io/provider=bootstrap-k0smotron CACPK cluster.x-k8s.io/provider=control-plane-kubeadm CACPM cluster.x-k8s.io/provider=control-plane-microk8s CACPN cluster.x-k8s.io/provider=control-plane-nested CACPKK3S cluster.x-k8s.io/provider=control-plane-kubekey-k3s CACPOCNE cluster.x-k8s.io/provider=control-plane-ocne CACPK0S cluster.x-k8s.io/provider=control-plane-k0smotron CAPA cluster.x-k8s.io/provider=infrastructure-aws CAPB cluster.x-k8s.io/provider=infrastructure-byoh CAPC cluster.x-k8s.io/provider=infrastructure-cloudstack CAPD cluster.x-k8s.io/provider=infrastructure-docker CAPIM cluster.x-k8s.io/provider=infrastructure-in-memory CAPDO cluster.x-k8s.io/provider=infrastructure-digitalocean CAPG cluster.x-k8s.io/provider=infrastructure-gcp CAPH cluster.x-k8s.io/provider=infrastructure-hetzner CAPHV cluster.x-k8s.io/provider=infrastructure-hivelocity CAPIBM cluster.x-k8s.io/provider=infrastructure-ibmcloud CAPKK cluster.x-k8s.io/provider=infrastructure-kubekey CAPK cluster.x-k8s.io/provider=infrastructure-kubevirt CAPM3 cluster.x-k8s.io/provider=infrastructure-metal3 CAPN cluster.x-k8s.io/provider=infrastructure-nested CAPO cluster.x-k8s.io/provider=infrastructure-openstack CAPOCI cluster.x-k8s.io/provider=infrastructure-oci CAPP cluster.x-k8s.io/provider=infrastructure-packet CAPT cluster.x-k8s.io/provider=infrastructure-tinkerbell CAPV cluster.x-k8s.io/provider=infrastructure-vsphere CAPVC cluster.x-k8s.io/provider=infrastructure-vcluster CAPVCD cluster.x-k8s.io/provider=infrastructure-vcd CAPX cluster.x-k8s.io/provider=infrastructure-nutanix CAPZ cluster.x-k8s.io/provider=infrastructure-azure CAPOSC cluster.x-k8s.io/provider=infrastructure-outscale CAPK0S cluster.x-k8s.io/provider=infrastructure-k0smotron CAIPAMIC cluster.x-k8s.io/provider=ipam-in-cluster
An infrastructure provider could publish a cluster templates file to be used by clusterctl generate cluster.
This is single YAML with all the objects required to create a new workload cluster.
With ClusterClass enabled it is possible to have cluster templates with managed topologies. Cluster templates with managed
topologies require only the cluster object in the template and a corresponding ClusterClass definition.
The following rules apply:
Cluster templates MUST be stored in the same location as the component YAML and follow this naming convention:
The default cluster template should be named cluster-template.yaml.
Additional cluster template should be named cluster-template-{flavor}.yaml. e.g cluster-template-prod.yaml
{flavor} is the name the user can pass to the clusterctl generate cluster --flavor flag to identify the specific template to use.
Each provider SHOULD create user facing documentation with the list of available cluster templates.
The cluster template YAML MUST assume the target namespace already exists.
All the objects in the cluster template YAML MUST be deployed in the same namespace.
The cluster templates YAML can also contain environment variables (as can the components YAML).
Additionally, each provider should create user facing documentation with the list of required variables and with all the additional
notes that are required to assist the user in defining the value for each variable.
The clusterctl generate cluster command allows user to set a small set of common variables via CLI flags or command arguments.
Templates writers should use the common variables to ensure consistency across providers and a simpler user experience
(if compared to the usage of OS environment variables or the clusterctl config file).
CLI flag Variable name Note
--target-namespace${NAMESPACE}The namespace where the workload cluster should be deployed --kubernetes-version${KUBERNETES_VERSION}The Kubernetes version to use for the workload cluster --controlplane-machine-count${CONTROL_PLANE_MACHINE_COUNT}The number of control plane machines to be added to the workload cluster --worker-machine-count${WORKER_MACHINE_COUNT}The number of worker machines to be added to the workload cluster
Additionally, the value of the command argument to clusterctl generate cluster <cluster-name> (<cluster-name> in this case), will
be applied to every occurrence of the ${ CLUSTER_NAME } variable.
An infrastructure provider could publish a ClusterClass definition file to be used by clusterctl generate cluster that will be used along
with the workload cluster templates.
This is a single YAML with all the objects required that make up the ClusterClass.
The following rules apply:
ClusterClass definitions MUST be stored in the same location as the component YAML and follow this naming convention:
The ClusterClass definition should be named clusterclass-{ClusterClass-name}.yaml, e.g clusterclass-prod.yaml.
{ClusterClass-name} is the name of the ClusterClass that is referenced from the Cluster.spec.topology.class field
in the Cluster template; Cluster template files using a ClusterClass are usually simpler because they are no longer
required to have all the templates.
Each provider should create user facing documentation with the list of available ClusterClass definitions.
The ClusterClass definition YAML MUST assume the target namespace already exists.
The references in the ClusterClass definition should NOT specify a namespace.
It is recommended that none of the objects in the ClusterClass YAML should specify a namespace.
Even if technically possible, it is strongly recommended that none of the objects in the ClusterClass definitions are shared across multiple definitions;
this helps in preventing changing an object inadvertently impacting many ClusterClasses, and consequently, all the Clusters using those ClusterClasses.
Currently the ClusterClass definitions SHOULD NOT have any environment variables in them.
ClusterClass definitions files should not use variable substitution, given that ClusterClass and managed topologies provide an alternative model for variable definition.
A ClusterClass definition is automatically included in the output of clusterctl generate cluster if the cluster template uses a managed topology
and a ClusterClass with the same name does not already exists in the Cluster.
Each provider is responsible to ensure that all the providers resources (like e.g. VSphereCluster, VSphereMachine, VSphereVM etc.
for the vsphere provider) MUST have a Metadata.OwnerReferences entry that links directly or indirectly to a Cluster object.
Please note that all the provider specific resources that are referenced by the Cluster API core objects will get the OwnerReference
set by the Cluster API core controllers, e.g.:
The Cluster controller ensures that all the objects referenced in Cluster.Spec.InfrastructureRef get an OwnerReference
that links directly to the corresponding Cluster.
The Machine controller ensures that all the objects referenced in Machine.Spec.InfrastructureRef get an OwnerReference
that links to the corresponding Machine, and the Machine is linked to the Cluster through its own OwnerReference chain.
That means that, practically speaking, provider implementers are responsible for ensuring that the OwnerReferences
are set only for objects that are not directly referenced by Cluster API core objects, e.g.:
All the VSphereVM instances should get an OwnerReference that links to the corresponding VSphereMachine, and the VSphereMachine
is linked to the Cluster through its own OwnerReference chain.
Provider authors should be aware of the following transformations that clusterctl applies during component installation:
Variable substitution;
Enforcement of target namespace:
The name of the namespace object is set;
The namespace field of all the objects is set (with exception of cluster wide objects like e.g. ClusterRoles);
All components are labeled;
Provider authors should be aware of the following transformations that clusterctl applies during components installation:
Variable substitution;
Enforcement of target namespace:
The namespace field of all the objects are set;
The clusterctl command requires that both the components YAML and the cluster templates contain all the required
objects.
If, for any reason, the provider authors/YAML designers decide not to comply with this recommendation and e.g. to
implement links to external objects from a component YAML (e.g. secrets, aggregated ClusterRoles NOT included in the component YAML)
implement link to external objects from a cluster template (e.g. secrets, configMaps NOT included in the cluster template)
The provider authors/YAML designers should be aware that it is their responsibility to ensure the proper
functioning of clusterctl when using non-compliant component YAML or cluster templates.
Provider authors should be aware that clusterctl move command implements a discovery mechanism that considers:
All the Kind defined in one of the CRDs installed by clusterctl using clusterctl init (identified via the clusterctl.cluster.x-k8s.io label);
For each CRD, discovery collects:
All the objects from the namespace being moved only if the CRD scope is Namespaced.
All the objects if the CRD scope is Cluster.
All the ConfigMap objects from the namespace being moved.
All the Secret objects from the namespace being moved and from the namespaces where infrastructure providers are installed.
After completing discovery, clusterctl move moves to the target cluster only the objects discovered in the previous phase
that are compliant with one of the following rules:
The object is directly or indirectly linked to a Cluster object (linked through the OwnerReference chain).
The object is a secret containing a user provided certificate (linked to a Cluster object via a naming convention).
The object is directly or indirectly linked to a ClusterResourceSet object (through the OwnerReference chain).
The object is directly or indirectly linked to another object with the clusterctl.cluster.x-k8s.io/move-hierarchy
label, e.g. the infrastructure Provider ClusterIdentity objects (linked through the OwnerReference chain).
The object has the clusterctl.cluster.x-k8s.io/move label or the clusterctl.cluster.x-k8s.io/move-hierarchy label,
e.g. the CPI config secret.
Note. clusterctl.cluster.x-k8s.io/move and clusterctl.cluster.x-k8s.io/move-hierarchy labels could be applied
to single objects or at the CRD level (the label applies to all the objects).
Please note that during move:
Namespaced objects, if not existing in the target cluster, are created.
Namespaced objects, if already existing in the target cluster, are updated.
Namespaced objects are removed from the source cluster.
Global objects, if not existing in the target cluster, are created.
Global objects, if already existing in the target cluster, are not updated.
Global objects are not removed from the source cluster.
Namespaced objects which are part of an owner chain that starts with a global object (e.g. a secret containing
credentials for an infrastructure Provider ClusterIdentity) are treated as Global objects.
When using the “move” label, if the CRD is a global resource, the object is copied to the target cluster but not removed from the source cluster. It is up to the user to remove the source object as necessary.
If moving some of excluded object is required, the provider authors should create documentation describing the
exact move sequence to be executed by the user.
Additionally, provider authors should be aware that clusterctl move assumes all the provider’s Controllers respect the
Cluster.Spec.Paused field introduced in the v1alpha3 Cluster API specification. If a provider needs to perform extra work in response to a
cluster being paused, clusterctl move can be blocked from creating any resources on the destination
management cluster by annotating any resource to be moved with clusterctl.cluster.x-k8s.io/block-move.
Every object’s Status subresource, including every nested field (e.g. Status.Conditions), is never
restored during a move operation. A Status subresource should never contain fields that cannot
be recreated or derived from information in spec, metadata, or external systems.
Provider implementers should not store non-ephemeral data in the Status.
Status should be able to be fully rebuilt by controllers by observing the current state of resources.
This document describes how to use clusterctl during the development workflow.
A Cluster API development setup (go, git, kind v0.9 or newer, Docker v19.03 or newer etc.)
A local clone of the Cluster API GitHub repository
A local clone of the GitHub repositories for the providers you want to install
From the root of the local copy of Cluster API, you can build the clusterctl binary by running:
make clusterctl
The output of the build is saved in the bin/ folder; In order to use it you have to specify
the full path, create an alias or copy it into a folder under your $PATH.
Clusterctl by default uses artifacts published in the providers repositories ;
during the development workflow you may want to use artifacts from your local workstation.
There are two options to do so:
Use the overrides layer , when you want to override a single published artifact with a local one.
Create a local repository, when you want to avoid using published artifacts and use the local ones instead.
If you want to create a local artifact, follow these instructions:
In order to build artifacts for the CAPI core provider, the kubeadm bootstrap provider, the kubeadm control plane provider and the Docker infrastructure provider:
make docker-build REGISTRY=gcr.io/k8s-staging-cluster-api PULL_POLICY=IfNotPresent
Next, create a clusterctl-settings.json file and place it in your local copy
of Cluster API. This file will be used by create-local-repository.py . Here is an example:
{
"providers": ["cluster-api","bootstrap-kubeadm","control-plane-kubeadm", "infrastructure-aws", "infrastructure-docker"],
"provider_repos": ["../cluster-api-provider-aws"]
}
providers (Array[]String, default=[]): A list of the providers to enable.
See available providers for more details.
provider_repos (Array[]String, default=[]): A list of paths to all the providers you want to use. Each provider must have
a clusterctl-settings.json file describing how to build the provider assets.
Run the create-local-repository hack from the root of the local copy of Cluster API:
cmd/clusterctl/hack/create-local-repository.py
The script reads from the source folders for the providers you want to install, builds the providers’ assets,
and places them in a local repository folder located under $XDG_CONFIG_HOME/cluster-api/dev-repository/.
Additionally, the command output provides you the clusterctl init command with all the necessary flags.
The output should be similar to:
clusterctl local overrides generated from local repositories for the cluster-api, bootstrap-kubeadm, control-plane-kubeadm, infrastructure-docker, infrastructure-aws providers.
in order to use them, please run:
clusterctl init \
--core cluster-api:v0.3.8 \
--bootstrap kubeadm:v0.3.8 \
--control-plane kubeadm:v0.3.8 \
--infrastructure aws:v0.5.0 \
--infrastructure docker:v0.3.8 \
--config $XDG_CONFIG_HOME/cluster-api/dev-repository/config.yaml
As you might notice, the command is using the $XDG_CONFIG_HOME/cluster-api/dev-repository/config.yaml config file,
containing all the required setting to make clusterctl use the local repository (it fallbacks to $HOME if $XDG_CONFIG_HOME
is not set on your machine).
You must pass --config ... to all the clusterctl commands you are running during your dev session.
The above config file changes the location of the overrides layer folder thus ensuring
you dev session isn’t hijacked by other local artifacts.
With the exceptions of the Docker and the in memory provider, the local repository folder does not contain cluster templates,
so the clusterctl generate cluster command will fail if you don’t copy a template into the local repository.
if you want to run your tests using a Cluster API nightly build, you can run the hack passing the nightly build folder
(change the date at the end of the bucket name according to your needs):
cmd/clusterctl/hack/create-local-repository.py https://storage.googleapis.com/artifacts.k8s-staging-cluster-api.appspot.com/components/nightly_main_20240101
Note: this works only with core Cluster API nightly builds.
The following providers are currently defined in the script:
cluster-apibootstrap-kubeadmcontrol-plane-kubeadminfrastructure-docker
More providers can be added by editing the clusterctl-settings.json in your local copy of Cluster API;
please note that each provider_repo should have its own clusterctl-settings.json describing how to build the provider assets, e.g.
{
"name": "infrastructure-aws",
"config": {
"componentsFile": "infrastructure-components.yaml",
"nextVersion": "v0.5.0"
}
}
kind can provide a Kubernetes cluster to be used as a management cluster.
See Install and/or configure a Kubernetes cluster for more information.
Before running clusterctl init, you must ensure all the required images are available in the kind cluster.
This is always the case for images published in some image repository like Docker Hub or gcr.io, but it can’t be
the case for images built locally; in this case, you can use kind load to move the images built locally. e.g.
kind load docker-image gcr.io/k8s-staging-cluster-api/cluster-api-controller-amd64:dev
kind load docker-image gcr.io/k8s-staging-cluster-api/kubeadm-bootstrap-controller-amd64:dev
kind load docker-image gcr.io/k8s-staging-cluster-api/kubeadm-control-plane-controller-amd64:dev
kind load docker-image gcr.io/k8s-staging-cluster-api/capd-manager-amd64:dev
to make the controller images available for the kubelet in the management cluster.
When the kind cluster is ready and all the required images are in place, run
the clusterctl init command generated by the create-local-repository.py
script.
Optionally, you may want to check if the components are running properly. The
exact components are dependent on which providers you have initialized. Below
is an example output with the Docker provider being installed.
kubectl get deploy -A | grep "cap\|cert"
capd-system
capd-controller-manager 1/1 1 1 25m
capi-kubeadm-bootstrap-system capi-kubeadm-bootstrap-controller-manager 1/1 1 1 25m
capi-kubeadm-control-plane-system capi-kubeadm-control-plane-controller-manager 1/1 1 1 25m
capi-system capi-controller-manager 1/1 1 1 25m
cert-manager cert-manager 1/1 1 1 27m
cert-manager cert-manager-cainjector 1/1 1 1 27m
cert-manager cert-manager-webhook 1/1 1 1 27m
When selecting the --kubernetes-version, ensure that the kindest/node
image is available.
For example, assuming that on docker hub there is no
image for version vX.Y.Z, therefore creating a CAPD workload cluster with
--kubernetes-version=vX.Y.Z will fail. See issue 3795 for more details.
For Docker Desktop on macOS, Linux or Windows use kind to retrieve the kubeconfig.
kind get kubeconfig --name capi-quickstart > capi-quickstart.kubeconfig
Docker Engine for Linux works with the default clusterctl approach.
clusterctl get kubeconfig capi-quickstart > capi-quickstart.kubeconfig
When retrieving the kubeconfig using clusterctl with Docker Desktop on macOS or Windows or Docker Desktop (Docker Engine works fine) on Linux, you’ll need to take a few extra steps to get the kubeconfig for a workload cluster created with the Docker provider.
clusterctl get kubeconfig capi-quickstart > capi-quickstart.kubeconfig
To fix the kubeconfig run:
# Point the kubeconfig to the exposed port of the load balancer, rather than the inaccessible container IP.
sed -i -e "s/server:.*/server: https:\/\/$(docker port capi-quickstart-lb 6443/tcp | sed "s/0.0.0.0/127.0.0.1/")/g" ./capi-quickstart.kubeconfig
You can extend clusterctl with plugins, similar to kubectl. Please refer to the kubectl plugin documentation for more information,
as clusterctl plugins are implemented in the same way, with the exception of plugin distribution.
To install a clusterctl plugin, place the plugin’s executable file in any location on your PATH.
No plugin installation or pre-loading is required. Plugin executables inherit the environment from the clusterctl binary. A plugin determines the command it implements based on its name.
For example, a plugin named clusterctl-foo provides the clusterctl foo command. The plugin executable should be installed in your PATH.
Example plugin
#!/bin/bash
# optional argument handling
if [[ "$1" == "version" ]]
then
echo "1.0.0"
exit 0
fi
# optional argument handling
if [[ "$1" == "example-env-var" ]]
then
echo "$EXAMPLE_ENV_VAR"
exit 0
fi
echo "I am a plugin named clusterctl-foo"
To use a plugin, make the plugin executable:
sudo chmod +x ./clusterctl-foo
and place it anywhere in your PATH:
sudo mv ./clusterctl-foo /usr/local/bin
You may now invoke your plugin as a clusterctl command:
clusterctl foo
I am a plugin named clusterctl-foo
All args and flags are passed as-is to the executable:
clusterctl foo version
1.0.0
All environment variables are also passed as-is to the executable:
export EXAMPLE_ENV_VAR=example-value
clusterctl foo example-env-var
example-value
EXAMPLE_ENV_VAR=another-example-value clusterctl foo example-env-var
another-example-value
Additionally, the first argument that is passed to a plugin will always be the full path to the location where it was invoked ($0 would equal /usr/local/bin/clusterctl-foo in the example above).
A plugin determines the command path it implements based on its filename. Each sub-command in the path is separated by a dash (-). For example, a plugin for the command clusterctl foo bar baz would have the filename clusterctl-foo-bar-baz.
Cluster API is made up of many components, all of which need to be running for correct operation.
For example, if you wanted to use Cluster API with AWS , you’d need to install both the cluster-api manager and the aws manager .
Cluster API includes a built-in provisioner, Docker , that’s suitable for using for testing and development.
This guide will walk you through getting that daemon, known as CAPD , up and running.
Other providers may have additional steps you need to follow to get up and running.
Iterating on the cluster API involves repeatedly building Docker containers.
You’ll need the docker daemon v19.03 or newer available.
You’ll likely want an existing cluster as your management cluster .
The easiest way to do this is with kind v0.9 or newer, as explained in the quick start.
Make sure your cluster is set as the default for kubectl.
If it’s not, you will need to modify subsequent kubectl commands below.
If you’re using kind , you’ll need a way to push your images to a registry so they can be pulled.
You can instead side-load all images, but the registry workflow is lower-friction.
Most users test with GCR , but you could also use something like Docker Hub .
If you choose not to use GCR, you’ll need to set the REGISTRY environment variable.
You’ll need to install kustomize .
There is a version of kustomize built into kubectl, but it does not have all the features of kustomize v3 and will not work.
You’ll need to install kubebuilder .
You’ll need envsubstv1.0.3-0.20200709231038-aa43e1c1a629
We provide a make target to generate the envsubst binary if desired. See the provider contract for more details about how clusterctl uses variables.
make envsubst
The generated binary can be found at ./hack/tools/bin/envsubst
You’ll need to deploy cert-manager components on your management cluster , using kubectl
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.16.1/cert-manager.yaml
Ensure the cert-manager webhook service is ready before creating the Cluster API components.
This can be done by following instructions for manual verification
from the cert-manager web site.
Note: make sure to follow instructions for the release of cert-manager you are installing.
Tilt is a tool for quickly building, pushing, and reloading Docker containers as part of a Kubernetes deployment.
Many of the Cluster API engineers use it for quick iteration. Please see our Tilt instructions to get started.
# Build all the images
make docker-build
# Push images
make docker-push
# Apply the manifests
kustomize build config/default | ./hack/tools/bin/envsubst | kubectl apply -f -
kustomize build bootstrap/kubeadm/config/default | ./hack/tools/bin/envsubst | kubectl apply -f -
kustomize build controlplane/kubeadm/config/default | ./hack/tools/bin/envsubst | kubectl apply -f -
kustomize build test/infrastructure/docker/config/default | ./hack/tools/bin/envsubst | kubectl apply -f -
Cluster API has a number of test suites available for you to run. Please visit the testing page for more
information on each suite.
Now you can create CAPI objects !
To test another iteration, you’ll need to follow the steps to build, push, update the manifests, and apply.
CAPI components and architecture
Additional ClusterAPI KubeCon talks
Tutorials
Code walkthroughs
Let’s chat about ...
We are currently hosting “Let’s chat about ...” sessions where we are talking about topics relevant to
contributors and users of the Cluster API project. For more details and an up-to-date list of recordings of past sessions please
see Let’s chat about ... .
This page covers the repository structure and details about the directories in Cluster API.
cluster-api
└───.github
└───api
└───bootstrap
└───cmd
│ │ clusterctl
└───config
└───controllers
└───controlplane
└───dev
└───docs
└───errors
└───exp
└───feature
└───hack
└───internal
└───logos
└───scripts
└───test
└───util
└───version
└───webhooks
└───main.go
└───Makefile
~/.github
Contains GitHub workflow configuration and templates for Pull requests, bug reports etc.
~/api
This folder is used to store types and their related resources present in CAPI core. It includes things like API types, spec/status definitions, condition types, simple webhook implementation, autogenerated, deepcopy and conversion files. Some examples of Cluster API types defined in this package include Cluster, ClusterClass, Machine, MachineSet, MachineDeployment and MachineHealthCheck.
API folder has subfolders for each supported API version.
~/bootstrap
This folder contains Cluster API bootstrap provider Kubeadm (CABPK) which is a reference implementation of a Cluster API bootstrap provider. This folder contains the types and controllers responsible for generating a cloud-init or ignition configuration to turn a Machine into a Kubernetes Node. It is built and deployed as an independent provider alongside the Cluster API controller manager.
~/controlplane
This folder contains a reference implementation of a Cluster API Control Plane provider - KubeadmControlPlane. This package contains the API types and controllers required to instantiate and manage a Kubernetes control plane. It is built and deployed as an independent provider alongside the Cluster API controller manager.
~/test/infrastructure/docker
This folder contains a reference implementation of an infrastructure provider for the Cluster API project using Docker. This provider is intended for development purposes only.
~/cmd/clusterctl
This folder contains Clusterctl, a CLI that can be used to deploy Cluster API and providers, generate cluster manifests, read the status of a cluster, and much more.
~/config
This is a Kubernetes manifest folder containing application resource configuration as kustomize YAML definitions. These are generated from other folders in the repo using make generate-manifests
Some of the subfolders are:
~/config/certmanager - It contains manifests like self-signed issuer CR and certificate CR useful for cert manager.
~/config/crd - It contains CRDs generated from types defined in api folder
~/config/manager - It contains manifest for the deployment of core Cluster API manager.
~/config/rbac - Manifests for RBAC resources generated from kubebuilder markers defined in controllers.
~/config/webhook - Manifest for webhooks generated from the markers defined in the web hook implementations present in api folder.
Note: Additional config containing manifests can be found in the packages for KubeadmControlPlane , KubeadmBoostrap and Cluster API Provider Docker .
~/internal
This folder contains resources which are not meant to be used directly by users of Cluster API e.g. the implementation of controllers is present in ~/internal/controllers directory so that we can make changes in controller implementation without breaking users. This allows us to keep our api surface smaller and move faster.
~/controllers
This folder contains reconciler types which provide access to CAPI controllers present in ~/internal/controllers directory to our users. These types can be used by users to run any of the Cluster API controllers in an external program.
~/docs
This folder is a place for proposals, developer release guidelines and the Cluster API book.
~/logos
Cluster API related logos and artwork
~/hack
This folder has scripts used for building, testing and developer workflow.
~/scripts
This folder consists of CI scripts related to setup, build and e2e tests. These are mostly called by CI jobs.
~/dev
This folder has example configuration for integrating Cluster API development with tools like IDEs.
~/util
This folder contains utilities which are used across multiple CAPI package. These utils are also widely imported in provider implementations and by other users of CAPI.
~/feature
This package provides feature gate management used in Cluster API as well as providers. This implementation of feature gates is shared across all providers.
~/errors
This is a place for defining errors returned by CAPI. Error types defined here can be used by users of CAPI and the providers.
~/exp
This folder contains experimental features of CAPI. Experimental features are unreliable until they are promoted to the main repository. Each experimental feature is supposed to be present in a subfolder of ~/exp folder e.g. ClusterResourceSet is present inside ~/exp/addons folder. Historically, machine pool resources are not present in a sub-directory. Migrating them to a subfolder like ~/exp/machinepools is still pending as it can potentially break existing users who are relying on existing folder structure.
CRDs for experimental features are present outside ~/exp directory in ~/config folder. Also, these CRDs are deployed in the cluster irrespective of the feature gate value. These features can be enabled and disabled using feature gates supplied to the core Cluster API controller.
The api folder contains webhooks consisting of validators and defaults for many of the types in Cluster API.
~/internal/webhooks
This directory contains the implementation of some of the Cluster API webhooks. The internal implementation means that the methods supplied by this package cannot be imported by external code bases.
~/webhooks
This folder exposes the custom webhooks present in ~internal/webhooks to the users of CAPI.
Note: Additional webhook implementations can be found in the API packages for KubeadmControlPlane , KubeadmBoostrap and Cluster API Provider Docker .
This document describes how to use kind and Tilt for a simplified
workflow that offers easy deployments and rapid iterative builds.
Docker : v19.03 or newerkind : v0.23.0 or newerTilt : v0.30.8 or newerkustomize : provided via make kustomizeenvsubst : provided via make envsubsthelm : v3.7.1 or newerClone the Cluster API repository
locally
Clone the provider(s) you want to deploy locally as well
A script to create a KIND cluster along with a local Docker registry and the correct mounts to run CAPD is included in the hack/ folder.
To create a pre-configured cluster run:
./hack/kind-install-for-capd.sh
You can see the status of the cluster with:
kubectl cluster-info --context kind-capi-test
Next, create a tilt-settings.yaml file and place it in your local copy of cluster-api. Here is an example that uses the components from the CAPI repo:
default_registry: gcr.io/your-project-name-here
enable_providers:
- docker
- kubeadm-bootstrap
- kubeadm-control-plane
To use tilt to launch a provider with its own repo, using Cluster API Provider AWS here, tilt-settings.yaml should look like:
default_registry: gcr.io/your-project-name-here
provider_repos:
- ../cluster-api-provider-aws
enable_providers:
- aws
- kubeadm-bootstrap
- kubeadm-control-plane
If you prefer JSON, you can create a tilt-settings.json file instead. YAML will be preferred if both files are present.
allowed_contexts (Array, default=[]): A list of kubeconfig contexts Tilt is allowed to use. See the Tilt documentation on
allow_k8s_contexts for more details.
default_registry (String, default=[]): The image registry to use if you need to push images. See the Tilt
documentation for more details.
Please note that, in case you are not using a local registry, this value is required; additionally, the Cluster API
Tiltfile protects you from accidental push on gcr.io/k8s-staging-cluster-api.
build_engine (String, default=”docker”): The engine used to build images. Can either be docker or podman.
NB: the default is dynamic and will be “podman” if the string “Podman Engine” is found in docker version (or in podman version if the command fails).
kind_cluster_name (String, default=”capi-test”): The name of the kind cluster to use when preloading images.
provider_repos (Array[]String, default=[]): A list of paths to all the providers you want to use. Each provider must have a
tilt-provider.yaml or tilt-provider.json file describing how to build the provider.
enable_providers (Array[]String, default=[‘docker’]): A list of the providers to enable. See available providers
for more details.
template_dirs (Map{String: Array[]String}, default={”docker”: [
“./test/infrastructure/docker/templates”]}): A map of providers to directories containing cluster templates. An example of the field is given below. See Deploying a workload cluster for how this is used.
template_dirs:
docker:
- ./test/infrastructure/docker/templates
- <other-template-dir>
azure:
- <azure-template-dir>
aws:
- <aws-template-dir>
gcp:
- <gcp-template-dir>
kustomize_substitutions (Map{String: String}, default={}): An optional map of substitutions for ${}-style placeholders in the
provider’s yaml. These substitutions are also used when deploying cluster templates. See Deploying a workload cluster .
Note : When running E2E tests locally using an existing cluster managed by Tilt, the following substitutions are required for successful tests:
kustomize_substitutions:
CLUSTER_TOPOLOGY: "true"
EXP_KUBEADM_BOOTSTRAP_FORMAT_IGNITION: "true"
EXP_RUNTIME_SDK: "true"
EXP_MACHINE_SET_PREFLIGHT_CHECKS: "true"
deploy_observability ([string], default=[]): If set, installs on the dev cluster one of more observability
tools.
Important! This feature requires the helm command to be available in the user’s path.
Supported values are:
grafana*: To create dashboards and query loki, prometheus and tempo.kube-state-metrics: For exposing metrics for Kubernetes and CAPI resources to prometheus.loki: To receive and store logs.metrics-server: To enable kubectl top node/pod.prometheus*: For collecting metrics from Kubernetes.promtail: For providing pod logs to loki.parca*: For visualizing profiling data.tempo: To store traces.visualizer*: Visualize Cluster API resources for each cluster, provide quick access to the specs and status of any resource.
*: Note: the UI will be accessible via a link in the tilt console
additional_kustomizations (map[string]string, default={}): If set, install the additional resources built using kustomize to the cluster.
Example:
additional_kustomizations:
capv-metrics: ../cluster-api-provider-vsphere/config/metrics
debug (Map{string: Map} default{}): A map of named configurations for the provider. The key is the name of the provider.
Supported settings:
port (int, default=0 (disabled)): If set to anything other than 0, then Tilt will run the provider with delve
and port forward the delve server to localhost on the specified debug port. This can then be used with IDEs such as
Visual Studio Code, Goland and IntelliJ.
continue (bool, default=true): By default, Tilt will run delve with --continue, such that any provider with
debugging turned on will run normally unless specifically having a breakpoint entered. Change to false if you
do not want the controller to start at all by default.
profiler_port (int, default=0 (disabled)): If set to anything other than 0, then Tilt will enable the profiler with
--profiler-address and set up a port forward. A “profiler” link will be visible in the Tilt Web UI for the controller.
metrics_port (int, default=0 (disabled)): If set to anything other than 0, then Tilt will port forward to the
default metrics port. A “metrics” link will be visible in the Tilt Web UI for the controller.
race_detector (bool, default=false) (Linux amd64 only): If enabled, Tilt will compile the specified controller with
cgo and statically compile in the system glibc and enable the race detector. Currently, this is only supported when
building on Linux amd64 systems. You must install glibc-static or have libc.a available for this to work.
Example: Using the configuration below:
debug:
core:
continue: false
port: 30000
profiler_port: 40000
metrics_port: 40001
When using the example above, the core CAPI controller can be debugged in Visual Studio Code using the following launch configuration:
{
"version": "0.2.0",
"configurations": [
{
"name": "Core CAPI Controller",
"type": "go",
"request": "attach",
"mode": "remote",
"remotePath": "",
"port": 30000,
"host": "127.0.0.1",
"showLog": true,
"trace": "log",
"logOutput": "rpc"
}
]
}
With the above example, you can configure a Go Remote run/debug
configuration
pointing at port 30000.
deploy_cert_manager (Boolean, default=true): Deploys cert-manager into the cluster for use for webhook registration.
trigger_mode (String, default=auto): Optional setting to configure if tilt should automatically rebuild on changes.
Set to manual to disable auto-rebuilding and require users to trigger rebuilds of individual changed components through the UI.
extra_args (Object, default={}): A mapping of provider to additional arguments to pass to the main binary configured
for this provider. Each item in the array will be passed in to the manager for the given provider.
Example:
extra_args:
kubeadm-bootstrap:
- --logging-format=json
With this config, the respective managers will be invoked with:
manager --logging-format=json
To create a pre-configured kind cluster (if you have not already done so) and launch your development environment, run
make tilt-up
This will open the command-line HUD as well as a web browser interface. You can monitor Tilt’s status in either
location. After a brief amount of time, you should have a running development environment, and you should now be able to
create a cluster. There are example worker cluster
configs available.
These can be customized for your specific needs.
After your kind management cluster is up and running with Tilt, you can deploy a workload clusters in the Tilt web UI based off of YAML templates from the directories specified in
the template_dirs field from the tilt-settings.yaml file (default ./test/infrastructure/docker/templates).
Templates should be named according to clusterctl conventions:
template files must be named cluster-template-{name}.yaml; those files will be accessible in the Tilt web UI under the label grouping {provider-label}.templates, i.e. CAPD.templates.
cluster class files must be named clusterclass-{name}.yaml; those file will be accessible in the Tilt web UI under the label grouping {provider-label}.clusterclasses, i.e. CAPD.clusterclasses.
By selecting one of those items in the Tilt web UI set of buttons will appear, allowing to create - with a dropdown for customizing variable substitutions - or delete clusters.
Custom values for variable substitutions can be set using kustomize_substitutions in tilt-settings.yaml, e.g.
kustomize_substitutions:
NAMESPACE: "default"
KUBERNETES_VERSION: "v1.30.0"
CONTROL_PLANE_MACHINE_COUNT: "1"
WORKER_MACHINE_COUNT: "3"
# Note: kustomize substitutions expects the values to be strings. This can be achieved by wrapping the values in quotation marks.
After stopping Tilt, you can clean up your kind cluster and development environment by running
make clean-kind
To remove all generated files, run
make clean
Note that you must run make clean or make clean-charts to fetch new versions of charts deployed using deploy_observability in tilt-settings.yaml.
When the worker cluster has been created using tilt, clusterctl should not be used for management
operations; this is because tilt doesn’t initialize providers on the management cluster like clusterctl init does, so
some of the clusterctl commands like clusterctl config won’t work.
This limitation is an acceptable trade-off while executing fast dev-test iterations on controllers logic. If instead
you are interested in testing clusterctl workflows, you should refer to the
clusterctl developer instructions .
The following providers are currently defined in the Tiltfile:
core : cluster-api itselfkubeadm-bootstrap : kubeadm bootstrap providerkubeadm-control-plane : kubeadm control-plane providerdocker : Docker infrastructure providerin-memory : In-memory infrastructure providertest-extension : Runtime extension used by CAPI E2E tests
Additional providers can be added by following the procedure described in following paragraphs:
A provider must supply a tilt-provider.yaml file describing how to build it. Here is an example:
name: aws
config:
image: "gcr.io/k8s-staging-cluster-api-aws/cluster-api-aws-controller"
live_reload_deps: ["main.go", "go.mod", "go.sum", "api", "cmd", "controllers", "pkg"]
label: CAPA
If you prefer JSON, you can create a tilt-provider.json file instead. YAML will be preferred if both files are present.
image : the image for this provider, as referenced in the kustomize files. This must match; otherwise, Tilt won’t
build it.
live_reload_deps : a list of files/directories to watch. If any of them changes, Tilt rebuilds the manager binary
for the provider and performs a live update of the running container.
version : allows to define the version to be used for the Provider CR. If empty, a default version will
be used.
additional_docker_helper_commands (String, default=””): Additional commands to be run in the helper image
docker build. e.g.
RUN wget -qO- https://dl.k8s.io/v1.21.2/kubernetes-client-linux-amd64.tar.gz | tar xvz
RUN wget -qO- https://get.docker.com | sh
additional_docker_build_commands (String, default=””): Additional commands to be appended to
the dockerfile.
The manager image will use docker-slim, so to download files, use additional_helper_image_commands. e.g.
COPY --from=tilt-helper /usr/bin/docker /usr/bin/docker
COPY --from=tilt-helper /go/kubernetes/client/bin/kubectl /usr/bin/kubectl
kustomize_folder (String, default=config/default): The folder where the kustomize file for a provider
is defined; the path is relative to the provider root folder.
kustomize_options ([]String, default=[]): Options to be applied when running kustomize for generating the
yaml manifest for a provider. e.g. "kustomize_options": [ "--load-restrictor=LoadRestrictionsNone" ]
apply_provider_yaml (Bool, default=true): Whether to apply the provider yaml.
Set to false if your provider does not have a ./config folder or you do not want it to be applied in the cluster.
go_main (String, default=”main.go”): The go main file if not located at the root of the folder
label (String, default=provider name): The label to be used to group provider components in the tilt UI
in tilt version >= v0.22.2 (see https://blog.tilt.dev/2021/08/09/resource-grouping.html); as a convention,
provider abbreviation should be used (CAPD, KCP etc.).
additional_resources ([]string, default=[]): A list of paths to yaml file to be loaded into the tilt cluster;
e.g. use this to deploy an ExtensionConfig object for a RuntimeExtension provider.
resource_deps ([]string, default=[]): A list of tilt resource names to be installed before the current provider;
e.g. set this to [“capi_controller”] to ensure that this provider gets installed after Cluster API.
If you need to customize Tilt’s behavior, you can create files in cluster-api’s tilt.d directory. This file is ignored
by git so you can be assured that any files you place here will never be checked in to source control.
These files are included after the providers map has been defined and after all the helper function definitions. This
is immediately before the “real work” happens.
At a high level, the Tiltfile performs the following actions:
Read tilt-settings.yaml
Configure the allowed Kubernetes contexts
Set the default registry
Define the providers map
Include user-defined Tilt files
Deploy cert-manager
Enable providers (core + what is listed in tilt-settings.yaml)
Build the manager binary locally as a local_resource
Invoke docker_build for the provider
Invoke kustomize for the provider’s config/ directory
Each provider in the providers map has a live_reload_deps list. This defines the files and/or directories that Tilt
should monitor for changes. When a dependency is modified, Tilt rebuilds the provider’s manager binary on your local
machine , copies the binary to the running container, and executes a restart script. This is significantly faster
than rebuilding the container image for each change. It also helps keep the size of each development image as small as
possible (the container images do not need the entire go toolchain, source code, module dependencies, etc.).
For IntelliJ, Syntax highlighting for the Tiltfile can be configured with a TextMate Bundle. For instructions, please see:
Tiltfile TextMate Bundle .
For VSCode the Bazel plugin can be used, it provides
syntax highlighting and auto-formatting. To enable it for Tiltfile a file association has to be configured via user settings:
"files.associations": {
"Tiltfile": "starlark",
},
Podman can be used instead of Docker by following these actions:
Enable the podman unix socket:
on Linux/systemd: systemctl --user enable --now podman.socket
on macOS: create a podman machine with podman machine init
Set build_engine to podman in tilt-settings.yaml (optional, only if both Docker & podman are installed)
Define the env variable DOCKER_HOST to the right socket:
on Linux/systemd: export DOCKER_HOST=unix:///run/user/$(id -u)/podman/podman.sock
on macOS: export DOCKER_HOST=$(podman machine inspect <machine> | jq -r '.[0].ConnectionInfo.PodmanSocket.Path') where <machine> is the podman machine name
Run tilt up
NB: The socket defined by DOCKER_HOST is used only for the hack/tools/internal/tilt-prepare command, the image build is running the podman build/podman push commands.
Sometimes tilt looks stuck when it’s waiting on connections.
Ensure that docker/podman is up and running and your kubernetes cluster is reachable.
Ensure the cluster in the default context is reachable by running kubectl cluster-info
Switch to the right context with kubectl config use-context
Ensure the context is allowed, see allowed_contexts field
Ensure the docker daemon is running ;) or for podman see Using Podman
If a DOCKER_HOST is specified:
check that the DOCKER_HOST has the correct prefix (usually unix://)
ensure docker/podman is listening on $DOCKER_HOST using fuser / lsof / netstat -u
Ensure the default_registry field
By default all registries except localhost:5000 are accessed via HTTPS.
If you run a HTTP registry you may have to configure the registry in docker/podman.
For example, in podman a localhost:5001 registry configuration should be declared in /etc/containers/registries.conf.d with this content:
[[registry]]
location = "localhost:5001"
insecure = true
NB: on macOS this configuration should be done in the podman machine by running podman machine ssh <machine>.
You may try manually to load images in kind by running:
kind load docker-image --name=<kind_cluster> <image>
If you are running podman, you may have hit this bug: https://github.com/kubernetes-sigs/kind/issues/2760
The workaround is to create a docker symlink to your podman executable and try to load the images again.
The Cluster API project is committed to improving the SRE/developer experience when troubleshooting issues, and logging
plays an important part in this goal.
In Cluster API we strive to follow three principles while implementing logging:
Logs are for SRE & developers, not for end users!
Whenever an end user is required to read logs to understand what is happening in the system, most probably there is an
opportunity for improvement of other observability in our API, like e.g. conditions and events.Navigating logs should be easy :
We should make sure that SREs/Developers can easily drill down logs while investigating issues, e.g. by allowing to
search all the log entries for a specific Machine object, eventually across different controllers/reconciler logs.Cluster API developers MUST use logs!
As Cluster API contributors you are not only the ones that implement logs, but also the first users of them. Use it!
Provide feedback!
Kubernetes defines a set of logging conventions ,
as well as tools and libraries for logging.
The foundational items of Cluster API logging are:
Support for structured logging in all the Cluster API controllers (see log format ).
Using contextual logging (see contextual logging ).
Adding a minimal set of key/value pairs in the logger at the beginning of each reconcile loop, so all the subsequent
log entries will inherit them (see key value pairs ).
Starting from the above foundations, then the long tail of small improvements will consist of following activities:
Improve consistency of additional key/value pairs added by single log entries (see key value pairs ).
Improve log messages (see log messages ).
Improve consistency of log levels (see log levels ).
Controllers MUST provide support for structured logging
and for the JSON output format ;
quoting the Kubernetes documentation, these are the key elements of this approach:
Separate a log message from its arguments.
Treat log arguments as key-value pairs.
Be easily parsable and queryable.
Cluster API uses all the tooling provided by the Kubernetes community to implement structured logging: Klog , a
logr wrapper that works with controller runtime, and other utils for exposing flags
in the controller’s main.go.
Ideally, in a future release of Cluster API we will make JSON output format the default format for all the Cluster API
controllers (currently the default is still text format).
Contextual logging
is the practice of using a log stored in the context across the entire chain of calls of a reconcile
action. One of the main advantages of this approach is that key value pairs which are added to the logger at the
beginning of the chain are then inherited by all the subsequent log entries created down the chain.
Contextual logging is also embedded in controller runtime; In Cluster API we use contextual logging via controller runtime’s
LoggerFrom(ctx) and LoggerInto(ctx, log) primitives and this ensures that:
The logger passed to each reconcile call has a unique reconcileID, so all the logs being written during a single
reconcile call can be easily identified (note: controller runtime also adds other useful key value pairs by default).
The logger has a key value pair identifying the objects being reconciled,e.g. a Machine Deployment, so all the logs
impacting this object can be easily identified.
Cluster API developer MUST ensure that:
The logger has a set of key value pairs identifying the hierarchy of objects the object being reconciled belongs to,
e.g. the Cluster a Machine Deployment belongs to, so it will be possible to drill down logs for related Cluster API
objects while investigating issues.
One of the key elements of structured logging is key-value pairs.
Having consistent key value pairs is a requirement for ensuring readability and for providing support for searching and
correlating lines across logs.
A set of good practices for defining key value pairs is defined in the Kubernetes Guidelines , and
one of the above practices is really important for Cluster API developers
Developers MUST use klog.KObj or klog.KRef functions when logging key value pairs for Kubernetes objects, thus
ensuring a key value pair representing a Kubernetes object is formatted consistently in all the logs.
Please note that, in order to ensure logs can be easily searched it is important to ensure consistency for the following
key value pairs (in order of importance):
Key value pairs identifying the object being reconciled, e.g. a Machine Deployment.
Key value pairs identifying the hierarchy of objects being reconciled, e.g. the Cluster a Machine Deployment belongs
to.
Key value pairs identifying side effects on other objects, e.g. while reconciling a MachineDeployment, the controller
creates a MachinesSet.
Other Key value pairs.
A Message MUST always start with a capital letter.
Period at the end of a message MUST be omitted.
Always prefer logging before the action, so in case of errors there will be an immediate, visual correlation between
the action log and the corresponding error log; While logging before the action, log verbs should use the -ing form.
Ideally log messages should surface a different level of detail according to the target log level (see log levels
for more details).
Kubernetes provides a set of recommendations
for log levels; as a small integration on the above guidelines we would like to add:
Logs at the lower levels of verbosity (<=3) are meant to document “what happened” by describing how an object status
is being changed by controller/reconcilers across subsequent reconciliations; as a rule of thumb, it is reasonable
to assume that a person reading those logs has a deep knowledge of how the system works, but it should not be required
for those persons to have knowledge of the codebase.
Logs at higher levels of verbosity (>=4) are meant to document “how it happened”, providing insight on thorny parts of
the code; a person reading those logs usually has deep knowledge of the codebase.
Don’t use verbosity higher than 5.
We are using log level 2 as a default verbosity for all core Cluster API
controllers as recommended by the Kubernetes guidelines.
When developing logs there are operational trade-offs to take into account, e.g. verbosity vs space allocation, user
readability vs machine readability, maintainability of the logs across the code base.
A reasonable approach for logging is to keep things simple and implement more log verbosity selectively and only on
thorny parts of code. Over time, based on feedback from SRE/developers, more logs can be added to shed light where necessary.
Our Tilt setup offers a batteries-included log suite based on Promtail , Loki and Grafana .
We are working to continuously improving this experience, allowing Cluster API developers to use logs and improve them as part of their development process.
For the best experience exploring the logs using Tilt:
Set --logging-format=json.
Set a high log verbosity, e.g. v=5.
Enable Promtail, Loki, and Grafana under deploy_observability.
A minimal example of a tilt-settings.yaml file that deploys a ready-to-use logging suite looks like:
deploy_observability:
- promtail
- loki
- grafana
enable_providers:
- docker
- kubeadm-bootstrap
- kubeadm-control-plane
extra_args:
core:
- "--logging-format=json"
- "--v=5"
docker:
- "--v=5"
- "--logging-format=json"
kubeadm-bootstrap:
- "--v=5"
- "--logging-format=json"
kubeadm-control-plane:
- "--v=5"
- "--logging-format=json"
The above options can be combined with other settings from our Tilt setup. Once Tilt is up and running with these settings users will be able to browse logs using the Grafana Explore UI.
This will normally be available on localhost:3001. To explore logs from Loki, open the Explore interface for the DataSource ‘Loki’. This link should work as a shortcut with the default Tilt settings.
In the Log browser the following queries can be used to browse logs by controller, and by specific Cluster API objects. For example:
{app="capi-controller-manager"} | json
Will return logs from the capi-controller-manager which are parsed in json. Passing the query through the json parser allows filtering by key-value pairs that are part of nested json objects. For example .cluster.name becomes cluster_name.
{app="capi-controller-manager"} | json | Cluster_name="my-cluster"
Will return logs from the capi-controller-manager that are associated with the Cluster my-cluster.
{app="capi-controller-manager"} | json | Cluster_name="my-cluster" | v <= 2
Will return logs from the capi-controller-manager that are associated with the Cluster my-cluster with log level <= 2.
{app="capi-controller-manager"} | json | Cluster_name="my-cluster" reconcileID="6f6ad971-bdb6-4fa3-b803-xxxxxxxxxxxx"
Will return logs from the capi-controller-manager, associated with the Cluster my-cluster and the Reconcile ID 6f6ad971-bdb6-4fa3-b803-xxxxxxxxxxxx. Each reconcile loop will have a unique Reconcile ID.
{app="capi-controller-manager"} | json | Cluster_name="my-cluster" reconcileID="6f6ad971-bdb6-4fa3-b803-ef81c5c8f9d0" controller="cluster" | line_format "{{ .msg }}"
Will return logs from the capi-controller-manager, associated with the Cluster my-cluster and the Reconcile ID 6f6ad971-bdb6-4fa3-b803-xxxxxxxxxxxx it further selects only those logs which come from the Cluster controller. It will then format the logs so only the message is displayed.
{app=~"capd-controller-manager|capi-kubeadm-bootstrap-controller-manager|capi-kubeadm-control-plane-controller-manager"} | json | Cluster_name="my-cluster" Machine_name="my-cluster-linux-worker-1" | line_format "{{.controller}} {{.msg}}"
Will return the logs from four CAPI providers - the Core provider, Kubeadm Control Plane provider, Kubeadm Bootstrap provider and the Docker infrastructure provider. It filters by the cluster name and the machine name and then formats the log lines to show just the source controller and the message. This allows us to correlate logs and see actions taken by each of these four providers related to the machine my-cluster-linux-worker-1.
For more information on formatting and filtering logs using Grafana and Loki see:
Cluster API providers are developed by independent teams, and each team is free to define their own processes and
conventions.
However, given that SRE/developers looking at logs are often required to look both at logs from core CAPI and providers,
we encourage providers to adopt and contribute to the guidelines defined in this document.
It is also worth noting that the foundational elements of the approach described in this document are easy to achieve
by leveraging default Kubernetes tooling for logging.
This document presents testing guidelines and conventions for Cluster API.
IMPORTANT: improving and maintaining this document is a collaborative effort, so we are encouraging constructive
feedback and suggestions.
Unit tests focus on individual pieces of logic - a single func - and don’t require any additional services to execute. They should
be fast and great for getting the first signal on the current implementation, but unit tests have the risk of
allowing integration bugs to slip through.
In Cluster API most of the unit tests are developed using go test , gomega and the fakeclient ; however using
fakeclient is not suitable for all the use cases due to some limitations in how it is implemented. In some cases
contributors will be required to use envtest . See the quick reference below for more details.
In some cases when writing tests it is required to mock external API, e.g. etcd client API or the AWS SDK API.
This problem is usually well scoped in core Cluster API, and in most cases it is already solved by using fake
implementations of the target API to be injected during tests.
Instead, mocking is much more relevant for infrastructure providers; in order to address the issue
some providers can use simulators reproducing the behaviour of a real infrastructure providers (e.g CAPV);
if this is not possible, a viable solution is to use mocks (e.g CAPA).
When writing tests core Cluster API contributors should ensure that the code works with any providers, and thus it is required
to not use any specific provider implementation. Instead, the so-called generic providers e.g. “GenericInfrastructureCluster”
should be used because they implement the plain Cluster API contract. This prevents tests from relying on assumptions that
may not hold true in all cases.
Please note that in the long term we would like to improve the implementation of generic providers, centralizing
the existing set of utilities scattered across the codebase, but while details of this work will be defined do not
hesitate to reach out to reviewers and maintainers for guidance.
Integration tests are focused on testing the behavior of an entire controller or the interactions between two or
more Cluster API controllers.
In Cluster API, integration tests are based on envtest and one or more controllers configured to run against
the test cluster.
With this approach it is possible to interact with Cluster API almost like in a real environment, by creating/updating
Kubernetes objects and waiting for the controllers to take action. See the quick reference below for more details.
Also in case of integration tests, considerations about mocking external APIs and usage of generic providers apply.
Fuzzing tests automatically inject randomly generated inputs, often invalid or with unexpected values, into functions to discover vulnerabilities.
Two different types of fuzzing are currently being used on the Cluster API repository:
Cluster API uses Kubernetes’ conversion-gen to automate the generation of functions to convert our API objects between versions. These conversion functions are tested using the FuzzTestFunc util in our conversion utils package .
For more information about these conversions see the API conversion code walkthrough in our video walkthrough series .
Parts of the CAPI code base are continuously fuzzed through the OSS-Fuzz project . Issues found in these fuzzing tests are reported to Cluster API maintainers and surfaced in issues on the repo for resolution.
To read more about the integration of Cluster API with OSS Fuzz see the 2022 Cluster API Fuzzing Report .
Tests are an integral part of the project codebase.
Cluster API maintainers and all the contributors should be committed to help in ensuring that tests are easily maintainable,
easily readable, well documented and consistent across the code base.
In light of continuing improving our practice around this ambitious goal, we are starting to introduce a shared set of:
Builders (sigs.k8s.io/cluster-api/internal/test/builder), allowing to create test objects in a simple and consistent way.
Matchers (sigs.k8s.io/controller-runtime/pkg/envtest/komega), improving how we write test assertions.
Each contribution in growing this set of utilities or their adoption across the codebase is more than welcome!
Another consideration that can help in improving test maintainability is the idea of testing “by layers”; this idea could
apply whenever we are testing “higher-level” functions that internally uses one or more “lower-level” functions;
in order to avoid writing/maintaining redundant tests, whenever possible contributors should take care of testing
only the logic that is implemented in the “higher-level” function, delegating the test function called internally
to a “lower-level” set of unit tests.
A similar concern could be raised also in the case whenever there is overlap between unit tests and integration tests,
but in this case the distinctive value of the two layers of testing is determined by how test are designed:
unit test are focused on code structure: func(input) = output, including edge case values, asserting error conditions etc.
integration test are user story driven: as a user, I want express some desired state using API objects, wait for the
reconcilers to take action, check the new system state.
Run make test to execute all unit and integration tests.
Integration tests use the envtest test framework. The tests need to know the location of the executables called by the framework. The make test target installs these executables, and passes this location to the tests as an environment variable.
When testing individual packages, you can speed up the test execution by running the tests with a local kind cluster.
This avoids spinning up a testenv with each test execution. It also makes it easier to debug, because it’s straightforward
to access a kind cluster with kubectl during test execution. For further instructions, run: ./hack/setup-envtest-with-kind.sh.
When running individual tests, it could happen that a testenv is started if this is required by the suite_test.go file.
However, if the tests you are running don’t require testenv (i.e. they are only using fake client), you can skip the testenv
creation by setting the environment variable CAPI_DISABLE_TEST_ENV (to any non-empty value).
To debug testenv unit tests it is possible to use:
CAPI_TEST_ENV_KUBECONFIG to write out a kubeconfig for the testenv to a file location.CAPI_TEST_ENV_SKIP_STOP to skip stopping the testenv after test execution.
Your IDE needs to know the location of the executables called by the framework, so that it can pass the location to the tests as an environment variable.
If you see this error when running a test in your IDE, the test uses the envtest framework, and probably does not know the location of the envtest executables.
E0210 16:11:04.222471 132945 server.go:329] controller-runtime/test-env "msg"="unable to start the controlplane" "error"="fork/exec /usr/local/kubebuilder/bin/etcd: no such file or directory" "tries"=0
The dev/vscode-example-configuration directory in the repository contains an example configuration that integrates VSCode with the envtest framework.
To use the example configuration, copy the files to the .vscode directory in the repository, and restart VSCode.
The configuration works as follows: Whenever the project is opened in VSCode, a VSCode task runs that installs the executables, and writes the location to a file. A setting tells vscode-go to initialize the environment from this file.
The end-to-end tests are meant to verify the proper functioning of a Cluster API management cluster
in an environment that resemble a real production environment.
The following guidelines should be followed when developing E2E tests:
See e2e development for more information on developing e2e tests for CAPI and external providers.
Usually the e2e tests are executed by Prow, either pre-submit (on PRs) or periodically on certain branches
(e.g. the default branch). Those jobs are defined in the kubernetes/test-infra repository in config/jobs/kubernetes-sigs/cluster-api .
For development and debugging those tests can also be executed locally.
make docker-build-e2e will build the images for all providers that will be needed for the e2e tests.
To run a test locally via the command line, you should look at the Prow Job configuration for the test you want to run and then execute the same commands locally.
For example to run pull-cluster-api-e2e-main
just execute:
GINKGO_FOCUS="\[PR-Blocking\]" ./scripts/ci-e2e.sh
make test-e2e will run e2e tests by using whatever provider images already exist on disk.
After running make docker-build-e2e at least once, make test-e2e can be used for a faster test run, if there are no
provider code changes. If the provider code is changed, run make docker-build-e2e to update the images.
It’s also possible to run the tests via an IDE which makes it easier to debug the test code by stepping through the code.
First, we have to make sure all prerequisites are fulfilled, i.e. all required images have been built (this also includes
kind images). This can be done by executing the ./scripts/ci-e2e.sh script.
# Notes:
# * You can cancel the script as soon as it starts the actual test execution via `make test-e2e`.
# * If you want to run other tests (e.g. upgrade tests), make sure all required env variables are set (see the Prow Job config).
GINKGO_FOCUS="\[PR-Blocking\]" ./scripts/ci-e2e.sh
Now, the tests can be run in an IDE. The following describes how this can be done in IntelliJ IDEA and VS Code. It should work
roughly the same way in all other IDEs. We assume the cluster-api repository has been checked
out into /home/user/code/src/sigs.k8s.io/cluster-api.
Create a new run configuration and fill in:
Test framework: gotest
Test kind: Package
Package path: sigs.k8s.io/cluster-api/test/e2e
Pattern: ^\QTestE2E\E$
Working directory: /home/user/code/src/sigs.k8s.io/cluster-api/test/e2e
Environment: ARTIFACTS=/home/user/code/src/sigs.k8s.io/cluster-api/_artifacts
Program arguments: -e2e.config=/home/user/code/src/sigs.k8s.io/cluster-api/test/e2e/config/docker.yaml -ginkgo.focus="\[PR-Blocking\]"
Add the launch.json file in the .vscode folder in your repo:
{
"version": "0.2.0",
"configurations": [
{
"name": "Run e2e test",
"type": "go",
"request": "launch",
"mode": "test",
"program": "${workspaceRoot}/test/e2e/e2e_suite_test.go",
"env": {
"ARTIFACTS":"${workspaceRoot}/_artifacts"
},
"args": [
"-e2e.config=${workspaceRoot}/test/e2e/config/docker.yaml",
"-ginkgo.focus=\\[PR-Blocking\\]",
"-ginkgo.v=true"
],
"trace": "verbose",
"buildFlags": "-tags 'e2e'",
"showGlobalVariables": true
}
]
}
Execute the run configuration with Debug.
The e2e tests create a new management cluster with kind on each run. To avoid this and speed up the test execution the tests can
also be run against a management cluster created by tilt :
# Create a kind cluster
./hack/kind-install-for-capd.sh
# Set up the management cluster via tilt
tilt up
Now you can start the e2e test via IDE as described above but with the additional -e2e.use-existing-cluster=true flag.
Note : This can also be used to debug controllers during e2e tests as described in Developing Cluster API with Tilt .
The e2e tests also create a local clusterctl repository. After it has been created on a first test execution this step can also be
skipped by setting -e2e.clusterctl-config=<ARTIFACTS>/repository/clusterctl-config.yaml. This also works with a clusterctl repository created
via Create the local repository .
Feature gates : E2E tests often use features which need to be enabled first. Make sure to enable the feature gates in the tilt settings file:
kustomize_substitutions:
CLUSTER_TOPOLOGY: "true"
EXP_KUBEADM_BOOTSTRAP_FORMAT_IGNITION: "true"
EXP_RUNTIME_SDK: "true"
EXP_MACHINE_SET_PREFLIGHT_CHECKS: "true"
To run a subset of tests, a combination of either one or both of GINKGO_FOCUS and GINKGO_SKIP env variables can be set.
Each of these can be used to match tests, for example:
[PR-Blocking] => Sanity tests run before each PR merge[K8s-Upgrade] => Tests which verify k8s component version upgrades on workload clusters[Conformance] => Tests which run the k8s conformance suite on workload clusters[ClusterClass] => Tests which use a ClusterClass to create a workload clusterWhen testing KCP.* => Tests which start with When testing KCP
For example:
GINKGO_FOCUS="\\[PR-Blocking\\]" make test-e2e can be used to run the sanity E2E tests
GINKGO_SKIP="\\[K8s-Upgrade\\]" make test-e2e can be used to skip the upgrade E2E tests
The following env variables can be set to customize the test execution:
GINKGO_FOCUS to set ginkgo focus (default empty - all tests)GINKGO_SKIP to set ginkgo skip (default empty - to allow running all tests)GINKGO_NODES to set the number of ginkgo parallel nodes (default to 1)E2E_CONF_FILE to set the e2e test config file (default to ${REPO_ROOT}/test/e2e/config/docker.yaml)ARTIFACTS to set the folder where test artifact will be stored (default to ${REPO_ROOT}/_artifacts)SKIP_RESOURCE_CLEANUP to skip resource cleanup at the end of the test (useful for problem investigation) (default to false)USE_EXISTING_CLUSTER to use an existing management cluster instead of creating a new one for each test run (default to false)GINKGO_NOCOLOR to turn off the ginkgo colored output (default to false)
Furthermore, it’s possible to overwrite all env variables specified in variables in test/e2e/config/docker.yaml.
Logs of e2e tests can be analyzed with our development environment by pushing logs to Loki and then
analyzing them via Grafana.
Start the development environment as described in Developing Cluster API with Tilt .
Make sure to deploy Loki and Grafana via deploy_observability.
If you only want to see imported logs, don’t deploy promtail (via deploy_observability).
If you want to drop all logs from Loki, just delete the Loki Pod in the observability namespace.
You can then import logs via the Import Logs button on the top right of the Loki resource page .
Just click on the downwards arrow, enter either a ProwJob URL, a GCS path or a local folder and click on Import Logs.
This will retrieve the logs and push them to Loki. Alternatively, the logs can be imported via:
go run ./hack/tools/internal/log-push --log-path=<log-path>
ProwJob URL: https://prow.k8s.io/view/gs/kubernetes-jenkins/pr-logs/pull/kubernetes-sigs_cluster-api/6189/pull-cluster-api-e2e-main/1496954690603061248
GCS path: gs://kubernetes-jenkins/pr-logs/pull/kubernetes-sigs_cluster-api/6189/pull-cluster-api-e2e-main/1496954690603061248
Local folder: ./_artifacts
Now the logs are available:
Make sure you query the correct time range via Grafana or logcli.
The logs are currently uploaded by using now as the timestamp, because otherwise it would
take a few minutes until the logs show up in Loki. The original timestamp is preserved as original_ts.
As alternative to loki, JSON logs can be visualized with a human readable timestamp using jq:
Browse the ProwJob artifacts and download the wanted logfile.
Use jq to query the logs:
cat manager.log \
| grep -v "TLS handshake error" \
| jq -r '(.ts / 1000 | todateiso8601) + " " + (. | tostring)'
The (. | tostring) part could also be customized to only output parts of the JSON logline.
E.g.:
(.err) to only output the error message part.(.msg) to only output the message part.(.controller + " " + .msg) to output the controller name and message part.
Cluster API repositories use Moby Buildkit to speed up image builds.
BuildKit does not currently work on SELinux .
Use sudo setenforce 0 to make SELinux permissive when running e2e tests.
envtest is a testing environment that is provided by the controller-runtime project. This environment spins up a
local instance of etcd and the kube-apiserver. This allows tests to be executed in an environment very similar to a
real environment.
Additionally, in Cluster API there is a set of utilities under [internal/envtest] that helps developers in setting up
a envtest ready for Cluster API testing, and more specifically:
With the required CRDs already pre-configured.
With all the Cluster API webhook pre-configured, so there are enforced guarantees about the semantic accuracy
of the test objects you are going to create.
This is an example of how to create an instance of envtest that can be shared across all the tests in a package;
by convention, this code should be in a file named suite_test.go:
var (
env *envtest.Environment
ctx = ctrl.SetupSignalHandler()
)
func TestMain(m *testing.M) {
// Setup envtest
...
// Run tests
os.Exit(envtest.Run(ctx, envtest.RunInput{
M: m,
SetupEnv: func(e *envtest.Environment) { env = e },
SetupIndexes: setupIndexes,
SetupReconcilers: setupReconcilers,
}))
}
Most notably, envtest provides not only a real API server to use during testing, but it offers the opportunity
to configure one or more controllers to run against the test cluster, as well as creating informers index.
func TestMain(m *testing.M) {
// Setup envtest
setupReconcilers := func(ctx context.Context, mgr ctrl.Manager) {
if err := (&MyReconciler{
Client: mgr.GetClient(),
Log: log.NullLogger{},
}).SetupWithManager(mgr, controller.Options{MaxConcurrentReconciles: 1}); err != nil {
panic(fmt.Sprintf("Failed to start the MyReconciler: %v", err))
}
}
setupIndexes := func(ctx context.Context, mgr ctrl.Manager) {
if err := index.AddDefaultIndexes(ctx, mgr); err != nil {
panic(fmt.Sprintf("unable to setup index: %v", err))
}
// Run tests
...
}
By combining pre-configured validation and mutating webhooks and reconcilers/indexes it is possible
to use envtest for developing Cluster API integration tests that can mimic how the system
behaves in real Cluster.
Please note that, because envtest uses a real kube-apiserver that is shared across many test cases, the developer
should take care in ensuring each test runs in isolation from the others, by:
Creating objects in separated namespaces.
Avoiding object name conflict.
Developers should also be aware of the fact that the informers cache used to access the envtest
depends on actual etcd watches/API calls for updates, and thus it could happen that after creating
or deleting objects the cache takes a few milliseconds to get updated. This can lead to test flakes,
and thus it always recommended to use patterns like create and wait or delete and wait; Cluster API env
test provides a set of utils for this scope.
However, developers should be aware that in some ways, the test control plane will behave differently from “real”
clusters, and that might have an impact on how you write tests.
One common example is garbage collection; because there are no controllers monitoring built-in resources, objects
do not get deleted, even if an OwnerReference is set up; as a consequence, usually test implements code for cleaning up
created objects.
This is an example of a test implementing those recommendations:
func TestAFunc(t *testing.T) {
g := NewWithT(t)
// Generate namespace with a random name starting with ns1; such namespace
// will host test objects in isolation from other tests.
ns1, err := env.CreateNamespace(ctx, "ns1")
g.Expect(err).ToNot(HaveOccurred())
defer func() {
// Cleanup the test namespace
g.Expect(env.DeleteNamespace(ctx, ns1)).To(Succeed())
}()
obj := &clusterv1.Cluster{
ObjectMeta: metav1.ObjectMeta{
Name: "test",
Namespace: ns1.Name, // Place test objects in the test namespace
},
}
// Actual test code...
}
In case of object used in many test case within the same test, it is possible to leverage on Kubernetes GenerateName;
For objects that are shared across sub-tests, ensure they are scoped within the test namespace and deep copied to avoid
cross-test changes that may occur to the object.
func TestAFunc(t *testing.T) {
g := NewWithT(t)
// Generate namespace with a random name starting with ns1; such namespace
// will host test objects in isolation from other tests.
ns1, err := env.CreateNamespace(ctx, "ns1")
g.Expect(err).ToNot(HaveOccurred())
defer func() {
// Cleanup the test namespace
g.Expect(env.DeleteNamespace(ctx, ns1)).To(Succeed())
}()
obj := &clusterv1.Cluster{
ObjectMeta: metav1.ObjectMeta{
GenerateName: "test-", // Instead of assigning a name, use GenerateName
Namespace: ns1.Name, // Place test objects in the test namespace
},
}
t.Run("test case 1", func(t *testing.T) {
g := NewWithT(t)
// Deep copy the object in each test case, so we prevent side effects in case the object changes.
// Additionally, thanks to GenerateName, the objects gets a new name for each test case.
obj := obj.DeepCopy()
// Actual test case code...
}
t.Run("test case 2", func(t *testing.T) {
g := NewWithT(t)
obj := obj.DeepCopy()
// Actual test case code...
}
// More test cases.
}
fakeclient is another utility that is provided by the controller-runtime project. While this utility is really
fast and simple to use because it does not require to spin-up an instance of etcd and kube-apiserver, the fakeclient
comes with a set of limitations that could hamper the validity of a test, most notably:
it does not properly handle a set of fields which are common in the Kubernetes API objects (and Cluster API objects as well)
like e.g. creationTimestamp, resourceVersion, generation, uid
fakeclient operations do not trigger defaulting or validation webhooks, so there are no enforced guarantees about the semantic accuracy
of the test objects.the fakeclient does not use a cache based on informers/API calls/etcd watches, so the test written in this way
can’t help in surfacing race conditions related to how those components behave in real cluster.
there is no support for cache index/operations using cache indexes.
Accordingly, using fakeclient is not suitable for all the use cases, so in some cases contributors will be required
to use envtest instead. In case of doubts about which one to use when writing tests, don’t hesitate to ask for
guidance from project maintainers.
Ginkgo is a Go testing framework built to help you efficiently write expressive and comprehensive tests using Behavior-Driven Development (“BDD”) style.
While Ginkgo is widely used in the Kubernetes ecosystem, Cluster API maintainers found the lack of integration with the
most used golang IDE somehow limiting, mostly because:
it makes interactive debugging of tests more difficult, since you can’t just run the test using the debugger directly
it makes it more difficult to only run a subset of tests, since you can’t just run or debug individual tests using an IDE,
but you now need to run the tests using make or the ginkgo command line and override the focus to select individual tests
In Cluster API you MUST use ginkgo only for E2E tests, where it is required to leverage the support for running specs
in parallel; in any case, developers MUST NOT use the table driven extension DSL (DescribeTable, Entry commands)
which is considered unintuitive.
Gomega is a matcher/assertion library. It is usually paired with the Ginkgo BDD test framework, but it can be used with
other test frameworks too.
More specifically, in order to use Gomega with go test you should
func TestFarmHasCow(t *testing.T) {
g := NewWithT(t)
g.Expect(f.HasCow()).To(BeTrue(), "Farm should have cow")
}
In Cluster API all the test MUST use Gomega assertions.
go test testing provides support for automated testing of Go packages.
In Cluster API Unit and integration test MUST use go test .
E2E tests are meant to verify the proper functioning of a Cluster API management
cluster in an environment that resembles a real production environment.
The following guidelines should be followed when developing E2E tests:
The Cluster API test framework provides you a set of helper methods for getting your test in place
quickly. The test E2E package provides examples of how this can be achieved and reusable
test specs for the most common Cluster API use cases.
Each E2E test requires a set of artifacts to be available:
Binaries & Docker images for Kubernetes, CNI, CRI & CSI
Manifests & Docker images for the Cluster API core components
Manifests & Docker images for the Cluster API infrastructure provider; in most cases
machine images are also required (AMI, OVA etc.)
Credentials for the target infrastructure provider
Other support tools (e.g. kustomize, gsutil etc.)
The Cluster API test framework provides support for building and retrieving the manifest
files for Cluster API core components and for the Cluster API infrastructure provider
(see Setup ).
For the remaining tasks you can find examples of
how this can be implemented e.g. in CAPA E2E tests and CAPG E2E tests .
In order to run E2E tests it is required to create a Kubernetes cluster with a
complete set of Cluster API providers installed. Setting up those elements is
usually implemented in a BeforeSuite function, and it consists of two steps:
Defining an E2E config file
Creating the management cluster and installing providers
The E2E config file provides a convenient and flexible way to define common tasks for
setting up a management cluster.
Using the config file it is possible to:
Define the list of providers to be installed in the management cluster. Most notably,
for each provider it is possible to define:
One or more versions of the providers manifest (built from the sources, or pulled from a
remote location).
A list of additional files to be added to the provider repository, to be used e.g.
to provide cluster-templates.yaml files.
Define the list of variables to be used when doing clusterctl init or
clusterctl generate cluster.
Define a list of intervals to be used in the test specs for defining timeouts for the
wait and Eventually methods.
Define the list of images to be loaded in the management cluster (this is specific to
management clusters based on kind).
An example E2E config file can be found here.
In order to run Cluster API E2E tests, you need a Kubernetes cluster. The NewKindClusterProvider gives you a
type that can be used to create a local kind cluster and pre-load images into it. Existing clusters can
be used if available.
Once you have a Kubernetes cluster, the InitManagementClusterAndWatchControllerLogs method provides a convenient
way for installing providers.
This method:
Runs clusterctl init using the above local repository.
Waits for the providers controllers to be running.
Creates log watchers for all the providers
A typical test spec is a sequence of:
Creating a namespace to host in isolation all the test objects.
Creating objects in the management cluster, wait for the corresponding infrastructure to be provisioned.
Exec operations like e.g. changing the Kubernetes version or clusterctl move, wait for the action to complete.
Delete objects in the management cluster, wait for the corresponding infrastructure to be terminated.
The CreateNamespaceAndWatchEvents method provides a convenient way to create a namespace and setup
watches for capturing namespaces events.
There are two possible approaches for creating objects in the management cluster:
Create object by object: create the Cluster object, then AwsCluster, Machines, AwsMachines etc.
Apply a cluster-templates.yaml file thus creating all the objects this file contains.
The first approach leverages the controller-runtime Client and gives you full control, but it comes with
some drawbacks as well, because this method does not directly reflect real user workflows, and most importantly,
the resulting tests are not as reusable with other infrastructure providers. (See writing portable tests ).
We recommend using the ClusterTemplate method and the Apply method for creating objects in the cluster.
This methods mimics the recommended user workflows, and it is based on cluster-templates.yaml files that can be
provided via the E2E config file , and thus easily swappable when changing the target infrastructure provider.
If you need control over object creation but want to preserve portability, you can create many templates
files each one creating only a small set of objects (instead of using a single template creating a full cluster).
After creating objects in the cluster, use the existing methods in the Cluster API test framework to discover
which object were created in the cluster so your code can adapt to different cluster-templates.yaml files.
Once you have object references, the framework includes methods for waiting for the corresponding
infrastructure to be provisioned, e.g. WaitForClusterToProvision , WaitForKubeadmControlPlaneMachinesToExist .
You can use Cluster API test framework methods to modify Cluster API objects, as a last option, use
the controller-runtime Client .
The Cluster API test framework also includes methods for executing clusterctl operations, like e.g.
the ClusterTemplate method , the ClusterctlMove method etc.. In order to improve observability,
each clusterctl operation creates a detailed log.
After using clusterctl operations, you can rely on the Get and on the Wait methods
defined in the Cluster API test framework to check if the operation completed successfully.
You can categorize the test with a custom label that can be used to filter a category of E2E tests to be run. Currently, the cluster-api codebase has these labels which are used to run a focused subset of tests.
After a test completes/fails, it is required to:
Collect all the logs for the Cluster API controllers
Dump all the relevant Cluster API/Kubernetes objects
Cleanup all the infrastructure resources created during the test
Those tasks are usually implemented in the AfterSuite, and again the Cluster API test framework provides
you useful methods for those tasks.
Please note that despite the fact that test specs are expected to delete objects in the management cluster and
wait for the corresponding infrastructure to be terminated, it can happen that the test spec
fails before starting object deletion or that objects deletion itself fails.
As a consequence, when scheduling/running a test suite, it is required to ensure all the generated
resources are cleaned up. In Kubernetes, this is implemented by the boskos project.
A portable E2E test is a test that can run with different infrastructure providers by simply
changing the test configuration file.
The following recommendations should be followed to write portable E2E tests:
As of today there is no a well-defined suite of E2E tests that can be used as a
baseline for Cluster API conformance.
However, creating such a suite is something that can provide a huge value for the
long term success of the project.
The test E2E package provides examples of how this can be achieved by implementing a set of reusable
test specs for the most common Cluster API use cases.
Cluster API has a number of controllers, both in the core Cluster API and the reference providers, which move the state of the cluster toward some defined desired state through the process of controller reconciliation .
Documentation for the CAPI controllers can be found at:
Bootstrap Provider
ControlPlane Provider
Core
ClusterClass
AddOns
Bootstrapping is the process in which:
A cluster is bootstrapped
A machine is bootstrapped and takes on a role within a cluster
CABPK is the reference bootstrap provider and is based on kubeadm. CABPK codifies the steps for creating a cluster in multiple configurations.
See proposal for the full details on how the bootstrap process works.
The Cluster controller’s main responsibilities are:
Setting an OwnerReference on the infrastructure object referenced in Cluster.spec.infrastructureRef.
Setting an OwnerReference on the control plane object referenced in Cluster.spec.controlPlaneRef.
Cleanup of all owned objects so that nothing is dangling after deletion.
Keeping the Cluster’s status in sync with the infrastructureCluster’s status.
Creating a kubeconfig secret for workload clusters .
The general expectation of an infrastructure provider is to provision the necessary infrastructure components needed to
run a Kubernetes cluster. As an example, the AWS infrastructure provider, specifically the AWSCluster reconciler, will
provision a VPC, some security groups, an ELB, a bastion instance and some other components all with AWS best practices
baked in. Once that infrastructure is provisioned and ready to be used the AWSMachine reconciler takes over and
provisions EC2 instances that will become a Kubernetes cluster through some bootstrap mechanism.
The cluster controller will set an OwnerReference on the infrastructureCluster. This controller should normally take no action during reconciliation until it sees the OwnerReference.
An infrastructureCluster controller is expected to either supply a controlPlaneEndpoint (via its own spec.controlPlaneEndpoint field),
or rely on spec.controlPlaneEndpoint in its parent Cluster object.
If an endpoint is not provided, the implementer should exit reconciliation until it sees cluster.spec.controlPlaneEndpoint populated.
The Cluster controller bubbles up spec.controlPlaneEndpoint and status.ready into status.infrastructureReady from the infrastructureCluster.
The InfrastructureCluster object must have a status object.
The spec object must have the following fields defined:
controlPlaneEndpoint - identifies the endpoint used to connect to the target’s cluster apiserver.
The status object must have the following fields defined:
ready - a boolean field that is true when the infrastructure is ready to be used.
The status object may define several fields that do not affect functionality if missing:
failureReason - is a string that explains why a fatal error has occurred, if possible.failureMessage - is a string that holds the message contained by the error.failureDomains - is a FailureDomains type indicating the failure domains that machines should be placed in. FailureDomains
is a map, defined as map[string]FailureDomainSpec. A unique key must be used for each FailureDomainSpec.
FailureDomainSpec is defined as:
controlPlane (bool): indicates if failure domain is appropriate for running control plane instances.attributes (map[string]string): arbitrary attributes for users to apply to a failure domain.
Note: once any of failureReason or failureMessage surface on the cluster who is referencing the infrastructureCluster object,
they cannot be restored anymore (it is considered a terminal error; the only way to recover is to delete and recreate the cluster).
Example:
kind: MyProviderCluster
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
spec:
controlPlaneEndpoint:
host: example.com
port: 6443
status:
ready: true
If you are using the kubeadm bootstrap provider you do not have to provide any Cluster API secrets. It will generate
all necessary CAs (certificate authorities) for you.
However, if you provide a CA for the cluster then Cluster API will be able to generate a kubeconfig secret.
This is useful if you have a custom CA or do not want to use the bootstrap provider’s generated self-signed CA.
Secret name Field name Content
<cluster-name>-catls.crtbase64 encoded TLS certificate in PEM format <cluster-name>-catls.keybase64 encoded TLS private key in PEM format
Alternatively can entirely bypass Cluster API generating a kubeconfig entirely if you provide a kubeconfig secret
formatted as described below.
Secret name Field name Content
<cluster-name>-kubeconfigvaluebase64 encoded kubeconfig
The Machine controller’s main responsibilities are:
Setting an OwnerReference on:
Each Machine object to the Cluster object.
The associated BootstrapConfig object.
The associated InfrastructureMachine object.
Copy data from BootstrapConfig.Status.DataSecretName to Machine.Spec.Bootstrap.DataSecretName if
Machine.Spec.Bootstrap.DataSecretName is empty.
Setting NodeRefs to be able to associate machines and Kubernetes nodes.
Deleting Nodes in the target cluster when the associated machine is deleted.
Cleanup of related objects.
Keeping the Machine’s Status object up to date with the InfrastructureMachine’s Status object.
Finding Kubernetes nodes matching the expected providerID in the workload cluster.
After the machine controller sets the OwnerReferences on the associated objects, it waits for the bootstrap
and infrastructure objects referenced by the machine to have the Status.Ready field set to true. When
the infrastructure object is ready, the machine controller will attempt to read its Spec.ProviderID and
copy it into Machine.Spec.ProviderID.
The machine controller uses the kubeconfig for the new workload cluster to watch new nodes coming up.
When a node appears with Node.Spec.ProviderID matching Machine.Spec.ProviderID, the machine controller
transitions the associated machine into the Provisioned state. When the infrastructure ref is also
Ready, the machine controller marks the machine as Running.
Cluster associations are made via labels.
what label value meaning
Machine cluster.x-k8s.io/cluster-name<cluster-name>Identify a machine as belonging to a cluster with the name <cluster-name> Machine cluster.x-k8s.io/control-planetrueIdentifies a machine as a control-plane node
The BootstrapConfig object must have a status object.
To override the bootstrap provider, a user (or external system) can directly set the Machine.Spec.Bootstrap.Data
field. This will mark the machine as ready for bootstrapping and no bootstrap data will be copied from the
BootstrapConfig object.
The status object must have several fields defined:
ready - a boolean field indicating the bootstrap config data is generated and ready for use.dataSecretName - a string field referencing the name of the secret that stores the generated bootstrap data.
The status object may define several fields that do not affect functionality if missing:
failureReason - a string field explaining why a fatal error has occurred, if possible.failureMessage - a string field that holds the message contained by the error.
Example:
kind: MyBootstrapProviderConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
status:
ready: true
dataSecretName: "MyBootstrapSecret"
The InfrastructureMachine object must have both spec and status objects.
The spec object must at least one field defined:
providerID - a cloud provider ID identifying the machine.
The spec object may define several fields that do not affect functionality if missing:
failureDomain - is a string identifying the failure domain the instance is running in.
The status object must at least one field defined:
ready - a boolean field indicating if the infrastructure is ready to be used or not.
The status object may define several fields that do not affect functionality if missing:
failureReason - is a string that explains why a fatal error has occurred, if possible.failureMessage - is a string that holds the message contained by the error.addresses - is a MachineAddresses (a list of MachineAddress) which represents host names, external IP addresses, internal IP addresses,
external DNS names, and/or internal DNS names for the provider’s machine instance. MachineAddress is
defined as:
type (string): one of Hostname, ExternalIP, InternalIP, ExternalDNS, InternalDNSaddress (string)
Example:
kind: MyMachine
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
spec:
providerID: cloud:////my-cloud-provider-id
status:
ready: true
The Machine controller will create a secret or use an existing secret in the following format:
secret name field name content
<cluster-name>-kubeconfigvaluebase64 encoded kubeconfig that is authenticated with the child cluster
A MachineSet is an abstraction over Machines .
Its main responsibilities are:
Adopting unowned Machines that aren’t assigned to a MachineSet
Adopting unmanaged Machines that aren’t assigned a Cluster
Booting a group of N machines
Monitoring the status of those booted machines
Changes to the following fields of MachineSet are propagated in-place to the Machine without needing a full rollout:
.spec.template.metadata.labels.spec.template.metadata.annotations.spec.template.spec.nodeDrainTimeout.spec.template.spec.nodeDeletionTimeout.spec.template.spec.nodeVolumeDetachTimeout
Changes to the following fields of MachineSet are propagated in-place to the InfrastructureMachine and BootstrapConfig:
.spec.template.metadata.labels.spec.template.metadata.annotations
Note: Changes to these fields will not be propagated to Machines that are marked for deletion (example: because of scale down).
A MachineDeployment orchestrates deployments over a fleet of MachineSets .
Its main responsibilities are:
Adopting matching MachineSets not assigned to a MachineDeployment
Adopting matching MachineSets not assigned to a Cluster
Managing the Machine deployment process
Scaling up new MachineSets when changes are made
Scaling down old MachineSets when newer MachineSets replace them
Updating the status of MachineDeployment objects
Changes to the following fields of the MachineDeployment are propagated in-place to the MachineSet and do not trigger a full rollout:
.annotations.spec.template.metadata.labels.spec.template.metadata.annotations.spec.minReadySeconds.spec.template.spec.nodeDrainTimeout.spec.template.spec.nodeDeletionTimeout.spec.template.spec.nodeVolumeDetachTimeout.spec.strategy.rollingUpdate.deletePolicy
Note: In cases where changes to any of these fields are paired with rollout causing changes, the new values are propagated only to the new MachineSet.
A MachineHealthCheck is responsible for remediating unhealthy Machines .
Its main responsibilities are:
Checking the health of Nodes in the workload clusters against a list of unhealthy conditions
Remediating Machine’s for Nodes determined to be unhealthy
The Control Plane controller’s main responsibilities are:
Managing a set of machines that represent a Kubernetes control plane.
Provide information about the state of the control plane to downstream
consumers.
Create/manage a secret with the kubeconfig file for accessing the workload cluster.
A reference implementation is managed within the core Cluster API project as the
Kubeadm control plane controller (KubeadmControlPlane). In this document,
we refer to an example ImplementationControlPlane where not otherwise specified.
The general expectation of a control plane controller is to instantiate a
Kubernetes control plane consisting of the following services:
etcd
Kubernetes API Server
Kubernetes Controller Manager
Kubernetes Scheduler
Cloud controller manager
Cluster DNS (e.g. CoreDNS)
Service proxy (e.g. kube-proxy)
CNI - should be left to user to apply once control plane is instantiated.
The Cluster controller will set an OwnerReference on the Control Plane. The Control Plane controller should normally take no action during reconciliation until it sees the ownerReference.
A Control Plane controller implementation must either supply a controlPlaneEndpoint (via its own spec.controlPlaneEndpoint field),
or rely on spec.controlPlaneEndpoint in its parent Cluster object.
If an endpoint is not provided, the implementer should exit reconciliation until it sees cluster.spec.controlPlaneEndpoint populated.
A Control Plane controller can optionally provide a controlPlaneEndpoint
The Cluster controller bubbles up status.ready into status.controlPlaneReady and status.initialized into a controlPlaneInitialized condition from the Control Plane CR.
The CRD name must have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
The same applies for the name of the corresponding ControlPlane template CRD.
replicas - is an integer representing the number of desired
replicas. In the KubeadmControlPlane, this represents the desired
number of control plane machines.
scale subresource with the following signature:
scale:
labelSelectorPath: .status.selector
specReplicasPath: .spec.replicas
statusReplicasPath: .status.replicas
status: {}
More information about the scale subresource can be found in the Kubernetes
documentation .
version - is a string representing the Kubernetes version to be used
by the control plane machines. The value must be a valid semantic version;
also if the value provided by the user does not start with the v prefix, it
must be added.
machineTemplate - is a struct containing details of the control plane
machine template.
machineTemplate.metadata - is a struct containing info about metadata for control plane
machines.
machineTemplate.metadata.labels - is a map of string keys and values that can be used
to organize and categorize control plane machines.
machineTemplate.metadata.annotations - is a map of string keys and values containing
arbitrary metadata to be applied to control plane machines.
machineTemplate.infrastructureRef - is a corev1.ObjectReference to a custom resource
offered by an infrastructure provider. The namespace in the ObjectReference must
be in the same namespace of the control plane object.
machineTemplate.nodeDrainTimeout - is a *metav1.Duration defining the total amount of time
that the controller will spend on draining a control plane node.
The default value is 0, meaning that the node can be drained without any time limitations.
machineTemplate.nodeVolumeDetachTimeout - is a *metav1.Duration defining how long the controller
will spend on waiting for all volumes to be detached.
The default value is 0, meaning that the volume can be detached without any time limitations.
machineTemplate.nodeDeletionTimeout - is a *metav1.Duration defining how long the controller
will attempt to delete the Node that is hosted by a Machine after the Machine is marked for
deletion. A duration of 0 will retry deletion indefinitely. It defaults to 10 seconds on the
Machine.
The ImplementationControlPlane object may provide a spec.controlPlaneEndpoint field to inform the Cluster
controller where the endpoint is located.
Implementers might opt to choose the APIEndpoint struct exposed by Cluster API types, or the following:
Field
Type
Description
hostString
The hostname on which the API server is serving.
portInteger
The port on which the API server is serving.
The ImplementationControlPlane object must have a status object.
The status object must have the following fields defined:
Field
Type
Description
Implementation in Kubeadm Control Plane Controller
initializedBoolean
a boolean field that is true when the target cluster has
completed initialization such that at least once, the
target's control plane has been contactable.
Transitions to initialized when the controller detects that kubeadm has uploaded
a kubeadm-config configmap, which occurs at the end of kubeadm provisioning.
readyBoolean
Ready denotes that the target API Server is ready to receive requests.
Where the ImplementationControlPlane has a concept of replicas, e.g. most
high availability control planes, then the status object must have the
following fields defined:
Field
Type
Description
Implementation in Kubeadm Control Plane Controller
readyReplicasInteger
Total number of fully running and ready control plane instances.
Is equal to the number of fully running and ready control plane machines
replicasInteger
Total number of non-terminated control plane instances,
i.e. the state machine for this instance
of the control plane is able to transition to ready.
Is equal to the number of non-terminated control plane machines
selectorString
`selector` is the label selector in string format to avoid
introspection by clients, and is used to provide the CRD-based integration
for the scale subresource and additional integrations for things like
kubectl describe. The string will be in the same format as the query-param
syntax. More info about label selectors: https://kubernetes.io/docs/concepts/overview/working-with-objects/labels/#label-selectors
unavailableReplicasInteger
Total number of unavailable control plane instances targeted by this control plane, equal
to the desired number of control plane instances - ready instances.
Total number of unavailable machines targeted by this control
plane. This is the total number of machines that are still required
for the deployment to have 100% available capacity. They may either
be machines that are running but not yet ready or machines that still
have not been created.
updatedReplicas
integer
Total number of non-terminated machines targeted by this
control plane that have the desired template spec.
Total number of non-terminated machines targeted by this
control plane that have the desired template spec.
version - is a string representing the minimum Kubernetes version for the
control plane machines in the cluster.
NOTE: The minimum Kubernetes version, and more specifically the API server
version, will be used to determine when a control plane is fully upgraded
(spec.version == status.version) and for enforcing Kubernetes version
skew policies in managed topologies.
The status object may define several fields:
failureReason - is a string that explains why an error has occurred, if possible.failureMessage - is a string that holds the message contained by the error.externalManagedControlPlane - is a bool that should be set to true if the Node objects do not
exist in the cluster. For example, managed control plane providers for AKS, EKS, GKE, etc, should
set this to true. Leaving the field undefined is equivalent to setting the value to false.
apiVersion: controlplane.cluster.x-k8s.io/v1beta1
kind: KubeadmControlPlane
metadata:
name: kcp-1
namespace: default
spec:
machineTemplate:
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
kind: DockerMachineTemplate
name: docker-machine-template-1
namespace: default
replicas: 3
version: v1.21.2
Control Plane providers are expected to create and maintain a Kubeconfig
secret for operators to gain initial access to the cluster.
The given secret must be labelled with the key-pair cluster.x-k8s.io/cluster-name=${CLUSTER_NAME}
to make it stored and retrievable in the cache used by CAPI managers. If a provider uses
client certificates for authentication in these Kubeconfigs, the client
certificate should be kept with a reasonably short expiration period and
periodically regenerated to keep a valid set of credentials available. As an
example, the Kubeadm Control Plane provider uses a year of validity and
refreshes the certificate after 6 months.
The MachinePool controller’s main responsibilities are:
Setting an OwnerReference on each MachinePool object to:
The associated Cluster object.
The associated BootstrapConfig object.
The associated InfrastructureMachinePool object.
Copy data from BootstrapConfig.Status.DataSecretName to MachinePool.Spec.Template.Spec.Bootstrap.DataSecretName if
MachinePool.Spec.Template.Spec.Bootstrap.DataSecretName is empty.
Setting NodeRefs on MachinePool instances to be able to associate them with Kubernetes nodes.
Deleting Nodes in the target cluster when the associated MachinePool instance is deleted.
Keeping the MachinePool’s Status object up to date with the InfrastructureMachinePool’s Status object.
Finding Kubernetes nodes matching the expected providerIDs in the workload cluster.
After the machine pool controller sets the OwnerReferences on the associated objects, it waits for the bootstrap
and infrastructure objects referenced by the machine to have the Status.Ready field set to true. When
the infrastructure object is ready, the machine pool controller will attempt to read its Spec.ProviderIDList and
copy it into MachinePool.Spec.ProviderIDList.
The machine pool controller uses the kubeconfig for the new workload cluster to watch new nodes coming up.
When a node appears with a Node.Spec.ProviderID in MachinePool.Spec.ProviderIDList, the machine pool controller
increments the number of ready replicas. When all replicas are ready and the infrastructure ref is also
Ready, the machine pool controller marks the machine pool as Running.
Cluster associations are made via labels.
what label value meaning
MachinePool cluster.x-k8s.io/cluster-name<cluster-name>Identify a machine pool as belonging to a cluster with the name <cluster-name>
The BootstrapConfig object must have a status object.
The CRD name must have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
To override the bootstrap provider, a user (or external system) can directly set the MachinePool.Spec.Bootstrap.DataSecretName
field. This will mark the machine as ready for bootstrapping and no bootstrap data secret name will be copied from the
BootstrapConfig object.
The status object must have several fields defined:
ready - a boolean field indicating the bootstrap config data is generated and ready for use.dataSecretName - a string field referencing the name of the secret that stores the generated bootstrap data.
The status object may define several fields that do not affect functionality if missing:
failureReason - a string field explaining why a fatal error has occurred, if possible.failureMessage - a string field that holds the message contained by the error.
Example:
kind: MyBootstrapProviderConfig
apiVersion: bootstrap.cluster.x-k8s.io/v1alpha3
status:
ready: true
dataSecretName: "MyBootstrapSecret"
The InfrastructureMachinePool object must have both spec and status objects.
The CRD name must have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
The spec object must have at least one field defined:
providerIDList - the list of cloud provider IDs identifying the instances.
The status object must have at least one field defined:
ready - a boolean field indicating if the infrastructure is ready to be used or not.
The status object may define several fields that do not affect functionality if missing:
failureReason - is a string that explains why a fatal error has occurred, if possible.failureMessage - is a string that holds the message contained by the error.infrastructureMachineKind - the kind of the InfraMachines. This should be set if the InfrastructureMachinePool plans to support MachinePool Machines.
Note: Infrastructure providers can support MachinePool Machines by having the InfraMachinePool set the infrastructureMachineKind to the kind of their InfrastructureMachines. The InfrastructureMachinePool will be responsible for creating InfrastructureMachines as the MachinePool is scaled up, and the MachinePool controller will create Machines for each InfrastructureMachine and set the ownerRef. The InfrastructureMachinePool will be responsible for deleting the Machines as the MachinePool is scaled down in order for the Machine deletion workflow to function properly. In addition, the InfrastructureMachines must also have the following labels set by the InfrastructureMachinePool: cluster.x-k8s.io/cluster-name and cluster.x-k8s.io/pool-name. The MachinePoolNameLabel must also be formatted with capilabels.MustFormatValue() so that it will not exceed character limits.
Example
kind: MyMachinePool
apiVersion: infrastructure.cluster.x-k8s.io/v1beta1
spec:
providerIDList:
- cloud:////my-cloud-provider-id-0
- cloud:////my-cloud-provider-id-1
status:
ready: true
infrastructureMachineKind: InfrastructureMachine
A provider may implement an InfrastructureMachinePool that is externally managed by an autoscaler. For example, if you are using a Managed Kubernetes provider, it may include its own autoscaler solution. To indicate this to Cluster API, you would decorate the MachinePool object with the following annotation:
"cluster.x-k8s.io/replicas-managed-by": ""
Cluster API treats the annotation as a “boolean”, meaning that the presence of the annotation is sufficient to indicate external replica count management, with one exception: if the value is "false", then that indicates to Cluster API that replica enforcement is nominal, and managed by Cluster API.
Providers may choose to implement the cluster.x-k8s.io/replicas-managed-by annotation with different values (e.g., external-autoscaler, or karpenter) that may inform different provider-specific behaviors, but those values will have no effect upon Cluster API.
The effect upon Cluster API of this annotation is that during autoscaling events (initiated externally, not by Cluster API), when more or fewer MachinePool replicas are observed compared to the Spec.Replicas configuration, it will update its Status.Phase property to the value of "Scaling".
Example:
kind: MyMachinePool
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha3
spec:
providerIDList:
- cloud:////my-cloud-provider-id-0
- cloud:////my-cloud-provider-id-1
- cloud:////my-cloud-provider-id-2
replicas: 1
status:
ready: true
phase: Scaling
infrastructureMachineKind: InfrastructureMachine
It is the provider’s responsibility to update Cluster API’s Spec.Replicas property to the value observed in the underlying infra environment as it changes in response to external autoscaling behaviors. Once that is done, and the number of providerID items is equal to the Spec.Replicas property, the MachinePools’s Status.Phase property will be set to Running by Cluster API.
The machine pool controller will use a secret in the following format:
secret name field name content
<cluster-name>-kubeconfigvaluebase64 encoded kubeconfig that is authenticated with the workload cluster
The ClusterTopology controller reconciles the managed topology of a Cluster, as
shown in the following diagram.
Its main responsibilities are to:
Reconcile Clusters based on templates defined in a ClusterClass and managed topology.
Create, update, delete managed topologies by continuously reconciling the topology managed resources.
Reconcile Cluster-specific customizations of a ClusterClass
The high level workflow of ClusterTopology reconciliation is shown below.
The ClusterResourceSet provides a mechanism for applying resources - e.g. pods, deployments, daemonsets, secrets, configMaps - to a cluster once it is created.
Its main responsibility is to automatically apply a set of resources to newly-created and existing Clusters. Resources will be applied only once.
Cluster API controllers implement consistent metadata (labels & annotations) propagation across the core API resources.
This behaviour tries to be consistent with Kubernetes apps/v1 Deployment and ReplicaSet.
New providers should behave accordingly fitting within the following pattern:
ControlPlaneTopology labels are labels and annotations are continuously propagated to ControlPlane top-level labels and annotations
and ControlPlane MachineTemplate labels and annotations.
.spec.topology.controlPlane.metadata.labels => ControlPlane.labels, ControlPlane.spec.machineTemplate.metadata.labels.spec.topology.controlPlane.metadata.annotations => ControlPlane.annotations, ControlPlane.spec.machineTemplate.metadata.annotations
MachineDeploymentTopology labels and annotations are continuously propagated to MachineDeployment top-level labels and annotations
and MachineDeployment MachineTemplate labels and annotations.
.spec.topology.machineDeployments[i].metadata.labels => MachineDeployment.labels, MachineDeployment.spec.template.metadata.labels.spec.topology.machineDeployments[i].metadata.annotations => MachineDeployment.annotations, MachineDeployment.spec.template.metadata.annotations
ControlPlaneClass labels are labels and annotations are continuously propagated to ControlPlane top-level labels and annotations
and ControlPlane MachineTemplate labels and annotations.
.spec.controlPlane.metadata.labels => ControlPlane.labels, ControlPlane.spec.machineTemplate.metadata.labels.spec.controlPlane.metadata.annotations => ControlPlane.annotations, ControlPlane.spec.machineTemplate.metadata.annotations
Note: ControlPlaneTopology labels and annotations take precedence over ControlPlaneClass labels and annotations.
MachineDeploymentClass labels and annotations are continuously propagated to MachineDeployment top-level labels and annotations
and MachineDeployment MachineTemplate labels and annotations.
.spec.workers.machineDeployments[i].template.metadata.labels => MachineDeployment.labels, MachineDeployment.spec.template.metadata.labels.spec.worker.machineDeployments[i].template.metadata.annotations => MachineDeployment.annotations, MachineDeployment.spec.template.metadata.annotations
Note: MachineDeploymentTopology labels and annotations take precedence over MachineDeploymentClass labels and annotations.
Top-level labels and annotations do not propagate at all.
.labels => Not propagated..annotations => Not propagated.
MachineTemplate labels and annotations continuously propagate to new and existing Machines, InfraMachines and BootstrapConfigs.
.spec.machineTemplate.metadata.labels => Machine.labels, InfraMachine.labels, BootstrapConfig.labels.spec.machineTemplate.metadata.annotations => Machine.annotations, InfraMachine.annotations, BootstrapConfig.annotations
Top-level labels do not propagate at all.
Top-level annotations continuously propagate to MachineSets top-level annotations.
.labels => Not propagated..annotations => MachineSet.annotations
Template labels continuously propagate to MachineSets top-level and MachineSets template metadata.
Template annotations continuously propagate to MachineSets template metadata.
.spec.template.metadata.labels => MachineSet.labels, MachineSet.spec.template.metadata.labels.spec.template.metadata.annotations => MachineSet.spec.template.metadata.annotations
Top-level labels and annotations do not propagate at all.
.labels => Not propagated..annotations => Not propagated.
Template labels and annotations continuously propagate to new and existing Machines, InfraMachines and BootstrapConfigs.
.spec.template.metadata.labels => Machine.labels, InfraMachine.labels, BootstrapConfig.labels.spec.template.metadata.annotations => Machine.annotations, InfraMachine.annotations, BootstrapConfig.annotations
Top-level labels that meet a specific cretria are propagated to the Node labels and top-level annotatation are not propagated.
.labels.[label-meets-criteria] => Node.labels.annotations => Not propagated.
Label should meet one of the following criterias to propagate to Node:
Has node-role.kubernetes.io as prefix.
Belongs to node-restriction.kubernetes.io domain.
Belongs to node.cluster.x-k8s.io domain.
Multi tenancy in Cluster API defines the capability of an infrastructure provider to manage different credentials, each
one of them corresponding to an infrastructure tenant.
In order to support multi tenancy, the following rule applies:
Infrastructure providers MUST be able to manage different sets of credentials (if any)
Providers SHOULD deploy and run any kind of webhook (validation, admission, conversion)
following Cluster API codebase best practices for the same release.
Providers MUST create and publish a {type}-component.yaml accordingly.
Up until v1alpha3, the need of supporting multiple credentials was addressed by running multiple
instances of the same provider, each one with its own set of credentials while watching different namespaces.
However, running multiple instances of the same provider proved to be complicated for several reasons:
Complexity in packaging providers: CustomResourceDefinitions (CRD) are global resources, these may have a reference
to a service that can be used to convert between CRD versions (conversion webhooks). Only one of these services should
be running at any given time, this requirement led us to previously split the webhooks code to a different deployment
and namespace.
Complexity in deploying providers, due to the requirement to ensure consistency of the management cluster, e.g.
controllers watching the same namespaces.
The introduction of the concept of management groups in clusterctl, with impacts on the user experience/documentation.
Complexity in managing co-existence of different versions of the same provider while there could be only
one version of CRDs and webhooks. Please note that this constraint generates a risk, because some version of the provider
de-facto were forced to run with CRDs and webhooks deployed from a different version.
Nevertheless, we want to make it possible for users to choose to deploy multiple instances of the same providers,
in case the above limitations/extra complexity are acceptable for them.
In order to make it possible for users to deploy multiple instances of the same provider:
Providers MUST support the --namespace flag in their controllers.
Providers MUST support the --watch-filter flag in their controllers.
⚠️ Users selecting this deployment model, please be aware:
Support should be considered best-effort.
Cluster API (incl. every provider managed under kubernetes-sigs) won’t release a specialized components file
supporting the scenario described above; however, users should be able to create such deployment model from
the /config folder.
Cluster API (incl. every provider managed under kubernetes-sigs) testing infrastructure won’t run test cases
with multiple instances of the same provider.
In conclusion, giving the increasingly complex task that is to manage multiple instances of the same controllers,
the Cluster API community may only provide best effort support for users that choose this model.
As always, if some members of the community would like to take on the responsibility of managing this model,
please reach out through the usual communication channels, we’ll make sure to guide you in the right path.
When tuning controllers, both for scalability, performance or for reducing their footprint, following suggestions can make your work simpler and much more effective.
You need the right tools for the job: without logs, metrics, traces and profiles tuning is hardly possible. Also, given that tuning is an iterative work, having a setup that allows you to experiment and improve quickly could be a huge boost in your work.
Only optimize if there is clear evidence of an issue. This evidence is key for you to measure success and it can provide the necessary context for developing, validating, reviewing and approving the fix. On the contrary, optimizing without evidence can be not worth the effort or even make things worse.
Cluster API provides a full stack of tools for tuning its own controllers as well as controllers for all providers if developed using controller runtime. As a bonus, most of this tooling can be used with any other controller runtime based controllers.
With tilt, you can easily deploy a full observability stack with Grafana, Loki, promtail, Prometheus, kube-state-metrics, Parca and Tempo.
All tools are preconfigured, and most notably kube-state-metrics already collects CAPI metrics and Grafana is configured with a set of dashboards that we used in previous rounds of CAPI tuning. Overall, the CAPI dev environment offers a considerable amount of expertise, free to use and to improve for the entire community. We highly recommend to invest time in looking into those tools, learn and provide feedback.
Additionally, Cluster API includes both CAPD (Cluster API provider for Docker) and CAPIM (Cluster API provider in-memory). Both allow you to quickly create development clusters with the limited resources available on a developer workstation, however:
CAPD gives you a fully functional cluster running in containers; scalability and performance are limited by the size of your machine.
CAPIM gives you a fake cluster running in memory; you can scale more easily but the clusters do not support any Kubernetes feature other than what is strictly required for CAPI, CABPK and KCP to work.
Maintainers are continuously working on improving Cluster API developer environment and tooling; any help is more than welcome and with the community contribution we can make this happen sooner!
With regards to this document, following areas could benefit from community help:
Controller runtime currently has a limited set of metrics for client-go, making it more complex to observe phenomenon like client-go rate limiting; we should start a discussion with the controller runtime-team about how to get those metrics, even if only temporarily during bottleneck investigation.
Cluster API metrics still exists only as a dev tool, and work is required to automate metrics config generation and/or to improve consumption from kube-state-metrics; when this work will be completed it will be much more easier for other providers/other controllers to implement metrics and for user to get access to them. See #7158 .
Tracing in Cluster API is not yet implemented; this will make much more easier to investigate slowness in reconcile loops as well as provide a visual and intuitive representation of Cluster API reconcile loops. See #3760 .
Please reach out to maintainers if you are interested in helping us to make progress in this area.
Tuning controllers and finding performance bottlenecks can vary depending on the issues you are dealing with, so please consider following guidelines as collection of suggestions, not as a strict process to follow.
Before looking at data, it usually helps to have a clear understanding of:
What are the requirements and constraints of the use case you are looking at, e.g.:
Use a management cluster with X cpu, Y memory
Create X cluster, with concurrency Y
Each cluster must have X CP nodes, Y workers
What does it mean for you if the system is working well, e.g.:
All machines should be provisioned in less than X minutes
All controllers should reconcile in less than Y ms
All controllers should allocate less than Z Gb memory
Once you know the scenario you are looking at and what you are tuning for, you can finally look at data, but given that the amount of data available could be overwhelming, you probably need a strategy to navigate all the available metrics, traces, etc. .
Among the many possible strategies, one usually very effective is to look at the KPIs you are aiming for, and then, if the current system performance is not good enough, start looking at other metrics trying to identify the biggest factor that is impacting the results. Usually by removing a single, performance bottleneck the behaviour of the system changes in a significant way; after that you can decide if the performance is now good enough or you need another round of tuning.
Let’s try to make this more clear by using an example, machine provisioning time is degrading when running CAPI at scale (machine provisioning time can be seen in the Cluster API Performance dashboard ).
When running at scale, one of the first things to take care of is the client-go rate limiting, which is a mechanism built inside client-go that prevents a Kubernetes client from being accidentally too aggressive to the API server.
However this mechanism can also limit the performance of a controller when it actually requires to make many calls to the API server.
So one of the first data point to look at is the rate limiting metrics; given that upstream CR doesn’t have metric for that we can only look for logs containing “client-side throttling” via Loki (Note: this link should be open while tilt is running).
If rate limiting is not your issue, then you can look at the controller’s work queue. In an healthy system reconcile events are continuously queued, processed and removed from the queue. If the system is slowing down at scale, it could be that some controllers are struggling to keep up with the events being added in the queue, thus leading to slowness in reconciling the desired state.
So then the next step after looking at rate limiting metrics, is to look at the “work queue depth” panel in the Controller-Runtime dashboard .
Assuming that one controller is struggling with its own work queue, the next step is to look at why this is happening. It might be that the average duration of each reconcile is high for some reason. This can be checked in the “Reconcile Duration by Controller” panel in the Controller-Runtime dashboard .
If this is the case, then it is time to start looking at traces, looking for the longer spans in average (or total). Unfortunately traces are not yet implemented in Cluster API, so alternative approaches must be used, like looking at condition transitions or at logs to figure out what the slowest operations are.
And so on.
Please note that there are also cases where CAPI controllers are just idle waiting for something else to happen on the infrastructure side. In this case investigating bottlenecks requires access to a different set of metrics. Similar considerations apply if the issue is slowness of the API server or of the network.
Cluster API offers a set of options that can be set on the controller deployment at runtime, without the need of changing the CAPI code.
Client-go rate limiting; by increasing the client-go rate limits we allow a controller to make more API server calls per second (--kube-api-qps) or to have a bigger burst to handle spikes (--kube-api-burst). Please note that these settings must be increased carefully, because being too aggressive on the API server might lead to different kind of problems.
Controller concurrency (e.g. via --kubeadmcontrolplane-concurrency); by increasing the number of concurrent reconcile loops for each controller it is possible to help the system in keeping the work queue clean, and thus reconciling to the desired state faster. Also in this case, trade-offs should be considered, because by increasing concurrency not only the controller footprint is going to increase, but also the number of API server calls is likely going to increase (see previous point).
Resync period (--sync-period); this setting defines the interval after which reconcile events for all current objects will be triggered. Historically this value in Cluster API is much lower than the default in controller runtime (10m vs. 10h). This has some advantages, because e.g. it is a fallback in case controller struggle to pick up events from external infrastructure. But it also has impact at scale when a controller gets a sudden spike of events at every resync period. This can be mitigated by increasing the resync period.
As a general rule, you should tune those parameters only if you have evidence supported by data that you are hitting a bottleneck of the system. Similarly, another sample of data should be analyzed after tuning the parameter to check the effects of the change.
Performance is usually a moving target, because things can change due the evolution of the use cases, of the user needs, of the codebase and of all the dependencies Cluster API relies on, starting from Kubernetes and the infrastructure we are using.
That means that no matter of the huge effort that has been put into making CAPI performant, more work will be required to preserve the current state or to improve performance.
Also in this case, most of the considerations really depend on the issue your are dealing with, but some suggestions are worth to be considered for the majority of the use cases.
The best optimization that can be done is to avoid any work at all for controllers. E.g instead of re-queuing every few seconds when a controller is waiting for something to happen, which leads to the controller to do some work to check if something changed in the system, it is always better to watch for events, so the controller is going to do the work only once when it is actually required. When implementing watches, non-relevant changes should be filtered out whenever possible.
Same considerations apply also for the actual reconcile implementation, if you can avoid API server calls or expensive computations under certain conditions, it is always better and faster than any optimization you can do to that code.
However, when work from the controllers is required, it is necessary to make sure that expensive operations are limited as much as possible.
A common example for an expensive operation is the generation of private keys for certificates, or the creation of a Kubernetes client, but the most frequent expensive operations that each controller does are API server calls.
Luckily controller runtime does a great job in helping to address this by providing a delegating client per default that reads from a cache that is maintained by client-go shared informers. This is a huge boost of performance (microseconds vs. seconds) that everyone gets at the cost of some memory allocation and the need of considering stale reads when writing code.
As a rule of thumbs it is always better to deal with stale reads/memory consumption than disabling caching. Even if stale reads could be a concern under certain circumstances, e.g when reading an object right after it has been created.
Also, please be aware that some API server read operations are not cached by default, e.g. reads for unstructured objects, but you can enable caching for those operations when creating the controller runtime client.
But at some point some API server calls must be done, either uncached reads or write operations.
When looking at unchached reads, some operation are more expensive than others, e.g. a list call with a label selector degrades according to the number of object in the same namespace and the number of the items in the result set.
Whenever possible, you should avoid uncached list calls, or make sure they happen only once in a reconcile loop and possibly only under specific circumstances.
When looking at write operations, you can rely on some best practices developed in CAPI. Like for example use a defer call to patch the object with the patch helper to make a single write at the end of the reconcile loop (and only if there are actual changes).
In order to complete this overview, there is another category of operations that can slow down CAPI controllers, which are network calls to other services like e.g. the infrastructure provider.
Some general recommendations apply also in those cases, like e.g re-using long lived clients instead of continuously re-creating new ones, leverage on async callback and watches whenever possible vs. continuously checking for status, etc. .
The following pages provide an overview of relevant changes between versions of Cluster API and their direct successors. These guides are intended to assist
maintainers of other providers and consumers of the Go API in upgrading from one version of Cluster API to a subsequent version.
The Go version used by Cluster API is now Go 1.16+
In case cloudbuild is used to push images, please upgrade to gcr.io/k8s-staging-test-infra/gcb-docker-gcloud:v20211013-1be7868d8b
in the cloudbuild YAML files.
The Controller Runtime version is now v0.9.+
The Controller Tools version is now v0.6.+
The KIND version used for this release is v0.11.x
This annotation cluster.k8s.io/delete-machine was originally deprecated a while ago when we moved our types under the x-k8s.io domain.
This annotation was previously exported as part of the controllers package, instead this should be a versioned annotation under the api packages.
Rename --metrics-addr to --metrics-bind-addr
Rename --leader-election to --leader-elect
This function was originally used to generate a delegating client when creating a new manager.
Controller Runtime v0.9.x now uses a ClientBuilder in its Options struct and it uses
the delegating client by default under the hood, so this can be now removed.
The functions fake.NewFakeClientWithScheme and fake.NewFakeClient have been deprecated.
Switch to fake.NewClientBuilder().WithObjects().Build() instead, which provides a cleaner interface
to create a new fake client with objects, lists, or a scheme.
Up until v1alpha3, the need of supporting multiple credentials was addressed by running multiple
instances of the same provider, each one with its own set of credentials while watching different namespaces.
Starting from v1alpha4 instead we are going require that an infrastructure provider should manage different credentials,
each one of them corresponding to an infrastructure tenant.
see Multi-tenancy and Support multiple instances for
more details.
Specific changes related to this topic will be detailed in this document.
The conversion-gen code from the 1.20.x release onward generates incorrect conversion functions for types having arrays of pointers to custom objects. Change the existing types to contain objects instead of pointer references.
Add optional flag --webhook-cert-dir={string-value} which allows user to specify directory where webhooks will get tls certificates.
If flag has not provided, default value from controller-runtime should be used.
In an effort to simplify the management of Cluster API components, and realign with Kubebuilder configuration,
we’re requiring some changes to move all webhooks back into a single deployment manager, and to allow Cluster
API watch all namespaces it manages.
For a /config folder reference, please use the testdata in the Kubebuilder project: https://github.com/kubernetes-sigs/kubebuilder/tree/release-3.15/testdata/project-v3/config
Pre-requisites
Provider’s /config folder has the same structure of /config folder in CAPI controllers.
Changes in the /config/webhook folder:
Edit the /config/webhook/kustomization.yaml file:
Edit the config/webhook/kustomizeconfig.yaml file:
In the varReference: list, remove the item with kind: Deployment
Edit the /config/webhook/manager_webhook_patch.yaml file and remove
the args list from the manager container.
Move the following files to the /config/default folder
/config/webhook/manager_webhook_patch.yaml/config/webhook/webhookcainjection_patch.yaml
Changes in the /config/manager folder:
Edit the /config/manager/kustomization.yaml file:
Remove the patchesStrategicMerge list
Edit the /config/manager/manager.yaml file:
Add the following items to the args list for the manager container list
- "--metrics-bind-addr=127.0.0.1:8080"
Verify that feature flags required by your container are properly set
(as it was in /config/webhook/manager_webhook_patch.yaml).
Edit the /config/manager/manager_auth_proxy_patch.yaml file:
Remove the patch for the container with name manager
Move the following files to the /config/default folder
/config/manager/manager_auth_proxy_patch.yaml/config/manager/manager_image_patch.yaml/config/manager/manager_pull_policy.yaml
Changes in the /config/default folder:
Create a file named /config/default/kustomizeconfig.yaml with the following content:
# This configuration is for teaching kustomize how to update name ref and var substitution
varReference:
- kind: Deployment
path: spec/template/spec/volumes/secret/secretName
Edit the /config/default/kustomization.yaml file:
Changes in the /config folder:
Remove the /config/kustomization.yaml file
Remove the /config/patch_crd_webhook_namespace.yaml file
Changes in the main.go file:
Change default value for the flags webhook-port flag to 9443
Change your code so all the controllers and the webhooks are started no matter if the webhooks port selected.
Other changes:
makefile
update all the references for /config/manager/manager_image_patch.yaml to /config/default/manager_image_patch.yaml
update all the references for /config/manager/manager_pull_policy.yaml to /config/default/manager_pull_policy.yaml
update all the call to kustomize targeting /config to target /config/default instead.
E2E config files
update provider sources reading from /config to read from /config/default instead.
clusterctl-settings.json file
if the configFolder value is defined, update from /config to /config/default.
NB. instructions assumes “Required kustomize changes to have a single manager watching all namespaces and answer to webhook calls”
should be executed before this changes.
Changes in the /config/certmanager folder:
Edit the /config/certmanager/certificate.yaml file and replace all the occurrences of cert-manager.io/v1alpha2
with cert-manager.io/v1
Changes in the /config/default folder:
Edit the /config/default/kustomization.yaml file and replace all the occurrences of
kind: Certificate
group: cert-manager.io
version: v1alpha2
kind: Certificate
group: cert-manager.io
version: v1
A new label cluster.x-k8s.io/watch-filter provides the ability to filter the controllers to only reconcile objects with a specific label.
A new flag watch-filter enables users to specify the label value for the cluster.x-k8s.io/watch-filter label on controller boot.
The flag which enables users to set the flag value can be structured like this:
fs.StringVar(&watchFilterValue, "watch-filter", "", fmt.Sprintf("Label value that the controller watches to reconcile cluster-api objects. Label key is always %s. If unspecified, the controller watches for all cluster-api objects.", clusterv1.WatchLabel))
The ResourceNotPausedAndHasFilterLabel predicate is a useful helper to check for the pause annotation and the filter label easily:
c, err := ctrl.NewControllerManagedBy(mgr).
For(&clusterv1.MachineSet{}).
Owns(&clusterv1.Machine{}).
Watches(
&source.Kind{Type: &clusterv1.Machine{}},
handler.EnqueueRequestsFromMapFunc(r.MachineToMachineSets),
).
WithOptions(options).
WithEventFilter(predicates.ResourceNotPausedAndHasFilterLabel(ctrl.LoggerFrom(ctx), r.WatchFilterValue)).
Build(r)
if err != nil {
return errors.Wrap(err, "failed setting up with a controller manager")
}
Create a new service account such as:
apiVersion: v1
kind: ServiceAccount
metadata:
name: manager
namespace: system
Change the subject of the managers ClusterRoleBinding to match:
subjects:
- kind: ServiceAccount
name: manager
namespace: system
Add the correct serviceAccountName to the manager deployment:
serviceAccountName: manager
MachineDeployment.Spec.Strategy.RollingUpdate.MaxSurge, MachineDeployment.Spec.Strategy.RollingUpdate.MaxUnavailable and MachineHealthCheck.Spec.MaxUnhealthy would have previously taken a String value with an integer character in it e.g “3” as a valid input and process it as a percentage value.
Only String values like “3%” or Int values e.g 3 are valid input values now. A string not matching the percentage format will fail, e.g “3”.
A new annotation cluster.x-k8s.io/managed-by has been introduced that allows cluster infrastructure to be managed
externally.
When this annotation is added to an InfraCluster resource, the controller for these resources should not reconcile
the resource.
The ResourceIsNotExternallyManaged predicate is a useful helper to check for the annotation and the filter the resource easily:
c, err := ctrl.NewControllerManagedBy(mgr).
For(&providerv1.InfraCluster{}).
Watches(...).
WithOptions(options).
WithEventFilter(predicates.ResourceIsNotExternallyManaged(ctrl.LoggerFrom(ctx))).
Build(r)
if err != nil {
return errors.Wrap(err, "failed setting up with a controller manager")
}
Note: this annotation also has to be checked in other cases, e.g. when watching for the Cluster resource.
MachinePool is today an experiment, and the API group we originally decided to pick was exp.cluster.x-k8s.io. Given that the intent is in the future to move MachinePool to the core API group, we changed the experiment to use cluster.x-k8s.io group to avoid future breaking changes.
All InfraMachinePool implementations should be moved to infrastructure.cluster.x-k8s.io. See DockerMachinePool for an example.
Note that MachinePools are still experimental after this change and should still be feature gated.
There were a lot of new useful linters added to .golangci.yml. Of course it’s not mandatory to use golangci-lint or
a similar configuration, but it might make sense regardless. Please note there was previously an error in
the exclude configuration which has been fixed in #4657 . As
this configuration has been duplicated in a few other providers, it could be that you’re also affected.
This function used to create a new fake client with the given scheme for testing,
and all the objects given as input were initialized with a resource version of “1”.
The behavior of having a resource version in fake client has been fixed in controller-runtime,
and this function isn’t needed anymore.
NB. instructions assumes “Required kustomize changes to have a single manager watching all namespaces and answer to webhook calls”
should be executed before this changes.
Changes in the /config/default folder:
Edit /config/default/kustomization.yaml and remove the manager_auth_proxy_patch.yaml item from the patchesStrategicMerge list.
Delete the /config/default/manager_auth_proxy_patch.yaml file.
Changes in the /config/manager folder:
Edit /config/manager/manager.yaml and remove the --metrics-bind-addr=127.0.0.1:8080 arg from the args list.
Changes in the /config/rbac folder:
Edit /config/rbac/kustomization.yaml and remove following items from the resources list.
auth_proxy_service.yamlauth_proxy_role.yamlauth_proxy_role_binding.yaml
Delete the /config/rbac/auth_proxy_service.yaml file.
Delete the /config/rbac/auth_proxy_role.yaml file.
Delete the /config/rbac/auth_proxy_role_binding.yaml file.
Changes in the main.go file:
Change the default value for the metrics-bind-addr from :8080 to localhost:8080
spec.infrastructureTemplate has been moved to spec.machineTemplate.infrastructureRef. Thus, cluster templates which include KubeadmControlPlane
have to be adjusted accordingly.spec.nodeDrainTimeout has been moved to spec.machineTemplate.nodeDrainTimeout.
ControlPlane implementations using version must now include a ‘version’ field as defined below in both its spec and its status .
spec.version - is a string representing the Kubernetes version to be used
by the control plane machines. The value must be a valid semantic version;
also if the value provided by the user does not start with the v prefix, it
must be added.
status.version - is a string representing the minimum Kubernetes version for the control plane machines in the cluster.
Please note that implementing these fields are a requirement for a control plane provider to be used with ClusterClass and managed topologies.
ControlPlane implementations that use an underlying MachineInfrastructure must now include a ‘machineTemplate’ as defined below, with subordinate fields, in its Spec.
machineTemplate - is a struct containing details of the control plane
machine template.
Please note that implementing this field for control plane providers using machines is a requirement for ClusterClass and managed topologies to work consistently across all providers.
The Go version used by Cluster API is still Go 1.16+
The Controller Runtime version is now v0.10.+
The Controller Tools version is now v0.7.+
The KIND version used for this release is still v0.11.x
The core ClusterAPI providers will support upgrade from v1alpha3 and v1alpha4 to v1beta1. Thus, conversions of API types
from v1alpha3 and v1alpha4 to v1beta1 have been implemented. If other providers also want to support the upgrade from v1alpha3 and
v1alpha4, the same conversions have to be implemented.
The serving-cert certificates now have organization set to k8s-sig-cluster-lifecycle.
ClusterTopologyLabelName , a ClusterClass related constant has been deprecated and removed. This label has been replaced by ClusterTopologyOwnedLabel.
MachineNodeNameIndex has been removed from the common types in favor of api/v1beta1/index.MachineNodeNameField.
MachineProviderNameIndex has been removed from common types in favor of api/v1beta1/index.MachineProviderIDField.
TemplateSuffix has been removed in favor of api/v1alpha4.TemplatePrefix.AddMachineNodeIndex has been removed in favor of api/v1alpha4/index.ByMachineNodeGetMachineFromNode has been removed. This functionality is now private in the controllers package.ConverReferenceAPIContract has been removed in favor of UpdateReferenceAPIContract in the util/conversion package.ParseMajorMinorPatch has been removed in favor of ParseMajorMinorPatch in the util/version package.GetMachinesForCluster has been removed in favor of GetFilteredMachinesForCluster in the util/collection package.GetControlPlaneMachines has been removed in favor of FromMachines(machine).Filter(collections.ControlPlaneMachines(cluster.Name)) in the util/collection package.GetControlPlaneMachinesFromList has been removed in favor of FromMachineList(machines).Filter(collections.ControlPlaneMachines(cluster.Name)) in the util/collection package.GetCRDMetadataFromGVK has been removed in favor of GetGVKMetadata.Ensure your template resources support template.meta fields. Refer to the cluster and
machine provider contract docs for more information. This is not required, but is recommended for
consistency across the infrastructure providers as Cluster API graduates and opens up use cases where coordinating
controllers can use labels and annotations from template infrastructure resources to do external provisioning or
provide configuration information, e.g. IPAM support for vSphere / bare-metal .
Labels and annotations from KubeadmControlPlane, MachineDeployment and MachineSet and their .spec.template.metadata fields are now selectively propagated to objects controlled by their respective controllers. Refer to metadata-propagation for more information.
The v1beta1 release uses “leases” instead of “configmapsleases” as the LeaderElectionResourceLock for all managers leader election including the core controllers, bootstrap and control plane kubeadm and the Docker provider.
This has no user facing impact on brand-new clusters created as v1beta1.
For Cluster API running clusters upgraded through clusterctl this should be ok given that we stop the old controllers.
Users relying on custom upgrades procedures should ensure a migration to v1alpha4 (multilock “configmapsleases”) first, which will acquire a leader lock on both resources. After that, they can proceed migrating to v1beta1 (”leases”). As an additional safety step, these users should ensure the old controllers are stopped before running the new ones with the new lock mechanism.
Otherwise, your controller might end up with multiple running instances that each acquired leadership through different resource locks during upgrades and thus act on the same resources concurrently.
This document provides an overview over relevant changes between ClusterAPI v1.0 and v1.1 for
maintainer of other providers and consumers of our Go API.
The Go version used by Cluster API is now Go 1.17+
Note : Only the most relevant dependencies are listed, k8s.io/ and ginkgo/gomega dependencies
are kept in sync with the versions used by sigs.k8s.io/controller-runtime.
sigs.k8s.io/controller-runtime: v0.10.x => v0.11.x
k8s.io/*: v0.22.x => v0.23.x (derived from controller-runtime)
github.com/go-logr/logr: v0.4.0 => v1.2.0 (derived from controller-runtime)
k8s.io/klog/v2: v2.9.0 => v2.30.0 (derived from controller-runtime)
sigs.k8s.io/controller-tools: v0.7.x => v0.8.x
sigs.k8s.io/kind: v0.11.x => v0.11.x
The Cluster and ClusterClass webhooks have been moved to the webhooks package. Thus, the following methods on Cluster and ClusterClass
in api/v1beta1 are deprecated: SetupWebhookWithManager, Default, ValidateCreate, ValidateUpdate and ValidateDelete.
The third_party/kubernetes-drain package is deprecated, as we’re now using k8s.io/kubectl/pkg/drain instead (PR ).
util/version.CompareWithBuildIdentifiers has been deprecated, please use util/version.Compare(a, b, WithBuildTags()) instead.The functions annotations.HasPausedAnnotation and annotations.HasSkipRemediationAnnotation have been deprecated, please use
annotations.HasPaused and annotations.HasSkipRemediation respectively instead.
KCPUpgradeSpec has been removed. Please use ClusterUpgradeConformanceSpec instead.
Some controllers have been moved to internal to reduce their API surface. We now only
surface what is necessary, e.g. the reconciler and the SetupWithManager func:
Following packages have been moved to internal
ClusterClass:
clusterctl is now able to handle cluster templates with ClusterClasses (PR ).
Please check out the corresponding documentation in clusterctl provider contract
If you have any further questions about writing ClusterClasses, please let us know.e2e tests:
QuickStartSpec is now able to test clusters using ClusterClass. Please see this PR for an example on how to use it.SelfHostedSpec is now able to test clusters using ClusterClass. Please see this PR for an example on how to use it.
Test framework provides better logging in case of failures when creating the bootstrap kind cluster; in order to
fully exploit this feature, it is required to pass the LogFolder parameter when calling CreateKindBootstrapClusterAndLoadImages. Please see this PR for an example on how to use it.
The gci linter has been enabled to enforce consistent imports. As usual, feel free to take a look at our linter config, but of course it’s not mandatory to adopt it.
The Tilt dev setup has been extended with:
This document provides an overview over relevant changes between ClusterAPI v1.1 and v1.2 for
maintainers of providers and consumers of our Go API.
The minimum Kubernetes version that can be used for a management cluster is now 1.20.0
The minimum Kubernetes version that can be used for a management cluster with ClusterClass is now 1.22.0
NOTE: compliance with minimum Kubernetes version is enforced both by clusterctl and when the CAPI controller starts.
The Go version used by Cluster API is now Go 1.18.x
If you are using the gcb-docker-gcloud image in cloudbuild, bump to an image which is using
Go 1.18, e.g.: gcr.io/k8s-staging-test-infra/gcb-docker-gcloud:v20220609-2e4c91eb7e.
Note : Only the most relevant dependencies are listed, k8s.io/ and ginkgo/gomega dependencies
in ClusterAPI are kept in sync with the versions used by sigs.k8s.io/controller-runtime.
sigs.k8s.io/controller-runtime: v0.11.x => v0.12.3
sigs.k8s.io/controller-tools: v0.8.x => v0.9.x
sigs.k8s.io/kind: v0.11.x => v0.14.x
k8s.io/*: v0.23.x => v0.24.x (derived from controller-runtime)
github.com/onsi/gomega: v0.17.0 => v0.18.1 (derived from controller-runtime)
k8s.io/kubectl: v0.23.5 => 0.24.0
util.MachinesByCreationTimestamp has been deprecated and will be removed in a future release.the topology.cluster.x-k8s.io/managed-field-paths annotation has been deprecated and will be removed in a future release.
the experimentalRetryJoin field in the KubeadmConfig and, as they compose the same types, KubeadmConfigTemplate, KubeadmControlPlane and KubeadmControlPlaneTemplate, has been deprecated and will be removed in a future release.
The third_party/kubernetes-drain package has been removed, as we’re now using k8s.io/kubectl/pkg/drain instead (PR ).
util/version.CompareWithBuildIdentifiers has been removed, please use util/version.Compare(a, b, WithBuildTags()) instead.The functions annotations.HasPausedAnnotation and annotations.HasSkipRemediationAnnotation have been removed, please use
annotations.HasPaused and annotations.HasSkipRemediation respectively instead.
ObjectMeta.ClusterName has been removed from k8s.io/apimachinery/pkg/apis/meta/v1.
util.ClusterToInfrastructureMapFuncWithExternallyManagedCheck was removed and the externally managed check was added to util.ClusterToInfrastructureMapFunc, which required changing its signature.
Users of the former simply need to start using the latter and users of the latter need to add the new arguments to their call.conditions.NewPatch from the “sigs.k8s.io/cluster-api/util/conditions” package has had its return type modified. Previously the function returned Patch. It now returns (Patch, error). Users of NewPatch need to be update usages to handle the error.
ClusterClass and managed topologies are now using Server Side Apply
to properly manage other controllers like CAPA/CAPZ coauthoring slices, see #6320 .
In order to take advantage of this feature providers are required to add marker to their API types as described in
merge-strategy .
NOTE: the change will cause a rollout on existing clusters created with ClusterClass
E.g. in CAPA
// +optional
Subnets Subnets `json:"subnets,omitempty"
Must be modified into:
// +optional
// +listType=map
// +listMapKey=id
Subnets Subnets `json:"subnets,omitempty"
Server Side Apply implementation in ClusterClass and managed topologies
requires to dry-run changes on templates. If infrastructure or bootstrap providers have implemented immutability checks
in their InfrastructureMachineTemplate or BootstrapConfigTemplate webhooks,
it is required to implement the following changes in order to prevent dry-run to return errors.
The implementation requires sigs.k8s.io/controller-runtime in version >= v0.12.3.
E.g. in CAPD following changes should be applied to the DockerMachineTemplate webhook:
+ type DockerMachineTemplateWebhook struct{}
+ func (m *DockerMachineTemplateWebhook) SetupWebhookWithManager(mgr ctrl.Manager) error {
- func (m *DockerMachineTemplate) SetupWebhookWithManager(mgr ctrl.Manager) error {
return ctrl.NewWebhookManagedBy(mgr).
- For(m).
+ For(&DockerMachineTemplate{}).
+ WithValidator(m).
Complete()
}
// +kubebuilder:webhook:verbs=create;update,path=/validate-infrastructure-cluster-x-k8s-io-v1beta1-dockermachinetemplate,mutating=false,failurePolicy=fail,matchPolicy=Equivalent,groups=infrastructure.cluster.x-k8s.io,resources=dockermachinetemplates,versions=v1beta1,name=validation.dockermachinetemplate.infrastructure.cluster.x-k8s.io,sideEffects=None,admissionReviewVersions=v1;v1beta1
+ var _ webhook.CustomValidator = &DockerMachineTemplateWebhook{}
- var _ webhook.Validator = &DockerMachineTemplate{}
+ func (*DockerMachineTemplateWebhook) ValidateCreate(ctx context.Context, _ runtime.Object) error {
- func (m *DockerMachineTemplate) ValidateCreate() error {
...
}
+ func (*DockerMachineTemplateWebhook) ValidateUpdate(ctx context.Context, oldRaw runtime.Object, newRaw runtime.Object) error {
+ newObj, ok := newRaw.(*DockerMachineTemplate)
+ if !ok {
+ return apierrors.NewBadRequest(fmt.Sprintf("expected a DockerMachineTemplate but got a %T", newRaw))
+ }
- func (m *DockerMachineTemplate) ValidateUpdate(oldRaw runtime.Object) error {
oldObj, ok := oldRaw.(*DockerMachineTemplate)
if !ok {
return apierrors.NewBadRequest(fmt.Sprintf("expected a DockerMachineTemplate but got a %T", oldRaw))
}
+ req, err := admission.RequestFromContext(ctx)
+ if err != nil {
+ return apierrors.NewBadRequest(fmt.Sprintf("expected a admission.Request inside context: %v", err))
+ }
...
// Immutability check
+ if !topology.ShouldSkipImmutabilityChecks(req, newObj) &&
+ !reflect.DeepEqual(newObj.Spec.Template.Spec, oldObj.Spec.Template.Spec) {
- if !reflect.DeepEqual(m.Spec.Template.Spec, old.Spec.Template.Spec) {
allErrs = append(allErrs, field.Invalid(field.NewPath("spec", "template", "spec"), m, dockerMachineTemplateImmutableMsg))
}
...
}
+ func (*DockerMachineTemplateWebhook) ValidateDelete(ctx context.Context, _ runtime.Object) error {
- func (m *DockerMachineTemplate) ValidateDelete() error {
...
}
NOTES:
We are introducing a DockerMachineTemplateWebhook struct because we are going to use a controller runtime
CustomValidator. This will allow to skip the immutability check only when the topology controller is dry running
while preserving the validation behaviour for all other cases.
By using CustomValidators it is possible to move webhooks to other packages, thus removing some controller
runtime dependency from the API types. However, choosing to do so or not is up to the provider implementers
and independent of this change.
Logging:
To align with the upstream Kubernetes community CAPI now configures logging via component-base/logs.
This provides advantages like support for the JSON logging format (via --logging-format=json) and automatic
deprecation of klog flags aligned to the upstream Kubernetes deprecation period.
View main.go diff
import (
...
+ "k8s.io/component-base/logs"
+ _ "k8s.io/component-base/logs/json/register"
)
var (
...
+ logOptions = logs.NewOptions()
)
func init() {
- klog.InitFlags(nil)
func InitFlags(fs *pflag.FlagSet) {
+ logs.AddFlags(fs, logs.SkipLoggingConfigurationFlags())
+ logOptions.AddFlags(fs)
func main() {
...
pflag.Parse()
+ if err := logOptions.ValidateAndApply(); err != nil {
+ setupLog.Error(err, "unable to start manager")
+ os.Exit(1)
+ }
+
+ // klog.Background will automatically use the right logger.
+ ctrl.SetLogger(klog.Background())
- ctrl.SetLogger(klogr.New())
This change has been introduced in CAPI in the following PRs: #6072 , #6190 , #6602 .
Note : This change is not mandatory for providers, but highly recommended.
Following E2E framework functions are now checking that machines are created in the expected failure domain (if defined);
all E2E tests can now verify failure domains too.
ApplyClusterTemplateAndWaitWaitForControlPlaneAndMachinesReadyDiscoveryAndWaitForMachineDeployments
The AssertControlPlaneFailureDomains function in the E2E test framework has been modified to allow proper failure domain testing.
After investigating an issue we discovered that improper implementation of a check on cluster.status.infrastructureReady can lead to problems during cluster deletion. As a consequence, we recommend that all providers ensure:
The check for cluster.status.infrastructureReady=true usually existing at the beginning of the reconcile loop for control-plane providers is implemented after setting external objects ref;
The check for cluster.status.infrastructureReady=true usually existing at the beginning of the reconcile loop for infrastructure provider does not prevent the object to be deletedPR #6183
CAPI added support for the new control plane label and taint introduced by v1.24 with PR#5919 .
Providers should tolerate both control-plane and master taints for compatibility with v1.24 control planes.
Further, if they use the label in their manager.yaml, it should be adjusted since v1.24 only adds the node-role.kubernetes.io/control-plane label.
An example of such an accommodation can be seen in the capi-provider-aws manager.yaml
This document provides an overview over relevant changes between Cluster API v1.2 and v1.3 for
maintainers of providers and consumers of our Go API.
The Go version used by Cluster API is Go 1.19.x
Note : Only the most relevant dependencies are listed, k8s.io/ and ginkgo/gomega dependencies
in Cluster API are kept in sync with the versions used by sigs.k8s.io/controller-runtime.
sigs.k8s.io/controller-runtime: v0.12.x => v0.13.x
sigs.k8s.io/controller-tools: v0.9.x => v0.10.x
sigs.k8s.io/kind: v0.14.x => v0.18.x
k8s.io/*: v0.24.x => v0.25.x (derived from controller-runtime)
github.com/onsi/ginkgo: v1.x => v2.x (derived from controller-runtime)
k8s.io/kubectl: v0.24.x => 0.25.x
github.com/joelanford/go-apidiff: 0.4.0 => 0.5.0
sigs.k8s.io/cluster-api/controllers/external.CloneTemplate has been deprecated and will be removed in a future release. Please use sigs.k8s.io/cluster-api/controllers/external.CreateFromTemplate instead.clusterctl init --list-images has been deprecated and will be removed in a future release. Please use clusterctl init list-images instead.clusterctl backup has been deprecated. Please use clusterctl move --to-directory instead.clusterctl restore has been deprecated. Please use clusterctl move --from-directory instead.Client deprecates Backup and Restore. Please use Move.ObjectMover deprecates Backup and Restore. Adds replacements functions ToDirectory and FromDirectory.
MachinesByCreationTimestamp type has been removed.ClusterCacheReconciler.Log has been removed. Use the logger from the context instead.
A new timeout nodeVolumeDetachTimeout has been introduced that defines how long the controller will spend on waiting for all volumes to be detached.
The default value is 0, meaning that the volume can be detached without any time limitations.
A new annotation machine.cluster.x-k8s.io/exclude-wait-for-node-volume-detach has been introduced that allows explicitly skip the waiting for node volume detaching.
A new annotation "cluster.x-k8s.io/replicas-managed-by" has been introduced to indicate that a MachinePool’s replica enforcement is delegated to an external autoscaler (not managed by Cluster API). For more information see the documentation here .
The Path func in the sigs.k8s.io/cluster-api/cmd/clusterctl/client/repository.Overrider interface has been adjusted to also return an error.
clusterctl now emits a warning for provider CRDs which don’t comply with the CRD naming conventions. This warning can be skipped for resources not referenced by Cluster API
core resources via the clusterctl.cluster.x-k8s.io/skip-crd-name-preflight-check annotation. The contracts specify:
The CRD name must have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind)
The Kubernetes default registry has been changed from k8s.gcr.io to registry.k8s.io. Kubernetes image promotion currently publishes to both registries. Please
consider publishing manifests which reference the controller images from the new registry (for reference Cluster API PR ).
e2e tests are upgraded to use Ginkgo v2 (v2.5.0) and Gomega v1.22.1. Providers who use the test framework from this release will also need to upgrade, because Ginkgo v2 can’t be imported alongside v1. Please see the Ginkgo upgrade guide , and note:
Cluster API introduced new logging guidelines . All reconcilers in the core repository were updated
to log the entire object hierarchy . It would be great if providers would be adjusted
as well to make it possible to cross-reference log entries across providers (please see CAPD for an infra provider reference implementation).
The CreateLogFile function and CreateLogFileInput struct in the E2E test framework for clusterctl has been renamed to OpenLogFile and OpenLogFileInput because the function will now append to the logfile instead of truncating the content.
The Move function in E2E test framework for clusterctl has been modified to:
print the clusterctl move command including the arguments similar to Init.
log the output to the a clusterctl-move.log file at the subdirectory logs/<namespace>.
The self-hosted upgrade test now also upgrades the self-hosted cluster’s Kubernetes version by default. For that it requires the following variables to be set:
KUBERNETES_VERSION_UPGRADE_FROMKUBERNETES_VERSION_UPGRADE_TOETCD_VERSION_UPGRADE_TOCOREDNS_VERSION_UPGRADE_TO
The variable SkipUpgrade could be set to revert to the old behaviour by making use of the KUBERNETES_VERSION variable and skipping the Kubernetes upgrade.
cert-manager upgraded from v1.9.1 to v1.10.1.
Machine providerID is now being strictly checked for equality when compared against Kubernetes node providerID data. This is the expected criteria for correlating a Cluster API machine to its corresponding Kubernetes node, but historically this comparison was not strict, and instead compared only against the ID substring part of the full providerID string. Because different providers construct providerID strings differently, the ID substring is not uniformly defined and implemented across providers, and thus the existing providerID equality cannot guarantee the correct Machine-Node correlation. It is very unlikely that this new behavior will break existing providers, but FYI: if strict providerID equality will degrade expected behaviors, you may need to update your provider implementation prior to adopting Cluster API v1.3.
The default minimum TLS version in use by the webhook servers is 1.2.
OwnerReferences are now more strictly enforced for objects managed by Cluster API. Machines, Bootstrap configs, Infrastructure Machines and Secrets created by CAPI components now have strictly enforced controller owner references . This is not expected to require changes for providers.
Provider can expose the configuration of the TLS Options for the webhook server; it is recommended to use utility functions under the util/flags package to ensure consistency across CAPI and other providers.
This document provides an overview over relevant changes between Cluster API v1.3 and v1.4 for
maintainers of providers and consumers of our Go API.
The Go version used by Cluster API is still Go 1.19.x
Note : Only the most relevant dependencies are listed, k8s.io/ and ginkgo/gomega dependencies in Cluster API are kept in sync with the versions used by sigs.k8s.io/controller-runtime.
sigs.k8s.io/kind: v0.17.x => v0.18.x
sigs.k8s.io/controller-runtime: v0.13.x => v0.14.x
sigs.k8s.io/controller-tools: v0.10.x => v0.11.x
github.com/joelanford/go-apidiff: 0.5.0 => 0.6.0
util/conversion.GetCRDWithContract has been removed.clusterctl backup has been removed.clusterctl restore has been removed.api/v1beta1.MachineHealthCheckSuccededCondition condition type has been removed.controller/external/util.CloneTemplate and controllers/external/util.CloneTemplateInput has been removed.The option --list-images from clusterctl init subcommand has been removed.
exp/runtime/server.NewServer has been removed.--disable-no-echo option from clusterctl describe cluster subcommand has been removedapi/v1beta1.ClusterTopologyManagedFieldsAnnotation field has been removed.api/v1beta1.PopulateDefaultsMachineDeployment func has been removed.
util/conversion.UpdateReferenceAPIContract dropped the APIReader parameter because it’s not required anymore as we now only handle CRDs with compliant names.Backup(options BackupOptions) error in the Client interface has been removed.Restore(options RestoreOptions) error in the Client interface has been removed.cmd/clusterctl/client.RolloutOptions has been removed, RolloutRestartOptions, RolloutPauseOptions , RolloutResumeOptions, and RolloutUndoOptions have been added instead.Annotation constant DisableMachineCreate has been updated to DisableMachineCreateAnnotation
Below Label constant have been updated
ClusterLabelName to ClusterNameLabelClusterTopologyMachineDeploymentLabelName to ClusterTopologyMachineDeploymentNameLabelProviderLabelName to ProviderNameLabelMachineControlPlaneLabelName to MachineControlPlaneLabelMachineSetLabelName to MachineSetNameLabelMachineDeploymentLabelName to MachineDeploymentNameLabel
Below Condition and Reason constants have been updated
ExternalRemediationTemplateAvailable to ExternalRemediationTemplateAvailableConditionExternalRemediationTemplateNotFound to ExternalRemediationTemplateNotFoundReasonExternalRemediationRequestAvailable to ExternalRemediationRequestAvailableConditionExternalRemediationRequestCreationFailed to ExternalRemediationRequestCreationFailedReason
api/v1beta1.MachineDeployment.Default func has been replaced through api/v1beta1.MachineDeploymentDefaulter
clusterctl now emits an error for provider CRDs which don’t comply with the CRD naming conventions. This warning can be skipped for resources not referenced by Cluster API
core resources via the clusterctl.cluster.x-k8s.io/skip-crd-name-preflight-check annotation. The contracts specify:
The CRD name must have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind)
clusterctl upgrade apply no longer requires a namespace when updating providers. It is now optional and in a future release it will be deprecated. The new syntax is [namespace/]provider:version.WatchDeploymentLogs is changed to WatchDeploymentLogsByName, it works same as before. Another function WatchDeploymentLogsByLabelSelector is added to stream logs of deployment by label selector.Cluster API controllers are now using an explicit security context by default.
It is recommended to drop usages of logs.AddFlags(fs, logs.SkipLoggingConfigurationFlags()). It was previously used to configure deprecated logging flags, but with the bump to component-base
v0.26.0 this function is not configuring any flags anymore.
Please note that the following logging flags have been removed: (in component-base, but this affects all CAPI controllers): --add-dir-header, --alsologtostderr, --log-backtrace-at,
--log-dir, --log-file, --log-file-max-size, --logtostderr, --one-output, --skip-headers, --skip-log-headers and --stderrthreshold.
For more information, please see: https://github.com/kubernetes/enhancements/issues/2845
A new KCPRemediationSpec test has been added providing better test coverage for KCP remediation most common use cases. As a consequence MachineRemediationSpec has been renamed to MachineDeploymentRemediationSpec and now only tests remediation of worker machines (NOTE: we plan to improve this test as well in a future iteration).
Package test/infrastructure/docker/internal/third_party/forked/loadbalancer has been moved to test/infrastructure/docker/internal/loadbalancer to allow it to diverge from the upstream Kind package.
Providers should add an explicit security context to their controllers deployment, see #7831 for reference.
This document provides an overview over relevant changes between Cluster API v1.4 and v1.5 for
maintainers of providers and consumers of our Go API.
The Go version used by Cluster API is Go 1.20.x
Note : Only the most relevant dependencies are listed, k8s.io/ and ginkgo/gomega dependencies in Cluster API are kept in sync with the versions used by sigs.k8s.io/controller-runtime.
sigs.k8s.io/kind: v0.17.x => v0.20.x
sigs.k8s.io/controller-runtime: v0.14.x => v0.15.x
sigs.k8s.io/controller-tools: v0.11.x => v0.12.x
API versionv1alpha4 is deprecated and CAPI will stop serving this version in v1.6.
sigs.k8s.io/cluster-api/controllers/remote.DefaultIndexex has been deprecated and will be removed in a future release. Please use sigs.k8s.io/cluster-api/controllers/external.NodeProviderIDIndex instead. This index should not be used as a default index and should only be used if a controller is using index.NodeProviderIDField.
API version v1alpha3 is not served in v1.5 (users can enable it manually in case they are lagging behind with deprecation cycles). Important: v1alpha3 will be completely removed in 1.6.
The lazy restmapper feature gate was removed in controller-runtime and lazy restmapper is now the default restmapper. Accordingly the EXP_LAZY_RESTMAPPER feature gate was removed in Cluster API.
InfrastructureMachinePools now include an optional status field for infrastructureMachineKind. This allows infrastructure providers to support MachinePool Machines by having the InfraMachinePool set the infrastructureMachineKind to the kind of their InfrastructureMachines. The InfrastructureMachinePool will be responsible for creating InfrastructureMachines as the MachinePool is scaled up, and the MachinePool controller will create Machines for each InfrastructureMachine and set the ownerRef. The InfrastructureMachinePool will be responsible for deleting the Machines as the MachinePool is scaled down in order for the Machine deletion workflow to function properly. In addition, the InfrastructureMachines must also have the following labels set by the InfrastructureMachinePool: cluster.x-k8s.io/cluster-name and cluster.x-k8s.io/pool-name. The MachinePoolNameLabel must also be formatted with capilabels.MustFormatValue() so that it will not exceed character limits. See the MachinePool Machines proposal for more details and the CAPD implementation for a reference.
clusterctl move is adding the new annotation clusterctl.cluster.x-k8s.io/delete-for-move before object deletion.
Providers running CAPI release-0.3 clusterctl upgrade tests should set WorkloadKubernetesVersion field to the maximum workload cluster kubernetes version supported by the old providers in ClusterctlUpgradeSpecInput. For more information, please see: https://github.com/kubernetes-sigs/cluster-api/pull/8518#issuecomment-1508064859
Introduced function CollectInfrastructureLogs at the ClusterLogCollector interface in test/framework/cluster_proxy.go to allow collecting infrastructure related logs during tests.
A GetTypedConfigOwner function has been added to the sigs.k8s.io./cluster-api/bootstrap/util package. It is equivalent to GetConfigOwner except that it uses the cached typed client instead of the uncached unstructured client, so GetTypedConfigOwner is expected to be more performant.
ClusterToObjectsMapper in sigs.k8s.io./cluster-api/util has been deprecated, please use ClusterToTypedObjectsMapper instead.The generated kubeconfig by the Control Plane providers must be labelled with the key-value pair cluster.x-k8s.io/cluster-name=${CLUSTER_NAME}.
This is required for the CAPI managers caches to store and retrieve them for the required operations.
When using custom certificates, the certificates must be labeled with the key-value pair cluster.x-k8s.io/cluster-name=${CLUSTER_NAME}.
This is required for the CAPI managers caches to store and retrieve them for the required operations.
This section shares our learnings of bumping controller-runtime to v0.15 in core Cluster API. It highlights the most relevant changes and pitfalls
for Cluster API providers. For the full list of changes please see the controller-runtime release notes .
Webhooks can now also return warnings, this requires adding an additional admission.Warnings return parameter to all webhooks.
Manager options have been refactored and old fields have been deprecated.
Manager now has a builtin profiler server which can be enabled via Options.PprofBindAddress, this allows us to remove our profiler server.
Controller builder has been refactored, this requires small changes to our controller setup code.
The EventHandler interface has been modified to also take a context, which affects our mapping functions (e.g. ClusterToInfrastructureMapFunc).
Controller-runtime now uses a lazy restmapper per default, i.e. API groups and resources are only fetched when they are actually used.
This should drastically reduce the amount of API calls in clusters with a lot of CRDs.
Some wait utils in k8s.io/apimachinery/pkg/util/wait have been deprecated. The migration is relatively straightforward except that passing in 0
as a timeout in wait.PollUntilContextTimeout is treated as a timeout with 0 seconds, in wait.PollImmediateWithContext it is interpreted as infinity.
The fake client has been improved to handle status properly. In tests that write the CRD status, the CRDs should be added to the fake client via WithStatusSubresource.
Ensure that the e2e test suite is setting a logger (e.g. via ctrl.SetLogger(klog.Background()) in TestE2E. Otherwise logs are not visible and controller-runtime will print a warning.
For reference, please see the Bump to CR v0.15 PR in core Cluster API.
This document provides an overview over relevant changes between Cluster API v1.5 and v1.6 for
maintainers of providers and consumers of our Go API.
The Go version used by Cluster API is Go 1.20.x
Note : Only the most relevant dependencies are listed, k8s.io/ and ginkgo/gomega dependencies in Cluster API are kept in sync with the versions used by sigs.k8s.io/controller-runtime.
sigs.k8s.io/kind: v0.20.x
sigs.k8s.io/controller-runtime: v0.15.x => v0.16.x
sigs.k8s.io/controller-tools: v0.12.x
Introduced v1beta1 for ipam.cluster.x-k8s.io IPAddresses and IPAddressClaims. Conversion webhooks handle translation between the hub version v1beta1 and spoke v1alpha1.
The function sigs.k8s.io/cluster-api/addons/api/v1beta1 DeleteBinding has been deprecated. Please use RemoveBinding from the same package instead.
API version v1alpha4 is not served in v1.6 (users can enable it manually in case they are lagging behind with deprecation cycles). Important: v1alpha4 will be completely removed in 1.7.
The function(s):
ClusterToObjectsMapper is removed, please use ClusterToTypedObjectsMapper function instead.Poll and PollImmediate are removed, please use utils from “k8s.io/apimachinery/pkg/util/wait” instead.
The variable DefaultIndexes is removed, please use []Index{NodeProviderIDIndex}
ProviderID type and all related methods/construct have been removed. Please see this PR for a reference.
Several public functions in cmd/clusterctl/ now require context.Context as the first parameter.
clusterctl move can be blocked temporarily by a provider when an object to be moved is annotated with clusterctl.cluster.x-k8s.io/block-move.mdbook releaselink has been changed to require a repo tag when used in markdown files for generating a book with mdbook.framework.DumpKubeSystemPodsForCluster was renamed to framework.DumpResourcesForCluster to facilitate the gathering of additional workload cluster resources. Pods in all namespaces and Nodes are gathered from workload clusters. Pod yamls are available in clusters/*/resources/Pod and Node yaml is available in clusters/*/resources/Node.
In order to reduce dependencies for API package consumers, CAPI has diverged from the default kubebuilder scheme builder. This new pattern may also be useful for reducing dependencies in provider API packages. For more information see the implementers guide.
We deprecated the --metrics-bind-addr flag and introduced the new --diagnostics-address and --insecure-diagnostic flags. These flags allow exposing metrics, a pprof endpoint and
an endpoint to change log levels securely in production. It is recommended to implement the same changes in providers, please see #9264 for more details.
This document provides an overview over relevant changes between Cluster API v1.6 and v1.7 for
maintainers of providers and consumers of our Go API.
The Go version used by Cluster API is Go 1.21.x
Note : Only the most relevant dependencies are listed, k8s.io/ and ginkgo/gomega dependencies in Cluster API are kept in sync with the versions used by sigs.k8s.io/controller-runtime.
sigs.k8s.io/kind: v0.20.x => v0.22.x
API version v1alpha4 is now completely removed.
Patch helper now return error with enough error context (https://github.com/kubernetes-sigs/cluster-api/pull/9946). It is recommended to remove redundant error context on call sites if applicable.
MachinePools are now enabled by default and the feature flag is marked as beta instead of alpha. If you are re-defining feature flags in your codebase, these values will need to be updated accordingly. If not, the following error will result:
panic: feature gate "MachinePool" with different spec already exists: {true false BETA}
See this change for how to update the flag.
Cluster API defines a contract which requires providers to implement certain fields and patterns in their CRDs and controllers. This contract is required for providers to work correctly with Cluster API.
Cluster API defines the following contracts:
Providers MUST set cluster.x-k8s.io/<version> label on all Custom Resource Definitions related to Cluster API starting with v1alpha3.
The label is a map from an API Version of Cluster API (contract) to your Custom Resource Definition versions.
The value is an underscore-delimited (_) list of versions.
Each value MUST point to an available version in your CRD Spec.
The label allows Cluster API controllers to perform automatic conversions for object references, the controllers will pick the last available version in the list if multiple versions are found.
To apply the label to CRDs it’s possible to use commonLabels in your kustomize.yaml file, usually in config/crd.
In this example we show how to map a particular Cluster API contract version to your own CRD using Kustomize’s commonLabels feature, in your config/crd/kustomization.yaml:
commonLabels:
cluster.x-k8s.io/v1alpha2: v1alpha1
cluster.x-k8s.io/v1alpha3: v1alpha2
cluster.x-k8s.io/v1beta1: v1beta1
An example of this is in the Kubeadm Bootstrap provider .
The definition of the contract between Cluster API and providers may be changed in future versions of Cluster API. The Cluster API maintainers welcome feedback and contributions to the contract in order to improve how it’s defined, its clarity and visibility to provider implementers and its suitability across the different kinds of Cluster API providers. To provide feedback or open a discussion about the provider contract please open an issue on the Cluster API repo or add an item to the agenda in the Cluster API community meeting .
A cluster infrastructure provider supplies whatever prerequisites are necessary for running machines.
Examples might include networking, load balancers, firewall rules, and so on.
A cluster infrastructure provider must define an API type for “infrastructure cluster” resources. The type:
Must belong to an API group served by the Kubernetes apiserver
Must be implemented as a CustomResourceDefinition.
The CRD name must have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
Must be namespace-scoped
Must have the standard Kubernetes “type metadata” and “object metadata”
Must have a spec field with the following:
Required fields:
controlPlaneEndpoint (apiEndpoint): the endpoint for the cluster’s control plane. apiEndpoint is defined
as:
host (string): DNS name or IP addressport (int32): TCP port
Must have a status field with the following:
Required fields:
ready (boolean): indicates the provider-specific infrastructure has been provisioned and is ready
Optional fields:
failureReason (string): indicates there is a fatal problem reconciling the provider’s infrastructure;
meant to be suitable for programmatic interpretationfailureMessage (string): indicates there is a fatal problem reconciling the provider’s infrastructure;
meant to be a more descriptive value than failureReasonfailureDomains (FailureDomains): the failure domains that machines should be placed in. FailureDomains
is a map, defined as map[string]FailureDomainSpec. A unique key must be used for each FailureDomainSpec.
FailureDomainSpec is defined as:
controlPlane (bool): indicates if failure domain is appropriate for running control plane instances.attributes (map[string]string): arbitrary attributes for users to apply to a failure domain.
For a given InfraCluster resource, you should also add a corresponding InfraClusterTemplate resources:
// InfraClusterTemplateSpec defines the desired state of InfraClusterTemplate.
type InfraClusterTemplateSpec struct {
Template InfraClusterTemplateResource `json:"template"`
}
// +kubebuilder:object:root=true
// +kubebuilder:resource:path=infraclustertemplates,scope=Namespaced,categories=cluster-api,shortName=ict
// +kubebuilder:storageversion
// InfraClusterTemplate is the Schema for the infraclustertemplates API.
type InfraClusterTemplate struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec InfraClusterTemplateSpec `json:"spec,omitempty"`
}
type InfraClusterTemplateResource struct {
// Standard object's metadata.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
// +optional
ObjectMeta clusterv1.ObjectMeta `json:"metadata,omitempty"`
Spec InfraClusterSpec `json:"spec"`
}
The CRD name of the template must also have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
For any resource, also add list resources, e.g.
//+kubebuilder:object:root=true
// InfraClusterList contains a list of InfraClusters.
type InfraClusterList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []InfraCluster `json:"items"`
}
//+kubebuilder:object:root=true
// InfraClusterTemplateList contains a list of InfraClusterTemplates.
type InfraClusterTemplateList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []InfraClusterTemplate `json:"items"`
}
A cluster infrastructure provider must respond to changes to its “infrastructure cluster” resources. This process is
typically called reconciliation. The provider must watch for new, updated, and deleted resources and respond
accordingly.
The following diagram shows the typical logic for a cluster infrastructure provider:
If the resource is externally managed, exit the reconciliation
The ResourceIsNotExternallyManaged predicate can be used to prevent reconciling externally managed resources
If the resource does not have a Cluster owner, exit the reconciliation
The Cluster API Cluster reconciler populates this based on the value in the Cluster‘s spec.infrastructureRef
field.
Add the provider-specific finalizer, if needed
Reconcile provider-specific cluster infrastructure
If any errors are encountered, exit the reconciliation
If the provider created a load balancer for the control plane, record its hostname or IP in spec.controlPlaneEndpoint
Set status.ready to true
Set status.failureDomains based on available provider failure domains (optional)
Patch the resource to persist changes
If the resource has a Cluster owner
Perform deletion of provider-specific cluster infrastructure
If any errors are encountered, exit the reconciliation
Remove the provider-specific finalizer from the resource
Patch the resource to persist changes
A cluster infrastructure provider must have RBAC permissions for the types it defines. If you are using kubebuilder to
generate new API types, these permissions should be configured for you automatically. For example, the AWS provider has
the following configuration for its AWSCluster type:
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsclusters,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsclusters/status,verbs=get;update;patch
A cluster infrastructure provider may also need RBAC permissions for other types, such as Cluster. If you need
read-only access, you can limit the permissions to get, list, and watch. The AWS provider has the following
configuration for retrieving Cluster resources:
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=clusters;clusters/status,verbs=get;list;watch
The Cluster API controller for Cluster resources is configured with full read/write RBAC
permissions for all resources in the infrastructure.cluster.x-k8s.io API group. This group
represents all cluster infrastructure providers for SIG Cluster Lifecycle-sponsored provider
subprojects. If you are writing a provider not sponsored by the SIG, you must grant full read/write
RBAC permissions for the “infrastructure cluster” resource in your API group to the Cluster API
manager’s ServiceAccount. ClusterRoles can be granted using the aggregation label
cluster.x-k8s.io/aggregate-to-manager: "true". The following is an example ClusterRole for a
FooCluster resource:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: capi-foo-clusters
labels:
cluster.x-k8s.io/aggregate-to-manager: "true"
rules:
- apiGroups:
- infrastructure.foo.com
resources:
- fooclusters
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
Note, the write permissions allow the Cluster controller to set owner references and labels on the
“infrastructure cluster” resources; they are not used for general mutations of these resources.
A machine infrastructure provider is responsible for managing the lifecycle of provider-specific machine instances.
These may be physical or virtual instances, and they represent the infrastructure for Kubernetes nodes.
A machine infrastructure provider must define an API type for “infrastructure machine” resources. The type:
Must belong to an API group served by the Kubernetes apiserver
Must be implemented as a CustomResourceDefinition.
The CRD name must have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
Must be namespace-scoped
Must have the standard Kubernetes “type metadata” and “object metadata”
Must have a spec field with the following:
Required fields:
providerID (string): the identifier for the provider’s machine instance. This field is expected to match the value set by the KCM cloud provider in the Nodes.
The Machine controller bubbles it up to the Machine CR, and it’s used to find the matching Node.
Any other consumers can use the providerID as the source of truth to match both Machines and Nodes.
Optional fields:
failureDomain (string): the string identifier of the failure domain the instance is running in for the
purposes of backwards compatibility and migrating to the v1alpha3 FailureDomain support (where FailureDomain
is specified in Machine.Spec.FailureDomain). This field is meant to be temporary to aid in migration of data
that was previously defined on the provider type and providers will be expected to remove the field in the
next version that provides breaking API changes, favoring the value defined on Machine.Spec.FailureDomain
instead. If supporting conversions from previous types, the provider will need to support a conversion from
the provider-specific field that was previously used to the failureDomain field to support the automated
migration path.
Must have a status field with the following:
Required fields:
ready (boolean): indicates the provider-specific infrastructure has been provisioned and is ready
Optional fields:
failureReason (string): indicates there is a fatal problem reconciling the provider’s infrastructure;
meant to be suitable for programmatic interpretationfailureMessage (string): indicates there is a fatal problem reconciling the provider’s infrastructure;
meant to be a more descriptive value than failureReasonaddresses (MachineAddresses): a list of the host names, external IP addresses, internal IP addresses,
external DNS names, and/or internal DNS names for the provider’s machine instance. MachineAddress is
defined as:
type (string): one of Hostname, ExternalIP, InternalIP, ExternalDNS, InternalDNSaddress (string)
Should have a conditions field with the following:
A Ready condition to represent the overall operational state of the component. It can be based on the summary of more detailed conditions existing on the same object, e.g. instanceReady, SecurityGroupsReady conditions.
For a given InfraMachine resource, you should also add a corresponding InfraMachineTemplate resource:
// InfraMachineTemplateSpec defines the desired state of InfraMachineTemplate.
type InfraMachineTemplateSpec struct {
Template InfraMachineTemplateResource `json:"template"`
}
// +kubebuilder:object:root=true
// +kubebuilder:resource:path=inframachinetemplates,scope=Namespaced,categories=cluster-api,shortName=imt
// +kubebuilder:storageversion
// InfraMachineTemplate is the Schema for the inframachinetemplates API.
type InfraMachineTemplate struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec InfraMachineTemplateSpec `json:"spec,omitempty"`
}
type InfraMachineTemplateResource struct {
// Standard object's metadata.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
// +optional
ObjectMeta clusterv1.ObjectMeta `json:"metadata,omitempty"`
Spec InfraMachineSpec `json:"spec"`
}
The CRD name of the template must also have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
For any resource, also add list resources, e.g.
//+kubebuilder:object:root=true
// InfraMachineList contains a list of InfraMachines.
type InfraMachineList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []InfraCluster `json:"items"`
}
//+kubebuilder:object:root=true
// InfraMachineTemplateList contains a list of InfraMachineTemplates.
type InfraMachineTemplateList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []InfraClusterTemplate `json:"items"`
}
A machine infrastructure provider must respond to changes to its “infrastructure machine” resources. This process is
typically called reconciliation. The provider must watch for new, updated, and deleted resources and respond
accordingly.
The following diagram shows the typical logic for a machine infrastructure provider:
If the resource does not have a Machine owner, exit the reconciliation
The Cluster API Machine reconciler populates this based on the value in the Machines‘s
spec.infrastructureRef field
If the resource has status.failureReason or status.failureMessage set, exit the reconciliation
If the Cluster to which this resource belongs cannot be found, exit the reconciliation
Add the provider-specific finalizer, if needed
If the associated Cluster‘s status.infrastructureReady is false, exit the reconciliation
Note : This check should not be blocking any further delete reconciliation flows.Note : This check should only be performed after appropriate owner references (if any) are updated.
If the associated Machine‘s spec.bootstrap.dataSecretName is nil, exit the reconciliation
Reconcile provider-specific machine infrastructure
If any errors are encountered:
If they are terminal failures, set status.failureReason and status.failureMessage
Exit the reconciliation
If this is a control plane machine, register the instance with the provider’s control plane load balancer
(optional)
Set spec.providerID to the provider-specific identifier for the provider’s machine instance
Set status.ready to true
Set status.addresses to the provider-specific set of instance addresses (optional)
Set spec.failureDomain to the provider-specific failure domain the instance is running in (optional)
Patch the resource to persist changes
If the resource has a Machine owner
Perform deletion of provider-specific machine infrastructure
If this is a control plane machine, deregister the instance from the provider’s control plane load balancer
(optional)
If any errors are encountered, exit the reconciliation
Remove the provider-specific finalizer from the resource
Patch the resource to persist changes
A machine infrastructure provider must have RBAC permissions for the types it defines. If you are using kubebuilder to
generate new API types, these permissions should be configured for you automatically. For example, the AWS provider has
the following configuration for its AWSMachine type:
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsmachines,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=awsmachines/status,verbs=get;update;patch
A machine infrastructure provider may also need RBAC permissions for other types, such as Cluster and Machine. If
you need read-only access, you can limit the permissions to get, list, and watch. You can use the following
configuration for retrieving Cluster and Machine resources:
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=clusters;clusters/status,verbs=get;list;watch
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=machines;machines/status,verbs=get;list;watch
The Cluster API controller for Machine resources is configured with full read/write RBAC
permissions for all resources in the infrastructure.cluster.x-k8s.io API group. This group
represents all machine infrastructure providers for SIG Cluster Lifecycle-sponsored provider
subprojects. If you are writing a provider not sponsored by the SIG, you must grant full read/write
RBAC permissions for the “infrastructure machine” resource in your API group to the Cluster API
manager’s ServiceAccount. ClusterRoles can be granted using the aggregation label
cluster.x-k8s.io/aggregate-to-manager: "true". The following is an example ClusterRole for a
FooMachine resource:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: capi-foo-machines
labels:
cluster.x-k8s.io/aggregate-to-manager: "true"
rules:
- apiGroups:
- infrastructure.foo.com
resources:
- foomachines
verbs:
- create
- delete
- get
- list
- patch
- update
- watch
Note, the write permissions allow the Machine controller to set owner references and labels on the
“infrastructure machine” resources; they are not used for general mutations of these resources.
A bootstrap provider generates bootstrap data that is used to bootstrap a Kubernetes node.
For example, the Kubeadm bootstrap provider uses a cloud-init file for bootstrapping a node.
A bootstrap provider must define an API type for bootstrap resources. The type:
Must belong to an API group served by the Kubernetes apiserver
Must be implemented as a CustomResourceDefinition.
The CRD name must have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
Must be namespace-scoped
Must have the standard Kubernetes “type metadata” and “object metadata”
Should have a spec field containing fields relevant to the bootstrap provider
Must have a status field with the following:
Required fields:
ready (boolean): indicates the bootstrap data has been generated and is readydataSecretName (string): the name of the secret that stores the generated bootstrap data
Optional fields:
failureReason (string): indicates there is a fatal problem reconciling the bootstrap data;
meant to be suitable for programmatic interpretationfailureMessage (string): indicates there is a fatal problem reconciling the bootstrap data;
meant to be a more descriptive value than failureReason
Note: because the dataSecretName is part of status, this value must be deterministically recreatable from the data in the
Cluster, Machine, and/or bootstrap resource. If the name is randomly generated, it is not always possible to move
the resource and its associated secret from one management cluster to another.
For a given Bootstrap resource, you should also add a corresponding BootstrapTemplate resource:
// PhippyBootstrapConfigTemplateSpec defines the desired state of PhippyBootstrapConfigTemplate.
type PhippyBootstrapConfigTemplateSpec struct {
Template PhippyBootstrapTemplateResource `json:"template"`
}
// +kubebuilder:object:root=true
// +kubebuilder:resource:path=phippybootstrapconfigtemplates,scope=Namespaced,categories=cluster-api,shortName=pbct
// +kubebuilder:storageversion
// PhippyBootstrapConfigTemplate is the Schema for the Phippy Bootstrap API.
type PhippyBootstrapConfigTemplate struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec PhippyBootstrapConfigTemplateSpec `json:"spec,omitempty"`
}
type PhippyBootstrapConfigTemplateResource struct {
// Standard object's metadata.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
// +optional
ObjectMeta clusterv1.ObjectMeta `json:"metadata,omitempty"`
Spec PhippyBootstrapConfigSpec `json:"spec"`
}
The CRD name of the template must also have the format produced by sigs.k8s.io/cluster-api/util/contract.CalculateCRDName(Group, Kind).
For any resource, also add list resources, e.g.
//+kubebuilder:object:root=true
// PhippyBootstrapConfigList contains a list of Phippy Bootstrap Configurations.
type PhippyBootstrapConfigList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []PhippyBootstrapConfig `json:"items"`
}
//+kubebuilder:object:root=true
// PhippyBootstrapConfigTemplateList contains a list of PhippyBootstrapConfigTemplate.
type PhippyBootstrapConfigTemplateList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []PhippyBootstrapConfigTemplate `json:"items"`
}
The Secret containing bootstrap data must:
Use the API resource’s status.dataSecretName for its name
Have the label cluster.x-k8s.io/cluster-name set to the name of the cluster
Have a controller owner reference to the API resource
Have a single key, value, containing the bootstrap data
A bootstrap provider must respond to changes to its bootstrap resources. This process is
typically called reconciliation. The provider must watch for new, updated, and deleted resources and respond
accordingly.
The following diagram shows the typical logic for a bootstrap provider:
If the resource does not have a Machine owner, exit the reconciliation
The Cluster API Machine reconciler populates this based on the value in the Machine‘s spec.bootstrap.configRef
field.
If the resource has status.failureReason or status.failureMessage set, exit the reconciliation
If the Cluster to which this resource belongs cannot be found, exit the reconciliation
Deterministically generate the name for the bootstrap data secret
Try to retrieve the Secret with the name from the previous step
If it does not exist, generate bootstrap data and create the Secret
Set status.dataSecretName to the generated name
Set status.ready to true
Patch the resource to persist changes
A bootstrap provider’s bootstrap data must create /run/cluster-api/bootstrap-success.complete (or C:\run\cluster-api\bootstrap-success.complete for Windows machines) upon successful bootstrapping of a Kubernetes node. This allows infrastructure providers to detect and act on bootstrap failures.
A bootstrap provider can optionally taint worker nodes at creation with node.cluster.x-k8s.io/uninitialized:NoSchedule.
This taint is used to prevent workloads to be scheduled on Nodes before the node is initialized by Cluster API.
As of today the Node initialization consists of syncing labels from Machines to Nodes. Once the labels have been
initially synced the taint is removed form the Node.
A bootstrap provider must have RBAC permissions for the types it defines, as well as the bootstrap data Secret
resources it manages. If you are using kubebuilder to generate new API types, these permissions should be configured
for you automatically. For example, the Kubeadm bootstrap provider the following configuration for its KubeadmConfig
type:
// +kubebuilder:rbac:groups=bootstrap.cluster.x-k8s.io,resources=kubeadmconfigs;kubeadmconfigs/status,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups="",resources=secrets,verbs=get;list;watch;create;update;patch;delete
A bootstrap provider may also need RBAC permissions for other types, such as Cluster. If you need
read-only access, you can limit the permissions to get, list, and watch. The following
configuration can be used for retrieving Cluster resources:
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=clusters;clusters/status,verbs=get;list;watch
The Cluster API controller for Machine resources is configured with full read/write RBAC permissions for all resources
in the bootstrap.cluster.x-k8s.io API group. This group represents all bootstrap providers for SIG Cluster
Lifecycle-sponsored provider subprojects. If you are writing a provider not sponsored by the SIG, you must add new RBAC
permissions for the Cluster API manager-role role, granting it full read/write access to the bootstrap resource in
your API group.
Note, the write permissions allow the Machine controller to set owner references and labels on the bootstrap
resources; they are not used for general mutations of these resources.
In order to demonstrate how to develop a new Cluster API provider we will use
kubebuilder to create an example provider. For more information on kubebuilder
and CRDs in general we highly recommend reading the Kubebuilder Book .
Much of the information here was adapted directly from it.
This is an infrastructure provider - tasked with managing provider-specific resources for clusters and machines.
There are also bootstrap providers , which turn machines into Kubernetes nodes.
The naming convention for new Cluster API provider repositoriescluster-api-provider-${env}, where ${env} is a,
possibly short, name for the environment in question. For example
cluster-api-provider-gcp is an implementation for the Google Cloud Platform,
and cluster-api-provider-aws is one for Amazon Web Services. Note that an
environment may refer to a cloud, bare metal, virtual machines, or any other
infrastructure hosting Kubernetes. Finally, a single environment may include
more than one variant cluster-api-provider-aws may include both an implementation based on EC2 as
well as one based on their hosted EKS solution.
Because these names end up being so long, developers of Cluster API frequently refer to providers by acronyms.
Cluster API itself becomes CAPI , pronounced “Cappy.”
cluster-api-provider-aws is CAPA , pronounced “KappA.”
cluster-api-provider-gcp is CAPG , pronounced “Cap Gee,” and so on .
For the purposes of this guide we will create a provider for a
service named mailgun . Therefore the name of the repository will be
cluster-api-provider-mailgun.
Every Kubernetes resource has a Group , Version and Kind that uniquely
identifies it.
The resource Group is similar to package in a language.
It disambiguates different APIs that may happen to have identically named Kind s.
Groups often contain a domain name, such as k8s.io.
The domain for Cluster API resources is cluster.x-k8s.io, and infrastructure providers generally use infrastructure.cluster.x-k8s.io.
The resource Version defines the stability of the API and its backward compatibility guarantees.
Examples include v1alpha1, v1beta1, v1, etc. and are governed by the Kubernetes API Deprecation Policy .
Your provider should expect to abide by the same policies.
The resource Kind is the name of the objects we’ll be creating and modifying.
In this case it’s MailgunMachine and MailgunCluster.
For example, our cluster object will be:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha1
kind: MailgunCluster
kubebuilder generates most of the YAML you’ll need to deploy a container.
We just need to modify it to add our new secrets.
First, let’s add our secret as a patch to the manager yaml.
config/manager/manager_config.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: controller-manager
namespace: system
spec:
template:
spec:
containers:
- name: manager
env:
- name: MAILGUN_API_KEY
valueFrom:
secretKeyRef:
name: mailgun-secret
key: api_key
- name: MAILGUN_DOMAIN
valueFrom:
configMapKeyRef:
name: mailgun-config
key: mailgun_domain
- name: MAIL_RECIPIENT
valueFrom:
configMapKeyRef:
name: mailgun-config
key: mail_recipient
And then, we have to add that patch to config/kustomization.yaml
patchesStrategicMerge
- manager_image_patch.yaml
- manager_config.yaml
There’s many ways to manage configuration in production.
The convention many Cluster-API projects use is environment variables.
config/manager/configuration.yaml
---
apiVersion: v1
kind: Secret
metadata:
name: mailgun-config
namespace: system
type: Opaque
stringData:
api_key: ${MAILGUN_API_KEY}
---
apiVersion: v1
kind: ConfigMap
metadata:
name: mailgun-config
namespace: system
data:
mailgun_domain: ${MAILGUN_DOMAIN}
mail_recipient: ${MAILGUN_RECIPIENT}
And add this to config/manager/kustomization.yaml
resources:
- manager.yaml
- credentials.yaml
You can now (hopefully) generate your yaml!
kustomize build config/default
A tool like direnv can be used to help manage environment variables.
kustomize does not handle replacing those ${VARIABLES} with actual values.
For that, we use envsubst
You’ll need to have those environment variables (MAILGUN_API_KEY, MAILGUN_DOMAIN, MAILGUN_RECIPIENT) in your environment when you generate the final yaml file.
Change Makefile to include the call to envsubst:
- $(KUSTOMIZE) build config/default | kubectl apply -f -
+ $(KUSTOMIZE) build config/default | envsubst | kubectl apply -f -
To generate the manifests, call envsubst in line, like so:
kustomize build config/default | envsubst
Or to build and deploy the CRDs and manifests directly:
make install deploy
mkdir cluster-api-provider-mailgun
cd src/sigs.k8s.io/cluster-api-provider-mailgun
git init
You’ll then need to set up go modules
go mod init github.com/liztio/cluster-api-provider-mailgun
go: creating new go.mod: module github.com/liztio/cluster-api-provider-mailgun
kubebuilder init --domain cluster.x-k8s.io
kubebuilder init will create the basic repository layout, including a simple containerized manager.
It will also initialize the external go libraries that will be required to build your project.
Commit your changes so far:
git commit -m "Generate scaffolding."
Here you will be asked if you want to generate resources and controllers.
You’ll want both of them:
kubebuilder create api --group infrastructure --version v1alpha1 --kind MailgunCluster
kubebuilder create api --group infrastructure --version v1alpha1 --kind MailgunMachine
Create Resource under pkg/apis [y/n]?
y
Create Controller under pkg/controller [y/n]?
y
The latest API version of Cluster API and the version of your provider do not need to be in sync. Instead, prefer choosing a version that matches the stability of the provider API and its backward compatibility guarantees.
The status subresource lets Spec and Status requests for custom resources be addressed separately so requests don’t conflict with each other.
It also lets you split RBAC rules between Spec and Status. You will have to manually enable it in Kubebuilder .
Add the subresource:status annotation to your <provider>cluster_types.go <provider>machine_types.go
// +kubebuilder:subresource:status
// +kubebuilder:object:root=true
// MailgunCluster is the Schema for the mailgunclusters API
type MailgunCluster struct {
// +kubebuilder:subresource:status
// +kubebuilder:object:root=true
// MailgunMachine is the Schema for the mailgunmachines API
type MailgunMachine struct {
And regenerate the CRDs:
make manifests
The cluster API CRDs should be further customized:
git add .
git commit -m "Generate Cluster and Machine resources."
The API generated by Kubebuilder is just a shell. Your actual API will likely have more fields defined on it.
Kubernetes has a lot of conventions and requirements around API design.
The Kubebuilder docs have some helpful hints on how to design your types.
Let’s take a look at what was generated for us:
// MailgunClusterSpec defines the desired state of MailgunCluster
type MailgunClusterSpec struct {
// INSERT ADDITIONAL SPEC FIELDS - desired state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
// MailgunClusterStatus defines the observed state of MailgunCluster
type MailgunClusterStatus struct {
// INSERT ADDITIONAL STATUS FIELD - define observed state of cluster
// Important: Run "make" to regenerate code after modifying this file
}
Our API is based on Mailgun, so we’re going to have some email based fields:
type Priority string
const (
// PriorityUrgent means do this right away
PriorityUrgent = Priority("Urgent")
// PriorityUrgent means do this immediately
PriorityExtremelyUrgent = Priority("ExtremelyUrgent")
// PriorityBusinessCritical means you absolutely need to do this now
PriorityBusinessCritical = Priority("BusinessCritical")
)
// MailgunClusterSpec defines the desired state of MailgunCluster
type MailgunClusterSpec struct {
// Priority is how quickly you need this cluster
Priority Priority `json:"priority"`
// Request is where you ask extra nicely
Request string `json:"request"`
// Requester is the email of the person sending the request
Requester string `json:"requester"`
}
// MailgunClusterStatus defines the observed state of MailgunCluster
type MailgunClusterStatus struct {
// MessageID is set to the message ID from Mailgun when our message has been sent
MessageID *string `json:"response"`
}
As the deleted comments request, run make manager manifests to regenerate some of the generated data files afterwards.
git add .
git commit -m "Added cluster types"
To enable clients to encode and decode your API, your types must be able to be registered within a scheme .
By default, Kubebuilder will provide you with a scheme builder like:
import "sigs.k8s.io/controller-runtime/pkg/scheme"
var (
// SchemeBuilder is used to add go types to the GroupVersionKind scheme
SchemeBuilder = &scheme.Builder{GroupVersion: GroupVersion}
// AddToScheme adds the types in this group-version to the given scheme.
AddToScheme = SchemeBuilder.AddToScheme
)
and scheme registration that looks like:
func init() {
SchemeBuilder.Register(&Captain{}, &CaptainList{})
}
This pattern introduces a dependency on controller-runtime to your API types, which is discouraged for
API packages as it makes it more difficult for consumers of your API to import your API types.
In general, you should minimise the imports within the API folder of your package to allow your API types
to be imported cleanly into other projects.
To mitigate this, use the following schemebuilder pattern:
import "k8s.io/apimachinery/pkg/runtime"
var (
// schemeBuilder is used to add go types to the GroupVersionKind scheme.
schemeBuilder = runtime.NewSchemeBuilder(addKnownTypes)
// AddToScheme adds the types in this group-version to the given scheme.
AddToScheme = schemeBuilder.AddToScheme
objectTypes = []runtime.Object{}
)
func addKnownTypes(scheme *runtime.Scheme) error {
scheme.AddKnownTypes(GroupVersion, objectTypes...)
metav1.AddToGroupVersion(scheme, GroupVersion)
return nil
}
and register types as below:
func init() {
objectTypes = append(objectTypes, &Captain{}, &CaptainList{})
}
This pattern reduces the number of dependencies being introduced into the API package within your project.
Cluster API provides support for three kinds of webhooks: validating webhooks, defaulting webhook and conversion webhooks.
Validating webhooks are an implementation of a Kubernetes validating webhook . A validating webhook allows developers to test whether values supplied by users are valid. e.g. the Cluster webhook ensures the Infrastructure reference supplied at the Cluster’s .spec.infrastructureRef is in the same namespace as the Cluster itself and rejects the object creation or update if not.
Validating webhooks implemented for a InfrastructureMachineTemplate or BootstrapConfigTemplate resource
are required to not block due to immutability checks when the controller for managed
topology and ClusterClass does Server Side Apply dry-run requests.
Server Side Apply implementation in ClusterClass and managed topologies requires to dry-run changes on templates.
If infrastructure or bootstrap providers have implemented immutability checks in their InfrastructureMachineTemplate
or BootstrapConfigTemplate webhooks, it is required to implement the following changes in order to prevent dry-run
to return errors. The implementation requires sigs.k8s.io/controller-runtime in version >= v0.12.3.
In order to do so it is required to use a controller runtime CustomValidator.
This will allow to skip the immutability check only when the topology controller is dry running while preserving the
validation behavior for all other cases.
See the DockerMachineTemplate webhook as a reference for a compatible implementation.
Defaulting webhooks are an implementation of a Kubernetes mutating webhook . A defaulting webhook allows developers to set default values for a type before they are placed in the Kubernetes data store. e.g. the Cluster webhook will set the Infrastructure reference namespace to equal the Cluster namespace if .spec.infrastructureRef.namespace is empty.
Conversion webhooks are what allow Cluster API to work with multiple API types without requiring different versions. It does this by converting the incoming version to a Hub version which is used internally by the controllers. To read more about conversion see the Kubebuilder documentation
For a walkthrough on implementing conversion webhooks see the video in the Developer Guide
The webhooks in Cluster API are offered through tools in Controller Runtime and Kubebuilder. The webhooks implement interfaces defined in Controller Runtime, while generation of manifests can be done using Kubebuilder.
For information on how to create webhooks refer to the Kubebuilder book .
Webhook manifests are generated using Kubebuilder in Cluster API. This is done by adding tags to the webhook implementation in the codebase. Below, for example, are the tags on the the Cluster webhook :
// +kubebuilder:webhook:verbs=create;update;delete,path=/validate-cluster-x-k8s-io-v1beta1-cluster,mutating=false,failurePolicy=fail,matchPolicy=Equivalent,groups=cluster.x-k8s.io,resources=clusters,versions=v1beta1,name=validation.cluster.cluster.x-k8s.io,sideEffects=None,admissionReviewVersions=v1;v1beta1
// +kubebuilder:webhook:verbs=create;update,path=/mutate-cluster-x-k8s-io-v1beta1-cluster,mutating=true,failurePolicy=fail,matchPolicy=Equivalent,groups=cluster.x-k8s.io,resources=clusters,versions=v1beta1,name=default.cluster.cluster.x-k8s.io,sideEffects=None,admissionReviewVersions=v1;v1beta1
// Cluster implements a validating and defaulting webhook for Cluster.
type Cluster struct {
Client client.Reader
}
A detailed guide on the purpose of each of these tags is here .
From the kubebuilder book :
Controllers are the core of Kubernetes, and of any operator.
It’s a controller’s job to ensure that, for any given object, the actual state of the world (both the cluster state, and potentially external state like running containers for Kubelet or loadbalancers for a cloud provider) matches the desired state in the object.
Each controller focuses on one root Kind, but may interact with other Kinds.
We call this process reconciling.
Right now, we can create objects in our API but we won’t do anything about it. Let’s fix that.
Kubebuilder has created our first controller in controllers/mailguncluster_controller.go. Let’s take a look at what got generated:
// MailgunClusterReconciler reconciles a MailgunCluster object
type MailgunClusterReconciler struct {
client.Client
Log logr.Logger
}
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=mailgunclusters,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=mailgunclusters/status,verbs=get;update;patch
func (r *MailgunClusterReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
_ = context.Background()
_ = r.Log.WithValues("mailguncluster", req.NamespacedName)
// your logic here
return ctrl.Result{}, nil
}
The // +kubebuilder... lines tell kubebuilder to generate RBAC roles so the manager we’re writing can access its own managed resources. These should already exist in controllers/mailguncluster_controller.go:
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=mailgunclusters,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=infrastructure.cluster.x-k8s.io,resources=mailgunclusters/status,verbs=get;update;patch
We also need to add rules that will let it retrieve (but not modify) Cluster API objects.
So we’ll add another annotation for that, right below the other lines:
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=clusters;clusters/status,verbs=get;list;watch
Make sure to add this annotation to MailgunClusterReconciler.
For MailgunMachineReconciler, access to Cluster API Machine object is needed, so you must add this annotation in controllers/mailgunmachine_controller.go:
// +kubebuilder:rbac:groups=cluster.x-k8s.io,resources=machines;machines/status,verbs=get;list;watch
Regenerate the RBAC roles after you are done:
make manifests
Let’s focus on that struct first.
First, a word of warning: no guarantees are made about parallel access, both on one machine or multiple machines.
That means you should not store any important state in memory: if you need it, write it into a Kubernetes object and store it.
We’re going to be sending mail, so let’s add a few extra fields:
// MailgunClusterReconciler reconciles a MailgunCluster object
type MailgunClusterReconciler struct {
client.Client
Log logr.Logger
Mailgun mailgun.Mailgun
Recipient string
}
Now it’s time for our Reconcile function.
Reconcile is only passed a name, not an object, so let’s retrieve ours.
Here’s a naive example:
func (r *MailgunClusterReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
ctx := context.Background()
_ = r.Log.WithValues("mailguncluster", req.NamespacedName)
var cluster infrav1.MailgunCluster
if err := r.Get(ctx, req.NamespacedName, &cluster); err != nil {
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}
By returning an error, we request that our controller will get Reconcile() called again.
That may not always be what we want - what if the object’s been deleted? So let’s check that:
var cluster infrav1.MailgunCluster
if err := r.Get(ctx, req.NamespacedName, &cluster); err != nil {
// import apierrors "k8s.io/apimachinery/pkg/api/errors"
if apierrors.IsNotFound(err) {
return ctrl.Result{}, nil
}
return ctrl.Result{}, err
}
Now, if this were any old kubebuilder project we’d be done, but in our case we have one more object to retrieve.
Cluster API splits a cluster into two objects: the Cluster defined by Cluster API itselfprovides a helper for us .
cluster, err := util.GetOwnerCluster(ctx, r.Client, &mg)
if err != nil {
return ctrl.Result{}, err
}
At the time this document was written, kubebuilder pulls client-go version 1.14.1 into go.mod (it looks like k8s.io/client-go v11.0.1-0.20190409021438-1a26190bd76a+incompatible).
If you encounter an error when compiling like:
../pkg/mod/k8s.io/client-go@v11.0.1-0.20190409021438-1a26190bd76a+incompatible/rest/request.go:598:31: not enough arguments in call to watch.NewStreamWatcher
have (*versioned.Decoder)
want (watch.Decoder, watch.Reporter)`
You may need to bump client-go. At time of writing, that means 1.15, which looks like: k8s.io/client-go v11.0.1-0.20190409021438-1a26190bd76a+incompatible.
More Documentation: The Kubebuilder Book has some excellent documentation on many things, including how to write good controllers!
Now that we have our objects, it’s time to do something with them!
This is where your provider really comes into its own.
In our case, let’s try sending some mail:
subject := fmt.Sprintf("[%s] New Cluster %s requested", mgCluster.Spec.Priority, cluster.Name)
body := fmt.Sprint("Hello! One cluster please.\n\n%s\n", mgCluster.Spec.Request)
msg := mailgun.NewMessage(mgCluster.Spec.Requester, subject, body, r.Recipient)
_, _, err = r.Mailgun.Send(msg)
if err != nil {
return ctrl.Result{}, err
}
But wait, this isn’t quite right.
Reconcile() gets called periodically for updates, and any time any updates are made.
That would mean we’re potentially sending an email every few minutes!
This is an important thing about controllers: they need to be idempotent. This means a controller must be able to repeat actions on the same inputs without changing the effect of those actions.
So in our case, we’ll store the result of sending a message, and then check to see if we’ve sent one before.
if mgCluster.Status.MessageID != nil {
// We already sent a message, so skip reconciliation
return ctrl.Result{}, nil
}
subject := fmt.Sprintf("[%s] New Cluster %s requested", mgCluster.Spec.Priority, cluster.Name)
body := fmt.Sprintf("Hello! One cluster please.\n\n%s\n", mgCluster.Spec.Request)
msg := mailgun.NewMessage(mgCluster.Spec.Requester, subject, body, r.Recipient)
_, msgID, err := r.Mailgun.Send(msg)
if err != nil {
return ctrl.Result{}, err
}
// patch from sigs.k8s.io/cluster-api/util/patch
helper, err := patch.NewHelper(&mgCluster, r.Client)
if err != nil {
return ctrl.Result{}, err
}
mgCluster.Status.MessageID = &msgID
if err := helper.Patch(ctx, &mgCluster); err != nil {
return ctrl.Result{}, errors.Wrapf(err, "couldn't patch cluster %q", mgCluster.Name)
}
return ctrl.Result{}, nil
Usually, the Status field should only be values that can be computed from existing state .
Things like whether a machine is running can be retrieved from an API, and cluster status can be queried by a healthcheck.
The message ID is ephemeral, so it should properly go in the Spec part of the object.
Anything that can’t be recreated, either with some sort of deterministic generation method or by querying/observing actual state, needs to be in Spec.
This is to support proper disaster recovery of resources.
If you have a backup of your cluster and you want to restore it, Kubernetes doesn’t let you restore both spec & status together.
We use the MessageID as a Status here to illustrate how one might issue status updates in a real application.
If you added fields to your reconciler, you’ll need to update main.go.
Right now, it probably looks like this:
if err = (&controllers.MailgunClusterReconciler{
Client: mgr.GetClient(),
Log: ctrl.Log.WithName("controllers").WithName("MailgunCluster"),
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "MailgunCluster")
os.Exit(1)
}
Let’s add our configuration.
We’re going to use environment variables for this:
domain := os.Getenv("MAILGUN_DOMAIN")
if domain == "" {
setupLog.Info("missing required env MAILGUN_DOMAIN")
os.Exit(1)
}
apiKey := os.Getenv("MAILGUN_API_KEY")
if apiKey == "" {
setupLog.Info("missing required env MAILGUN_API_KEY")
os.Exit(1)
}
recipient := os.Getenv("MAIL_RECIPIENT")
if recipient == "" {
setupLog.Info("missing required env MAIL_RECIPIENT")
os.Exit(1)
}
mg := mailgun.NewMailgun(domain, apiKey)
if err = (&controllers.MailgunClusterReconciler{
Client: mgr.GetClient(),
Log: ctrl.Log.WithName("controllers").WithName("MailgunCluster"),
Mailgun: mg,
Recipient: recipient,
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "MailgunCluster")
os.Exit(1)
}
If you have some other state, you’ll want to initialize it here!
The patch in config/manager/manager_image_patch.yaml will be applied to the manager pod.
Right now there is a placeholder IMAGE_URL, which you will need to change to your actual image.
It’s likely that you will want one location and tag for release development, and another during development.
The approach most Cluster API projects is using a Makefile that uses sed to replace the image URL on demand during development.
Cluster API uses cert-manager to manage the certificates it needs for its webhooks.
Before you apply Cluster API’s yaml, you should install cert-manager
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/<version>/cert-manager.yaml
Before you can deploy the infrastructure controller, you’ll need to deploy Cluster API itself to the management cluster.
You can use a precompiled manifest from the release page , run clusterctl init, or clone cluster-apikustomize:
cd cluster-api
make envsubst
kustomize build config/default | ./hack/tools/bin/envsubst | kubectl apply -f -
Check the status of the manager to make sure it’s running properly:
kubectl describe -n capi-system pod | grep -A 5 Conditions
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
In this guide, we are building an infrastructure provider . We must tell cluster-api and its developer tooling which type of provider it is. Edit config/default/kustomization.yaml and add the following common label. The prefix infrastructure- is used to detect the provider type.
commonLabels:
cluster.x-k8s.io/provider: infrastructure-mailgun
Now you can apply your provider as well:
cd cluster-api-provider-mailgun
# Install CRD and controller to current kubectl context
make install deploy
kubectl describe -n cluster-api-provider-mailgun-system pod | grep -A 5 Conditions
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Cluster API development requires a lot of iteration, and the “build, tag, push, update deployment” workflow can be very tedious.
Tilt makes this process much simpler by watching for updates, then automatically building and deploying them.
See Developing Cluster API with Tilt on all details how to develop both Cluster API and your provider at the same time. In short, you need to perform these steps for a basic Tilt-based development environment:
Create file tilt-provider.yaml in your provider directory:
name: mailgun
config:
image: controller:latest # change to remote image name if desired
label: CAPM
live_reload_deps: ["main.go", "go.mod", "go.sum", "api", "controllers", "pkg"]
Create file tilt-settings.yaml in the cluster-api directory:
default_registry: "" # change if you use a remote image registry
provider_repos:
# This refers to your provider directory and loads settings
# from `tilt-provider.yaml`
- ../cluster-api-provider-mailgun
enable_providers:
- mailgun
Create a kind cluster. By default, Tiltfile assumes the kind cluster is named capi-test.
kind create cluster --name capi-test
# If you want a more sophisticated setup of kind cluster + image registry, try:
# ---
# cd cluster-api
# hack/kind-install-for-capd.sh
Run tilt up in the cluster-api folder
You can then use Tilt to watch the container logs.
On any changed file in the listed places (live_reload_deps and those watched inside cluster-api repo), Tilt will build and deploy again. In the regular case of a changed file, only your controller’s binary gets rebuilt, copied into the running container, and the process restarted. This is much faster than a full re-build and re-deployment of a Docker image and restart of the Kubernetes pod.
You best watch the Kubernetes pods with something like k9s -A or watch kubectl get pod -A. Particularly in case your provider implementation crashes, Tilt has no chance to deploy any code changes into the container since it might be crash-looping indefinitely. In such a case – which you will notice in the log output – terminate Tilt (hit Ctrl+C) and start it again to deploy the Docker image from scratch.
Let’s try our cluster out. We’ll make some simple YAML:
apiVersion: cluster.x-k8s.io/v1beta1
kind: Cluster
metadata:
name: hello-mailgun
spec:
clusterNetwork:
pods:
cidrBlocks: ["192.168.0.0/16"]
infrastructureRef:
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha1
kind: MailgunCluster
name: hello-mailgun
---
apiVersion: infrastructure.cluster.x-k8s.io/v1alpha1
kind: MailgunCluster
metadata:
name: hello-mailgun
spec:
priority: "ExtremelyUrgent"
request: "Please make me a cluster, with sugar on top?"
requester: "cluster-admin@example.com"
We apply it as normal with kubectl apply -f <filename>.yaml.
If all goes well, you should be getting an email to the address you configured when you set up your management cluster:
Obviously, this is only the first step.
We need to implement our Machine object too, and log events, handle updates, and many more things.
Hopefully you feel empowered to go out and create your own provider now.
The world is your Kubernetes-based oyster!
There are many resources that appear in the Cluster API. In this section, we use diagrams to illustrate the most common relationships between Cluster API resources.
The straight lines represent “management”. For example, “MachineSet manages Machines”. The dotted line represents “reference”. For example, “Machine’s spec.infrastructureRef field references FooMachine”.
The direction of the arrows indicates the direction of “management” or “reference”. For example, “the relationship between MachineSet and Machine is management from MachineSet to Machine”, so the arrow points from MachineSet to Machine.
If you’ve run the Quick Start before ensure that you’ve cleaned up all resources before trying it again. Check docker ps to ensure there are no running containers left before beginning the Quick Start.
This guide assumes you’ve completed the apply the workload cluster section of the Quick Start using Docker.
When running clusterctl describe cluster capi-quickstart to verify the created resources, we expect the output to be similar to this (note: this is before installing the Calico CNI ).
NAME READY SEVERITY REASON SINCE MESSAGE
Cluster/capi-quickstart True 46m
├─ClusterInfrastructure - DockerCluster/capi-quickstart-94r9d True 48m
├─ControlPlane - KubeadmControlPlane/capi-quickstart-6487w True 46m
│ └─3 Machines... True 47m See capi-quickstart-6487w-d5lkp, capi-quickstart-6487w-mpmkq, ...
└─Workers
└─MachineDeployment/capi-quickstart-md-0-d6dn6 False Warning WaitingForAvailableMachines 48m Minimum availability requires 3 replicas, current 0 available
└─3 Machines... True 47m See capi-quickstart-md-0-d6dn6-584ff97cb7-kr7bj, capi-quickstart-md-0-d6dn6-584ff97cb7-s6cbf, ...
Machines should be started, but Workers are not because Calico isn’t installed yet. You should be able to see the containers running with docker ps --all and they should not be restarting.
If you notice Machines are failing to start/restarting your output might look similar to this:
clusterctl describe cluster capi-quickstart
NAME READY SEVERITY REASON SINCE MESSAGE
Cluster/capi-quickstart False Warning ScalingUp 57s Scaling up control plane to 3 replicas (actual 2)
├─ClusterInfrastructure - DockerCluster/capi-quickstart-n5w87 True 110s
├─ControlPlane - KubeadmControlPlane/capi-quickstart-6587k False Warning ScalingUp 57s Scaling up control plane to 3 replicas (actual 2)
│ ├─Machine/capi-quickstart-6587k-fgc6m True 81s
│ └─Machine/capi-quickstart-6587k-xtvnz False Warning BootstrapFailed 52s 1 of 2 completed
└─Workers
└─MachineDeployment/capi-quickstart-md-0-5whtj False Warning WaitingForAvailableMachines 110s Minimum availability requires 3 replicas, current 0 available
└─3 Machines... False Info Bootstrapping 77s See capi-quickstart-md-0-5whtj-5d8c9746c9-f8sw8, capi-quickstart-md-0-5whtj-5d8c9746c9-hzxc2, ...
In the example above we can see that the Machine capi-quickstart-6587k-xtvnz has failed to start. The reason provided is BootstrapFailed.
To investigate why a machine fails to start you can inspect the conditions of the objects using clusterctl describe --show-conditions all cluster capi-quickstart. You can get more detailed information about the status of the machines using kubectl describe machines.
To inspect the underlying infrastructure - in this case Docker containers acting as Machines - you can access the logs using docker logs <MACHINE-NAME>. For example:
docker logs capi-quickstart-6587k-xtvnz
(...)
Failed to create control group inotify object: Too many open files
Failed to allocate manager object: Too many open files
[!!!!!!] Failed to allocate manager object.
Exiting PID 1...
To resolve this specific error please read Cluster API with Docker - “too many open files” .
Failures during Node bootstrapping can have a lot of different causes. For example, Cluster API resources might be
misconfigured or there might be problems with the network. The following steps describe how bootstrap failures can
be troubleshooted systematically.
Access the Node via ssh.
Take a look at cloud-init logs via less /var/log/cloud-init-output.log or journalctl -u cloud-init --since "1 day ago".
(Note: cloud-init persists logs of the commands it executes (like kubeadm) only after they have returned.)
It might also be helpful to take a look at journalctl --since "1 day ago".
If you see that kubeadm times out waiting for the static Pods to come up, take a look at:
containerd: crictl ps -a, crictl logs, journalctl -u containerd
Kubelet: journalctl -u kubelet --since "1 day ago"
(Note: it might be helpful to increase the Kubelet log level by e.g. setting --v=8 via
systemctl edit --full kubelet && systemctl restart kubelet)
If Node bootstrapping consistently fails and the kubeadm logs are not verbose enough, the kubeadm verbosity
can be increased via KubeadmConfigSpec.Verbosity.
Self-assigning Node labels such as node-role.kubernetes.io using the kubelet --node-labels flag
(see kubeletExtraArgs in the CABPK examples )
is not possible due to a security measure imposed by the
NodeRestriction admission controller
Assigning such labels to Nodes must be done after the bootstrap process has completed:
kubectl label nodes <name> node-role.kubernetes.io/worker=""
For convenience, here is an example one-liner to do this post installation
# Kubernetes 1.19 (kubeadm 1.19 sets only the node-role.kubernetes.io/master label)
kubectl get nodes --no-headers -l '!node-role.kubernetes.io/master' -o jsonpath='{range .items[*]}{.metadata.name}{"\n"}' | xargs -I{} kubectl label node {} node-role.kubernetes.io/worker=''
# Kubernetes >= 1.20 (kubeadm >= 1.20 sets the node-role.kubernetes.io/control-plane label)
kubectl get nodes --no-headers -l '!node-role.kubernetes.io/control-plane' -o jsonpath='{range .items[*]}{.metadata.name}{"\n"}' | xargs -I{} kubectl label node {} node-role.kubernetes.io/worker=''
When provisioning workload clusters using Cluster API with the Docker infrastructure provider,
provisioning might be stuck:
if there are stopped containers on your machine from previous runs. Clean unused containers with docker rm -f .
if the Docker space on your disk is being exhausted
When creating many nodes using Cluster API and Docker infrastructure, either by creating large Clusters or a number of small Clusters, the OS may run into inotify limits which prevent new nodes from being provisioned.
If the error Failed to create inotify object: Too many open files is present in the logs of the Docker Infrastructure provider this limit is being hit.
On Linux this issue can be resolved by increasing the inotify watch limits with:
sysctl fs.inotify.max_user_watches=1048576
sysctl fs.inotify.max_user_instances=8192
Newly created clusters should be able to take advantage of the increased limits.
This error was also observed in Docker Desktop 4.3 and 4.4 on MacOS. It can be resolved by updating to Docker Desktop for Mac 4.5 or using a version lower than 4.3.
The upstream issue for this error is closed as of the release of Docker 4.5.0
Note: The below workaround is not recommended unless upgrade or downgrade cannot be performed.
If using a version of Docker Desktop for Mac 4.3 or 4.4, the following workaround can be used:
Increase the maximum inotify file watch settings in the Docker Desktop VM:
Enter the Docker Desktop VM
nc -U ~/Library/Containers/com.docker.docker/Data/debug-shell.sock
Increase the inotify limits using sysctl
sysctl fs.inotify.max_user_watches=1048576
sysctl fs.inotify.max_user_instances=8192
Exit the Docker Desktop VM
exit
When using older versions of Cluster API 0.4 and 1.0 releases - 0.4.6, 1.0.3 and older respectively - Cert Manager may not be downloadable due to a change in the repository location. This will cause clusterctl init to fail with the error:
clusterctl init --infrastructure docker
Fetching providers
Installing cert-manager Version="v1.11.0"
Error: action failed after 10 attempts: failed to get cert-manager object /, Kind=, /: Object 'Kind' is missing in 'unstructured object has no kind'
This error was fixed in more recent Cluster API releases on the 0.4 and 1.0 release branches. The simplest way to resolve the issue is to upgrade to a newer version of Cluster API for a given release. For who need to continue using an older release it is possible to override the repository used by clusterctl init in the clusterctl config file. The default location of this file is in $XDG_CONFIG_HOME/cluster-api/clusterctl.yaml.
To do so add the following to the file:
cert-manager:
url: "https://github.com/cert-manager/cert-manager/releases/latest/cert-manager.yaml"
Alternatively a Cert Manager yaml file can be placed in the clusterctl overrides layer which is by default in $XDG_CONFIG_HOME/cluster-api/overrides. A Cert Manager yaml file can be placed at e.g. $XDG_CONFIG_HOME/cluster-api/overrides/cert-manager/v1.11.0/cert-manager.yaml
More information on the clusterctl config file can be found at its page in the book
Upgrading Cert Manager may fail due to a breaking change introduced in Cert Manager release v1.6.
An upgrade using clusterctl is affected when:
using clusterctl in version v1.1.4 or a more recent version.
Cert Manager lower than version v1.0.0 did run in the management cluster (which was shipped in Cluster API until including v0.3.14).
This will cause clusterctl upgrade apply to fail with the error:
clusterctl upgrade apply
Checking cert-manager version...
Deleting cert-manager Version="v1.5.3"
Installing cert-manager Version="v1.7.2"
Error: action failed after 10 attempts: failed to update cert-manager component apiextensions.k8s.io/v1, Kind=CustomResourceDefinition, /certificaterequests.cert-manager.io: CustomResourceDefinition.apiextensions.k8s.io "certificaterequests.cert-manager.io" is invalid: status.storedVersions[0]: Invalid value: "v1alpha2": must appear in spec.versions
The Cert Manager maintainers provide documentation to migrate the deprecated API Resources to the new storage versions to mitigate the issue.
More information about the change in Cert Manager can be found at their upgrade notes from v1.5 to v1.6 .
clusterctl allows users to configure image overrides via the clusterctl config file.
However, when the image override is pinning a provider image to a specific version, it could happen that this
conflicts with clusterctl behavior of picking the latest version of a provider.
E.g., if you are pinning KCP images to version v1.0.2 but then clusterctl init fetches yamls for version v1.1.0 or greater KCP will
fail to start with the following error:
invalid argument "ClusterTopology=false,KubeadmBootstrapFormatIgnition=false" for "--feature-gates" flag: unrecognized feature gate: KubeadmBootstrapFormatIgnition
In order to solve this problem you should specify the version of the provider you are installing by appending a
version tag to the provider name:
clusterctl init -b kubeadm:v1.0.2 -c kubeadm:v1.0.2 --core cluster-api:v1.0.2 -i docker:v1.0.2
Even if slightly verbose, pinning the version provides a better control over what is installed, as usually
required in an enterprise environment, especially if you rely on an internal repository with a separated
software supply chain or a custom versioning schema.
As documented in #6320 managed topologies
assumes a slice to be either authored from templates or by the users/the infrastructure controllers.
In cases the slice is instead co-authored (templates provide some info, the infrastructure controller
fills in other info) this can lead to infinite reconcile.
A solution to this problem is being investigated, but in the meantime you should avoid co-authored slices.
This section contains various resources that define the Cluster API project.
Cluster API currently exposes the following APIs:
A | B | C | D | E | H | I | K | L | M | N | O | P | R | S | T | W
Services beyond the fundamental components of Kubernetes.
Core Add-ons : Addons that are required to deploy a Kubernetes-conformant cluster: DNS, kube-proxy, CNI.Additional Add-ons : Addons that are not required for a Kubernetes-conformant cluster (e.g. metrics/Heapster, Dashboard).
The process of turning a server into a Kubernetes node. This may involve assembling data to provide when creating the server that backs the Machine, as well as runtime configuration of the software running on that server.
A temporary cluster that is used to provision a Target Management cluster.
Refers to a provider that implements a solution for the bootstrap process.
Bootstrap provider’s interaction with Cluster API is based on what is defined in the Cluster API contract .
See CABPK .
Cluster API Enhancement Proposal - patterned after KEP . See template
Core Cluster API
Cluster API Provider AWS
Cluster API Bootstrap Provider Kubeadm
Cluster API Bootstrap Provider Oracle Cloud Native Environment (OCNE)
Cluster API Control Plane Provider Oracle Cloud Native Environment (OCNE)
Cluster API Provider CloudStack
Cluster API Provider Docker
Cluster API Provider DigitalOcean
Cluster API Google Cloud Provider
Cluster API Provider Hetzner
Cluster API Provider Hivelocity
Cluster API Provider IBM Cloud
Cluster API Operator
Cluster API Provider Akamai (Linode)
Cluster API Provider Metal3
Cluster API Provider Nested
Cluster API Provider Nutanix
Cluster API Provider KubeKey
Cluster API Provider Kubevirt
Cluster API Provider OpenStack
Cluster API Provider Outscale
Cluster API Provider Oracle Cloud Infrastructure (OCI)
Cluster API Provider Tinkerbell
Cluster API Provider vSphere
Cluster API Provider vcluster
Cluster API Provider VMware Cloud Director
Cluster API Provider Azure
Cluster API IPAM Provider In Cluster
Or Cloud service provider
Refers to an information technology (IT) company that provides computing resources (e.g. AWS, Azure, Google, etc.).
A full Kubernetes deployment. See Management Cluster and Workload Cluster.
A collection of templates that define a topology (control plane and workers) to be used to continuously reconcile one or more Clusters.
See ClusterClass
Or Cluster API project
The Cluster API sub-project of the SIG-cluster-lifecycle. It is also used to refer to the software components, APIs, and community that produce them.
See core provider
The Cluster API execution model, a set of controllers cooperating in managing the Kubernetes cluster lifecycle.
or Kubernetes Cluster Infrastructure
Defines the infrastructure that supports a Kubernetes cluster , like e.g. VPC, security groups, load balancers, etc. Please note that in the context of managed Kubernetes some of those components are going to be provided by the corresponding abstraction for a specific Cloud provider (EKS, OKE, AKS etc), and thus Cluster API should not take care of managing a subset or all those components.
Or Cluster API contract
Defines a set of rules a provider is expected to comply with in order to interact with Cluster API.
Those rules can be in the form of CustomResourceDefinition (CRD) fields and/or expected behaviors to be implemented.
The set of Kubernetes services that form the basis of a cluster. See also https://kubernetes.io/docs/concepts/#kubernetes-control-plane There are two variants:
Self-provisioned : A Kubernetes control plane consisting of pods or machines wholly managed by a single Cluster API deployment.External or Managed : A control plane offered and controlled by some system other than Cluster API (e.g., GKE, AKS, EKS, IKS).
Refers to a provider that implements a solution for the management of a Kubernetes control plane .
Control plane provider’s interaction with Cluster API is based on what is defined in the Cluster API contract .
See KCP .
Refers to a provider that implements Cluster API core controllers; if you
consider that the first project that must be deployed in a management Cluster is Cluster API itself, it should be clear why
the Cluster API project is also referred to as the core provider.
See CAPI .
A feature implementation offered as part of the Cluster API project and maintained by the CAPI core team; For example
KCP is a default implementation for a control plane provider .
Patch generated by an external component using Runtime SDK . Alternative to inline patch .
A runtime extension that implements a topology mutation hook .
The ability to add more machines based on policy and well-defined metrics. For example, add a machine to a cluster when CPU load average > (X) for a period of time (Y).
see Server
Refers to a provider that implements provisioning of infrastructure/computational resources required by
the Cluster or by Machines (e.g. VMs, networking, etc.).
Infrastructure provider’s interaction with Cluster API is based on what is defined in the Cluster API contract .
Clouds infrastructure providers include AWS, Azure, or Google; while VMware, MAAS, or metal3.io can be defined as bare metal providers.
When there is more than one way to obtain resources from the same infrastructure provider (e.g. EC2 vs. EKS in AWS) each way is referred to as a variant.
For a complete list of providers see Provider Implementations .
A patch defined inline in a ClusterClass . An alternative to an external patch .
Fields which changes would only impact Kubernetes objects or/and controller behaviour
but they won’t mutate in any way provider infrastructure nor the software running on it. In-place mutable fields
are propagated in place by CAPI controllers to avoid the more elaborated mechanics of a replace rollout.
They include metadata, MinReadySeconds, NodeDrainTimeout, NodeVolumeDetachTimeout and NodeDeletionTimeout but are
not limited to be expanded in the future.
see Server
A resource that does not mutate. In Kubernetes we often state the instance of a running pod is immutable or does not change once it is run. In order to make a change, a new pod is run. In the context of Cluster API we often refer to a running instance of a Machine as being immutable, from a Cluster API perspective.
Refers to a provider that allows Cluster API to interact with IPAM solutions.
IPAM provider’s interaction with Cluster API is based on the IPAddressClaim and IPAddress API types.
Or Kubernetes-compliant
A cluster that passes the Kubernetes conformance tests.
Refers to the main Kubernetes git repository or the main Kubernetes project.
Kubeadm Control plane Provider
A Runtime Hook that allows external components to interact with the lifecycle of a Cluster.
See Implementing Lifecycle Hooks
Or Machine Resource
The Custom Resource for Kubernetes that represents a request to have a place to run kubelet.
See also: Server
Perform create, scale, upgrade, or destroy operations on the cluster.
Managed Kubernetes refers to any Kubernetes cluster provisioning and maintenance abstraction, usually exposed as an API, that is natively available in a Cloud provider. For example: EKS , OKE , AKS , GKE , IBM Cloud Kubernetes Service , DOKS , and many more throughout the Kubernetes Cloud Native ecosystem.
See Topology
The cluster where one or more Infrastructure Providers run, and where resources (e.g. Machines) are stored. Typically referred to when you are provisioning multiple workload clusters.
Multi tenancy in Cluster API defines the capability of an infrastructure provider to manage different credentials, each
one of them corresponding to an infrastructure tenant.
Please note that up until v1alpha3 this concept had a different meaning, referring to the capability to run multiple
instances of the same provider, each one with its own credentials; starting from v1alpha4 we are disambiguating the two concepts.
See Multi-tenancy and Support multiple instances .
A node pool is a group of nodes within a cluster that all have the same configuration.
Or OS
A generically understood combination of a kernel and system-level userspace interface, such as Linux or Windows, as opposed to a particular distribution.
A set of instructions describing modifications to a Kubernetes object. Examples include JSON Patch and JSON Merge Patch.
Pivot is a process for moving the provider components and declared cluster-api resources from a Source Management cluster to a Target Management cluster.
The pivot process is also used for deleting a management cluster and could also be used during an upgrade of the management cluster.
Or Cluster API provider
This term was originally used as abbreviation for Infrastructure provider , but currently it is used
to refer to any project that can be deployed and provides functionality to the Cluster API management Cluster.
See Bootstrap provider , Control plane provider , Core provider ,
Infrastructure provider , IPAM provider Runtime extension provider .
Refers to the YAML artifact published as part of the release process for providers ;
it usually includes Custom Resource Definitions (CRDs), Deployments (to run the controller manager), RBAC, etc.
In some cases, the same expression is used to refer to the instances of above components deployed in a management cluster.
See Provider repository
Refers to the location where the YAML for provider components are hosted; usually a provider repository hosts
many version of provider components, one for each released version.
An external component which is part of a system built on top of Cluster API that can handle requests for a specific Runtime Hook.
See Runtime SDK
Refers to a provider that implements one or more runtime extensions .
Runtime Extension provider’s interaction with Cluster API are based on the Open API spec for runtime hooks .
A single, well identified, extension point allowing applications built on top of Cluster API to hook into specific moments of the Cluster API Runtime , e.g. BeforeClusterUpgrade , TopologyMutationHook .
See Runtime SDK
A developer toolkit required to build Runtime Hooks and Runtime Extensions.
See Runtime SDK
Unless otherwise specified, this refers to horizontal scaling.
A control plane node where etcd is colocated with the Kubernetes API server, and
is running as a static pod.
The infrastructure that backs a Machine Resource , typically either a cloud instance, virtual machine, or physical host.
A field in the Cluster object spec that allows defining and managing the shape of the Cluster’s control plane and worker machines from a single point of control. The Cluster’s topology is based on a ClusterClass .
Sometimes it is also referred as a managed topology.
See ClusterClass
A Runtime Hook that allows external components to generate patches for customizing Kubernetes objects that are part of a Cluster topology .
See Topology Mutation
A cluster created by a ClusterAPI controller, which is not a bootstrap cluster, and is meant to be used by end-users, as opposed to by CAPI tooling.
A collection of templates that define a set of worker nodes in the cluster. A ClusterClass contains zero or more WorkerClass definitions.
See ClusterClass
The code in this repository is independent of any specific deployment environment.
Provider specific code is being developed in separate repositories, some of which
are also sponsored by SIG Cluster Lifecycle. Check provider’s documentation for
updated info about which API version they are supporting.
Following are the implementations managed by third-parties adopting the standard cluster-api and/or machine-api being developed here.
Name Port Number Description
metricsPort that exposes the metrics. This can be customized by setting the --metrics-bind-addr flag when starting the manager. The default is to only listen on localhost:8080 webhook9443Webhook server port. To disable this set --webhook-port flag to 0. health9440Port that exposes the health endpoint. CThis can be customized by setting the --health-addr flag when starting the manager. profilerExpose the pprof profiler. By default is not configured. Can set the --profiler-address flag. e.g. --profiler-address 6060
Note: external providers (e.g. infrastructure, bootstrap, or control-plane) might allocate ports differently, please refer to the respective documentation.
Please refer to our Kubernetes Community Code of Conduct
Read the following guide if you’re interested in contributing to cluster-api.
Contributors who are not used to working in the Kubernetes ecosystem should also take a look at the Kubernetes New Contributor Course.
We’d love to accept your patches! Before we can take them, we have to jump a couple of legal hurdles.
Please fill out either the individual or corporate Contributor License Agreement (CLA). More information about the CLA
and instructions for signing it can be found here .
NOTE
If you’re new to the project and want to help, but don’t know where to start, we have a semi-curated list of issues that
should not need deep knowledge of the system. Have a look and see if anything sounds
interesting .
Before starting to work on the issue, make sure that it doesn’t have a lifecycle/active label. If the issue has been assigned, reach out to the assignee.
Alternatively, read some docs on other controllers and try to write your own, file and fix any/all issues that
come up, including gaps in documentation!
If you’re a more experienced contributor, looking at unassigned issues in the next release milestone is a good way to find work that has been prioritized. For example, if the latest minor release is v1.0, the next release milestone is v1.1.
Help and contributions are very welcome in the form of code contributions but also in helping to moderate office hours, triaging issues, fixing/investigating flaky tests, being part of the release team , helping new contributors with their questions, reviewing proposals, etc.
⚠ The project does not follow Go Modules guidelines for compatibility requirements for 1.x semver releases.
Cluster API follows upstream Kubernetes semantic versioning. With the v1 release of our codebase, we guarantee the following:
These guarantees extend to all code exposed in our Go Module, including
types from dependencies in public APIs .
Types and functions not in public APIs are not considered part of the guarantee.
The test module, clusterctl, and experiments do not provide any backward compatible guarantees.
We generally do not accept PRs directly against release branches, while we might accept backports of fixes/changes already
merged into the main branch.
Any backport MUST not be breaking for either API or behavioral changes.
We generally allow backports of following changes to all supported branches:
Critical bugs fixes, security issue fixes, or fixes for bugs without easy workarounds.
Dependency bumps for CVE (usually limited to CVE resolution; backports of non-CVE related version bumps are considered exceptions to be evaluated case by case)
Cert-manager version bumps (to avoid having releases with cert-manager versions that are out of support, when possible)
Changes required to support new Kubernetes versions, when possible. See supported Kubernetes versions for more details.
Changes to use the latest Go patch version to build controller images.
Changes to bump the Go minor version used to build controller images, if the Go minor version of a supported branch goes out of support (e.g. to pick up bug and CVE fixes).
This has no impact on folks importing Cluster API as we won’t modify the version in go.mod and the version in the Makefile does not affect them.
We generally allow backports of following changes only to the latest supported branch:
Improvements to existing docs (the latest supported branch hosts the current version of the book)
Improvements to CI signal
Improvements to the test framework
While we recommend to target following type of changes to the next minor release, CAPI maintainers will also consider
exceptions for backport of following changes only to the latest supported branch:
Enhancements or additions to experimental Cluster API features, with the goal of allowing faster adoption and iteration;
Please note that stability of the branch will always be top priority while evaluating those PRs, and thus approval
requires /lgtm from at least two maintainers that, on top of checking that the backport is not introducing any breaking
change for either API or behavior, will evaluate if the impact of those backport is limited and well-scoped e.g.
by checking that those changes should not touch non-experimental code paths like utils and/or by applying other
considerations depending on the specific PR.
Like any other activity in the project, backporting a fix/change is a community-driven effort and requires that someone volunteers to own the task.
In most cases, the cherry-pick bot can (and should) be used to automate opening a cherry-pick PR.
We generally do not accept backports to Cluster API release branches that are out of support .
API versioning and guarantees are inspired by the Kubernetes deprecation policy
and API change guidelines .
We follow the API guidelines as much as possible adapting them if necessary and on a case-by-case basis to CustomResourceDefinition.
Any command line interface in Cluster API (e.g. clusterctl) share the same versioning schema of the codebase.
CLI guarantees are inspired by Kubernetes deprecation policy for CLI ,
however we allow breaking changes after 8 months or 2 releases (whichever is longer) from deprecation.
Cluster API has two types of branches: the main branch and
release-X branches.
The main branch is where development happens. All the latest and
greatest code, including breaking changes, happens on main.
The release-X branches contain stable, backwards compatible code. On every
major or minor release, a new branch is created. It is from these
branches that minor and patch releases are tagged. In some cases, it may
be necessary to open PRs for bugfixes directly against stable branches, but
this should generally not be the case.
Cluster API maintains the most recent release/releases for all supported API and contract versions. Support for this section refers to the ability to backport and release patch versions;
backport policy is defined above.
The API version is determined from the GroupVersion defined in the top-level api/ package.
The EOL date of each API Version is determined from the last release available once a new API version is published.
API Version Supported Until
v1beta1 TBD (current stable)
For the current stable API version (v1beta1) we support the two most recent minor releases; older minor releases are immediately unsupported when a new major/minor release is available.
For older API versions we only support the most recent minor release until the API version reaches EOL.
We will maintain test coverage for all supported minor releases and for one additional release for the current stable API version in case we have to do an emergency patch release.
For example, if v1.2 and v1.3 are currently supported, we will also maintain test coverage for v1.1 for one additional release cycle. When v1.4 is released, tests for v1.1 will be removed.
Minor Release API Version Supported Until
v1.7.x v1beta1 when v1.9.0 will be released v1.6.x v1beta1 when v1.8.0 will be released v1.5.x v1beta1 EOL since 2024-04-16 - v1.7.0 release date v1.4.x v1beta1 EOL since 2023-12-05 - v1.6.0 release date v1.3.x v1beta1 EOL since 2023-07-25 - v1.5.0 release date v1.2.x v1beta1 EOL since 2023-03-28 - v1.4.0 release date v1.1.x v1beta1 EOL since 2022-07-18 - v1.2.0 release date (*) v1.0.x v1beta1 EOL since 2022-02-02 - v1.1.0 release date (*) v0.4.x v1alpha4 EOL since 2022-04-06 - API version EOL v0.3.x v1alpha3 EOL since 2022-02-23 - API version EOL
(*) Previous support policy applies, older minor releases were immediately unsupported when a new major/minor release was available
Exceptions can be filed with maintainers and taken into consideration on a case-by-case basis.
Both v1alpha3 and v1alpha4 have been removed from Cluster API as of release 1.7.
For more details and latest information please see the following issue: Removing v1alpha3 & v1alpha4 apiVersions .
Note: Removal of a deprecated APIVersion in Kubernetes can cause issues with garbage collection by the kube-controller-manager
This means that some objects which rely on garbage collection for cleanup - e.g. MachineSets and their descendent objects, like Machines and InfrastructureMachines, may not be cleaned up properly if those
objects were created with an APIVersion which is no longer served.
To avoid these issues it’s advised to ensure a restart to the kube-controller-manager is done after upgrading to a version of Cluster API which drops support for an APIVersion - e.g. v1.5 and v1.6.
This can be accomplished with any Kubernetes control-plane rollout, including a Kubernetes version upgrade, or by manually stopping and restarting the kube-controller-manager.
If you haven’t already done so, sign a Contributor License Agreement (see details above).
If working on an issue, signal other contributors that you are actively working on it using /lifecycle active.
Fork the desired repo, develop and test your code changes.
Submit a pull request.
All code PR must be labeled with one of
⚠️ (:warning:, major or breaking changes)
✨ (:sparkles:, feature additions)
🐛 (:bug:, patch and bugfixes)
📖 (:book:, documentation or proposals)
🌱 (:seedling:, minor or other)
If your PR has multiple commits, you must squash them into a single commit before merging your PR.
Individual commits should not be tagged separately, but will generally be
assumed to match the PR. For instance, if you have a bugfix in with
a breaking change, it’s generally encouraged to submit the bugfix
separately, but if you must put them in one PR, mark the commit
separately.
All changes must be code reviewed. Coding conventions and standards are explained in the official developer
docs . Expect reviewers to request that you
avoid common go style mistakes in your PRs.
The documentation is published in form of a book at:
The source for the book is this folder
containing markdown files and we use mdBook to build it into a static
website.
After making changes locally you can run make serve-book which will build the HTML version
and start a web server, so you can preview if the changes render correctly at
http://localhost:3000; the preview auto-updates when changes are detected.
Note: you don’t need to have mdBook installed, make serve-book will ensure
appropriate binaries for mdBook and any used plugins are downloaded into
hack/tools/bin/ directory.
When submitting the PR remember to label it with the 📖 (:book:) icon.
Cluster API release process is described in this document .
The Cluster API Enhancement Proposal is the process this project uses to adopt new features, changes to the APIs, changes to contracts between components, or changes to CLI interfaces.
The template , and accepted proposals live under docs/proposals .
Proposals or requests for enhancements (RFEs) MUST be associated with an issue.
Issues can be placed on the roadmap during planning if there is one or more folks
that can dedicate time to writing a CAEP and/or implementing it after approval.
A proposal SHOULD be introduced and discussed during the weekly community meetings or on the
Kubernetes SIG Cluster Lifecycle mailing list .
A proposal in a Google Doc MUST turn into a Pull Request .
Proposals MUST be merged and in implementable state to be considered part of a major or minor release.
When you submit a change to the Cluster API repository as set of validation jobs is automatically executed by
prow and the results report is added to a comment at the end of your PR.
Some jobs run linters or unit test, and in case of failures, you can repeat the same operation locally using make test lint [etc..]
in order to investigate and potential issues. Prow logs usually provide hints about the make target you should use
(there might be more than one command that needs to be run).
End-to-end (E2E) jobs create real Kubernetes clusters by building Cluster API artifacts with the latest changes.
In case of E2E test failures, usually it’s required to access the “Artifacts” link on the top of the prow logs page to triage the problem.
The artifact folder contains:
A folder with the clusterctl local repository used for the test, where you can find components yaml and cluster templates.
A folder with logs for all the clusters created during the test. Following logs/info are available:
Controller logs (only if the cluster is a management cluster).
Dump of the Cluster API resources (only if the cluster is a management cluster).
Machine logs (only if the cluster is a workload cluster)
In case you want to run E2E test locally, please refer to the Testing guide. An overview over our e2e test jobs (and also all our other jobs) can be found in Jobs .
Parts of the following content have been adapted from https://google.github.io/eng-practices/review.
Any Kubernetes organization member can leave reviews and /lgtm a pull request.
Code reviews should generally look at:
Design : Is the code well-designed and consistent with the rest of the system?Functionality : Does the code behave as the author (or linked issue) intended? Is the way the code behaves good for its users?Complexity : Could the code be made simpler? Would another developer be able to easily understand and use this code when they come across it in the future?Tests : Does the code have correct and well-designed tests?Naming : Did the developer choose clear names for variable, types, methods, functions, etc.?Comments : Are the comments clear and useful? Do they explain why rather than what?Documentation : Did the developer also update relevant documentation?
See Code Review in Cluster API for a more focused list of review items.
Please see the Kubernetes community document on pull
requests for more information about the merge
process.
A PR is approved by one of the project maintainers and owners after reviews.
Approvals should be the very last action a maintainer takes on a pull request.
Open issues to report bugs, or discuss minor feature implementation.
Each new issue will be automatically labeled as needs-triage; after being triaged by the maintainers the label
will be removed and replaced by one of the following:
triage/accepted: Indicates an issue or PR is ready to be actively worked on.triage/duplicate: Indicates an issue is a duplicate of another open issue. triage/needs-information: Indicates an issue needs more information in order to work on it. triage/not-reproducible: Indicates an issue can not be reproduced as described. triage/unresolved: Indicates an issue that can not or will not be resolved.
For big feature, API and contract amendments, we follow the CAEP process as outlined below.
Proof of concepts, code experiments, or other initiatives can live under the exp folder or behind a feature gate.
Experiments SHOULD not modify any of the publicly exposed APIs (e.g. CRDs).
Experiments SHOULD not modify any existing CRD types outside the experimental API group(s).
Experiments SHOULD not modify any existing command line contracts.
Experiments MUST not cause any breaking changes to existing (non-experimental) Go APIs.
Experiments SHOULD introduce utility helpers in the go APIs for experiments that cross multiple components
and require support from bootstrap, control plane, or infrastructure providers.
Experiments follow a strict lifecycle: Alpha -> Beta prior to Graduation.
Alpha-stage experiments:
SHOULD not be enabled by default and any feature gates MUST be marked as ‘Alpha’
MUST be associated with a CAEP that is merged and in at least a provisional state
MAY be considered inactive and marked as deprecated if the following does not happen within the course of 1 minor release cycle:
Transition to Beta-stage
Active development towards progressing to Beta-stage
Either direct or downstream user evaluation
Any deprecated Alpha-stage experiment MAY be removed in the next minor release.
Beta-stage experiments:
SHOULD be enabled by default, and any feature gates MUST be marked as ‘Beta’
MUST be associated with a CAEP that is at least in the experimental state
MUST support conversions for any type changes
MUST remain backwards compatible unless updates are coinciding with a breaking Cluster API release
MAY be considered inactive and marked as deprecated if the following does not happen within the course of 1 minor release cycle:
Graduate
Active development towards Graduation
Either direct or downstream user consumption
Any deprecated Beta-stage experiment MAY be removed after being deprecated for an entire minor release.
Experiment Graduation MUST coincide with a breaking Cluster API release
Experiment Graduation checklist:
Breaking changes are generally allowed in the main branch, as this is the branch used to develop the next minor
release of Cluster API.
There may be times, however, when main is closed for breaking changes. This is likely to happen as we near the
release of a new minor version.
Breaking changes are not allowed in release branches, as these represent minor versions that have already been released.
These versions have consumers who expect the APIs, behaviors, etc. to remain stable during the lifetime of the patch
stream for the minor release.
Examples of breaking changes include:
Removing or renaming a field in a CRD
Removing or renaming a CRD
Removing or renaming an exported constant, variable, type, or function
Updating the version of critical libraries such as controller-runtime, client-go, apimachinery, etc.
Some version updates may be acceptable, for picking up bug fixes, but maintainers must exercise caution when
reviewing.
There may, at times, need to be exceptions where breaking changes are allowed in release branches. These are at the
discretion of the project’s maintainers, and must be carefully considered before merging. An example of an allowed
breaking change might be a fix for a behavioral bug that was released in an initial minor version (such as v0.3.0).
Cluster API follows the license policy of the CNCF . This sets limits on which
licenses dependencies and other artifacts use. For go dependencies only dependencies listed in the go.mod are considered dependencies. This is in line with how dependencies are reviewed in Kubernetes .
This project follows the Kubernetes API conventions . Minor modifications or additions to the conventions are listed below.
Status fields MUST be optional. Our controllers are patching selected fields instead of updating the entire status in every reconciliation.
If a field is required (for our controllers to work) and has a default value specified via OpenAPI schema, but we don’t want to force users to set the field, we have to mark the field as optional. Otherwise, the client-side kubectl OpenAPI schema validation will force the user to set it even though it would be defaulted on the server-side.
Optional fields have the following properties:
An optional field MUST be marked with +optional and include an omitempty JSON tag.
Fields SHOULD be pointers if there is a good reason for it, for example:
the nil and the zero values (by Go standards) have semantic differences.
Note: This doesn’t apply to map or slice types as they are assignable to nil.
the field is of a struct type, contains only fields with omitempty and you want
to prevent that it shows up as an empty object after marshalling (e.g. kubectl get)
When using ClusterClass, the semantic difference is important when you have a field in a template which will
have instance-specific different values in derived objects. Because in this case it’s possible to set the field to nil
in the template and then the value can be set in derived objects without being overwritten by the cluster topology controller.
Fields in root objects should be kept as scaffolded by kubebuilder, e.g.:
type Machine struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec MachineSpec `json:"spec,omitempty"`
Status MachineStatus `json:"status,omitempty"`
}
type MachineList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []Machine `json:"items"`
}
Top-level fields in status must always have the +optional annotation. If we want the field to be always visible even if it
has the zero value, it must not have the omitempty JSON tag, e.g.:
Replica counters like availableReplicas in the MachineDeployment
Flags expressing progress in the object lifecycle like infrastructureReady in Machine
All our CRD objects should have the following additionalPrinterColumns order (if the respective field exists in the CRD):
Namespace (added automatically)
Name (added automatically)
Cluster
Other fields
Replica-related fields
Phase
Age (mandatory field for all CRDs)
Version
Other fields for -o wide (fields with priority 1 are only shown with -o wide and not per default)
NOTE kubebuilder:printcolumn annotation on root objects. For examples, please see the ./api package.
Examples:
kubectl get kubeadmcontrolplane
NAMESPACE NAME INITIALIZED API SERVER AVAILABLE REPLICAS READY UPDATED UNAVAILABLE AGE VERSION
quick-start-d5ufye quick-start-ntysk0-control-plane true true 1 1 1 2m44s v1.23.3
kubectl get machinedeployment
NAMESPACE NAME CLUSTER REPLICAS READY UPDATED UNAVAILABLE PHASE AGE VERSION
quick-start-d5ufye quick-start-ntysk0-md-0 quick-start-ntysk0 1 1 1 ScalingUp 3m28s v1.23.3
To gain viewing permissions to google docs in this project, please join either the
kubernetes-dev or
kubernetes-sig-cluster-lifecycle google
group.
Anyone may comment on issues and submit reviews for pull requests. However, in order to be assigned an issue or pull
request, you must be a member of the Kubernetes SIGs GitHub organization.
If you are a Kubernetes GitHub organization member, you are eligible for membership in the Kubernetes SIGs GitHub
organization and can request membership by opening an
issue
against the kubernetes/org repo.
However, if you are a member of the related Kubernetes GitHub organizations but not of the Kubernetes org, you
will need explicit sponsorship for your membership request. You can read more about Kubernetes membership and
sponsorship here .
Cluster API maintainers can assign you an issue or pull request by leaving a /assign <your Github ID> comment on the
issue or pull request.
New contributors are welcomed to the community by existing members, helped with PR workflow, and directed to relevant documentation and communication channels.
We are also committed in helping people willing to do so in stepping up through the contributor ladder and this paragraph describes how we are trying to make this to happen.
As the project adoption increases and the codebase keeps growing, we’re trying to break down ownership into self-driven subareas of interest.
Requirements from the Kubernetes community membership guidelines apply for reviewers, maintainers and any member of these subareas.
Whenever you meet requisites for taking responsibilities in a subarea, the following procedure should be followed:
Submit a PR.
Propose at community meeting.
Get positive feedback and +1s in the PR and wait one week lazy consensus after agreement.
As of today there are following OWNERS files/Owner groups defining sub areas:
This document intents to provide an overview over our jobs running via Prow, GitHub actions and Google Cloud Build.
It also documents the cluster-api specific configuration in test-infra.
NOTE: To see which test jobs execute which tests or e2e tests, you can click on the links which lead to the respective test overviews in testgrid.
The dashboards for the ProwJobs can be found here: https://testgrid.k8s.io/sig-cluster-lifecycle-cluster-api
More details about ProwJob configurations can be found here: cluster-api-prowjob-gen.yaml
Prow Presubmits:
mandatory for merge, always run:
pull-cluster-api-build-main ./scripts/ci-build.sh
pull-cluster-api-verify-main ./scripts/ci-verify.sh
mandatory for merge, run if go code changes:
pull-cluster-api-test-main ./scripts/ci-test.sh
pull-cluster-api-e2e-blocking-main ./scripts/ci-e2e.sh
GINKGO_FOCUS: [PR-Blocking]
optional for merge, run if go code changes:
pull-cluster-api-apidiff-main ./scripts/ci-apidiff.sh
mandatory for merge, run if manually triggered:
pull-cluster-api-test-mink8s-main ./scripts/ci-test.sh
pull-cluster-api-e2e-mink8s-main ./scripts/ci-e2e.sh
GINKGO_SKIP: [Conformance]|[IPv6]
pull-cluster-api-e2e-dualstack-and-ipv6-main ./scripts/ci-e2e.sh
DOCKER_IN_DOCKER_IPV6_ENABLED: true
GINKGO_SKIP: [Conformance]
pull-cluster-api-e2e-main ./scripts/ci-e2e.sh
GINKGO_SKIP: [Conformance]|[IPv6]
pull-cluster-api-e2e-upgrade-* ./scripts/ci-e2e.sh
GINKGO_FOCUS: [Conformance] [K8s-Upgrade]
pull-cluster-api-e2e-conformance-main ./scripts/ci-e2e.sh
GINKGO_FOCUS: [Conformance] [K8s-Install]
pull-cluster-api-e2e-conformance-ci-latest-main ./scripts/ci-e2e.sh
GINKGO_FOCUS: [Conformance] [K8s-Install-ci-latest]
GitHub Presubmit Workflows:
PR golangci-lint: golangci/golangci-lint-action
Runs golangci-lint. Can be run locally via make lint.
PR verify: kubernetes-sigs/kubebuilder-release-tools verifier
Verifies the PR titles have a valid format, i.e. contains one of the valid icons.
Verifies the PR description is valid, i.e. is long enough.
PR check Markdown links (run when markdown files changed)
Checks markdown modified in PR for broken links.
PR dependabot (run on dependabot PRs)
Regenerates Go modules and code.
PR approve GH Workflows
Approves other GH workflows if the ok-to-test label is set.
GitHub Weekly Workflows:
Weekly check all Markdown links
Checks markdown across the repo for broken links.
Weekly image scan:
Scan all images for vulnerabilities. Can be run locally via make verify-container-images
Weekly release test:
Test the the release make target is working without errors.
Other Github workflows
release (runs when tags are pushed)
Creates a GitHub release with release notes for the tag.
Prow Postsubmits:
Prow Periodics:
periodic-cluster-api-test-main ./scripts/ci-test.sh
periodic-cluster-api-test-mink8s-main ./scripts/ci-test.sh
periodic-cluster-api-e2e-main ./scripts/ci-e2e.sh
GINKGO_SKIP: [Conformance]|[IPv6]
periodic-cluster-api-e2e-mink8s-main ./scripts/ci-e2e.sh
GINKGO_SKIP: [Conformance]|[IPv6]
periodic-cluster-api-e2e-dualstack-and-ipv6-main ./scripts/ci-e2e.sh
DOCKER_IN_DOCKER_IPV6_ENABLED: true
GINKGO_SKIP: [Conformance]
periodic-cluster-api-e2e-upgrade-* ./scripts/ci-e2e.sh
GINKGO_FOCUS: [Conformance] [K8s-Upgrade]
periodic-cluster-api-e2e-conformance-main ./scripts/ci-e2e.sh
GINKGO_FOCUS: [Conformance] [K8s-Install]
periodic-cluster-api-e2e-conformance-ci-latest-main ./scripts/ci-e2e.sh
GINKGO_FOCUS: [Conformance] [K8s-Install-ci-latest]
cluster-api-push-images-nightly Google Cloud Build: make release-staging-nightly
config/jobs/image-pushing/k8s-staging-cluster-api.yaml
Configures nightly and postsubmit jobs to push images and manifests.
config/jobs/kubernetes-sigs/cluster-api/
Configures Cluster API presubmit and periodic jobs.
config/testgrids/kubernetes/sig-cluster-lifecycle/config.yaml
Configures Cluster API testgrid dashboards.
config/prow/config.yaml
branch-protection and tide are configured to make the golangci-lint GitHub action mandatory for merge
config/prow/plugins.yaml
triggers: configures /ok-to-testapprove: disable auto-approval of PR authors, ignore GitHub reviews (/approve is explicitly required)milestone_applier: configures that merged PRs are automatically added to the correct milestone after mergerepo_milestone: configures cluster-api-maintainers as maintainersrequire_matching_label: configures needs-triageplugins: enables milestone, override and require-matching-label pluginsexternal_plugins: enables cherrypicker
label_sync/labels.yaml
Configures labels for the cluster-api repository.
To help newcomers to the project in implementing better PRs given the knowledge of what will be evaluated
during the review.
To help contributors in stepping up as a reviewer given a common understanding of what are the most relevant
things to be evaluated during the review.
IMPORTANT: improving and maintaining this document is a collaborative effort, so we are encouraging constructive
feedback and suggestions.
(from Code Review Developer Guide - Google )
“A code review is a process where someone other than the author(s) of a piece of code examines that code”
Within the context of cluster API the following design items should be carefully evaluated when reviewing a PR:
In CAPI most of the coding activities happen in controllers, and in order to make robust controllers,
we should strive for implementing reentrant code.
A reentrant code can be interrupted in the middle of its execution and then safely be called again
(”re-entered”); this concept, applied to Kubernetes controllers, means that a controller should be capable
of recovering from interruptions, observe the current state of things, and act accordingly. e.g.
We should not rely on flags/conditions from previous reconciliations since we are the controller
setting the conditions. Instead, we should detect the status of things through introspection at
every reconciliation and act accordingly.
It is acceptable to rely on status flags/conditions that we’ve previously set as part
of the current reconciliation.
It is acceptable to rely on status flags/conditions set by other controllers.
NOTE: An important use case for reentrancy is the move operation, where Cluster API objects gets moved
to a different management cluster and the controller running on the target cluster has to
rebuild the object status from scratch by observing the current state of the underlying infrastructure.
The API defines the main contract with the Cluster API users. As most of the APIs in Kubernetes,
each API version encompasses a set of guarantees to the user in terms of support window, stability,
and upgradability.
This makes API design a critical part of Cluster API development and usually:
Breaking/major API changes should go through the CAEP process and be strictly synchronized with the major
release cadence.
Non-breaking/minor API changes can go in minor releases; non-breaking changes are generally:
additive in nature
default to pre-existing behavior
optional as part of the API contract
On top of that, following API design considerations apply.
The Kubernetes API-machinery that is used for API serialization is build on top of three
technologies, most specifically:
JSON serialization
Open-API (for CRDs)
the go type system
One of the areas where the interaction between those technologies is critical in the handling of optional
values in the API; also the usage of nested slices might lead to problems in case of concurrent
edits of the object.
Cluster API leverages the owner ref chain of objects for several tasks, so it is crucial to evaluate the
impacts of any change that can impact this area. Above all:
The delete operation leverages on the owner ref chain for ensuring the cleanup of all the resources when
a cluster is deleted;
clusterctl move uses the owner ref chain for determining which object to move and the create/delete order.
The Cluster API rules define a set of rules/conventions the different provider authors should follow in
order to implement providers that can interact with the core Cluster API controllers, as
documented here and here .
By extension, the Cluster API contract includes all the util methods that Cluster API exposes for
making the development of providers simpler and consistent (e.g. everything under /util or in /test/framework);
documentation of the utility is available here .
The Cluster API contract is linked to the version of the API (e.g. v1beta1 Contract), and it is expected to
provide the same set of guarantees in terms of support window, stability, and upgradability.
This makes any change that can impact the Cluster API contract critical and usually:
Breaking/major contract changes should go through the CAEP process and be strictly synchronized with the major
release cadence.
Non-breaking/minor changes can go in minor releases; non-breaking changes are generally:
Additive in nature
Default to pre-existing behavior
Optional as part of the API contract
While developing controllers in Cluster API a key requirement is to add logging to observe the system and
to help troubleshooting issues.
Testing plays a crucial role in ensuring the long term maintainability of the project.
In Cluster API we are committed to have a good test coverage and also to have a nice and consistent style in implementing
tests. For more information see testing Cluster API .
The Cluster API team maintains branches for v1.x (v1beta1) . For more details see Support and guarantees .
Releases include these components:
Core Provider
Kubeadm Bootstrap Provider
Kubeadm Control Plane Provider
clusterctl client
All Infrastructure Providers are maintained by independent teams. Other Bootstrap and Control Plane Providers are also maintained by independent teams. For more information about their version support, see below .
A Cluster API minor release supports (when it’s initially created):
4 Kubernetes minor releases for the management cluster (N - N-3)
6 Kubernetes minor releases for the workload cluster (N - N-5)
When a new Kubernetes minor release is available, we will try to support it in an upcoming Cluster API patch release
(although only in the latest supported Cluster API minor release). See Cluster API release cycle
and release calendars for more details.
For example, Cluster API v1.5.0 would support the following Kubernetes versions:
v1.24.x to v1.27.x for the management cluster
v1.22.x to v1.27.x for the workload cluster
When Kubernetes 1.28 is released, it will be supported in v1.5.x (but not in v1.4.x)
Support in this context means that we:
maintain corresponding code paths
have test coverage
accept bug fixes
Important! if the changes in Cluster API required to support a new Kubernetes release are too invasive, we won’t backport
it to older releases and users have to wait for the next Cluster API minor release.
Important! This is not a replacement/alternative for upstream Kubernetes support policies!
Support for versions of Kubernetes which itself are out of support is limited to “Cluster API can start a Cluster with this Kubernetes version”
and “Cluster API can upgrade to the next Kubernetes version”; it does not include any extended support to Kubernetes itself.
Whenever a new Cluster API release is cut, we will document the Kubernetes version compatibility matrix the release
has been tested with. Summaries of Kubernetes versions supported by each component are additionally maintained in
the tables below.
On a final comment, let’s praise all the contributors keeping care of such a wide support matrix.
If someone is looking for opportunities to help with the project, this is definitely an area where additional hands
and eyes will be more than welcome and greatly beneficial to the entire community.
See the following section to understand how cluster topology affects version support.
The Core Provider, Kubeadm Bootstrap Provider, and Kubeadm Control Plane Provider run on the Management Cluster, and clusterctl talks to that cluster’s API server.
In some cases, the Management Cluster is separate from the Workload Clusters. The Kubernetes version of the Management and Workload Clusters are allowed to be different.
Management Clusters and Workload Clusters can be upgraded independently and in any order, however, if you are additionally moving from
v1alpha3 (v0.3.x) to v1beta1 (v1.x) as part of the upgrade rollout, the management cluster will need to be upgraded to at least v1.20.x,
prior to upgrading any workload cluster using Cluster API v1beta1 (v1.x)
These diagrams show the relationships between components in a Cluster API release (yellow), and other components (white).
v1.5 (v1beta1) (EOL) v1.6 (v1beta1) v1.7 (v1beta1)
Kubernetes v1.22 ✓ (only workload) Kubernetes v1.23* ✓ (only workload) ✓ (only workload) Kubernetes v1.24 ✓ ✓ (only workload) ✓ (only workload) Kubernetes v1.25 ✓ ✓ ✓ (only workload) Kubernetes v1.26 ✓ ✓ ✓ Kubernetes v1.27 ✓ ✓ ✓ Kubernetes v1.28 ✓ >= v1.5.1 ✓ ✓ Kubernetes v1.29 ✓ >= v1.6.1 ✓ Kubernetes v1.30 ✓ >= v1.7.1
* There is an issue with CRDs in Kubernetes v1.23.{0-2}. ClusterClass with patches is affected by that (for more details please see this issue ). Therefore we recommend to use Kubernetes v1.23.3+ with ClusterClass.
Previous Kubernetes minor versions are not affected.
The Core Provider also talks to API server of every Workload Cluster. Therefore, the Workload Cluster’s Kubernetes version must also be compatible.
v1.5 (v1beta1) (EOL) v1.6 (v1beta1) v1.7 (v1beta1)
Kubernetes v1.22 + kubeadm/v1beta3 ✓ (only workload) Kubernetes v1.23 + kubeadm/v1beta3 ✓ (only workload) ✓ (only workload) Kubernetes v1.24 + kubeadm/v1beta3 ✓ ✓ (only workload) ✓ (only workload) Kubernetes v1.25 + kubeadm/v1beta3 ✓ ✓ ✓ (only workload) Kubernetes v1.26 + kubeadm/v1beta3 ✓ ✓ ✓ Kubernetes v1.27 + kubeadm/v1beta3 ✓ ✓ ✓ Kubernetes v1.28 + kubeadm/v1beta3 ✓ >= v1.5.1 ✓ ✓ Kubernetes v1.29 + kubeadm/v1beta3 ✓ >= v1.6.1 ✓ Kubernetes v1.30 + kubeadm/v1beta3 ✓ >= v1.7.1
The Kubeadm Bootstrap Provider generates kubeadm configuration using the API version recommended for the target Kubernetes version.
v1.5 (v1beta1) (EOL) v1.6 (v1beta1) v1.7 (v1beta1)
Kubernetes v1.22 + etcd/v3 ✓ (only workload) Kubernetes v1.23 + etcd/v3 ✓ (only workload) ✓ (only workload) Kubernetes v1.24 + etcd/v3 ✓ ✓ (only workload) ✓ (only workload) Kubernetes v1.25 + etcd/v3 ✓ ✓ ✓ (only workload) Kubernetes v1.26 + etcd/v3 ✓ ✓ ✓ Kubernetes v1.27 + etcd/v3 ✓ ✓ ✓ Kubernetes v1.28 + etcd/v3 ✓ >= v1.5.1 ✓ ✓ Kubernetes v1.29 + etcd/v3 ✓ >= v1.6.1 ✓ Kubernetes v1.30 + etcd/v3 ✓ >= v1.7.1
The Kubeadm Control Plane Provider talks to the API server and etcd members of every Workload Cluster whose control plane it owns. It uses the etcd v3 API.
The Kubeadm Control Plane requires the Kubeadm Bootstrap Provider.
* Newer versions of CoreDNS may not be compatible as an upgrade target for clusters managed with Cluster API. Kubernetes versions marked on the table are supported as an upgrade target only if CoreDNS is not upgraded to the latest version supported by the respective Kubernetes version. The versions supported are represented in the below table.
CAPI Version Max CoreDNS Version for Upgrade
v1.5 (v1beta1) v1.10.1 >= v1.5.1 (v1beta1) v1.11.1 v1.6 (v1beta1) v1.11.1 v1.7 (v1beta1) v1.11.1 >= v1.7.9 (v1beta1) v1.11.3
1.29 :
In-tree cloud providers are now switched off by default. Please use DisableCloudProviders and DisableKubeletCloudCredentialProvider feature flags if you still need this functionality. (https://github.com/kubernetes/kubernetes/pull/117503)
1.24 :
Kubeadm Bootstrap Provider:
* kubeadm now sets both the node-role.kubernetes.io/control-plane and node-role.kubernetes.io/master taints on control plane nodes.
* kubeadm now only sets the node-role.kubernetes.io/control-plane label on control plane nodes (the node-role.kubernetes.io/master label is not set anymore).
Kubeadm Bootstrap Provider and Kubeadm Control Plane Provider
* criSocket without a scheme prefix has been deprecated in the kubelet since a while. kubeadm now shows a warning if no scheme is present and eventually the support for criSocket‘s without prefix will be dropped. Please adjust the criSocket accordingly (e.g. unix:///var/run/containerd/containerd.sock) if you are configuring the criSocket in CABPK or KCP resources.
It is strongly recommended to always use the latest version of clusterctl , in order to get all the fixes/latest changes.
In case of upgrades, clusterctl should be upgraded first and then used to upgrade all the other components.
In general, if a Provider version M says it is compatible with Cluster API version N, then version M must be compatible with a subset of the Kubernetes versions supported by Cluster API version N.
To understand the version compatibility of a specific provider, please see its documentation. This book includes a list of independent providers
Supported Labels:
Label Note
cluster.x-k8s.io/cluster-name It is set on machines linked to a cluster and external objects(bootstrap and infrastructure providers). topology.cluster.x-k8s.io/owned It is set on all the object which are managed as part of a ClusterTopology. topology.cluster.x-k8s.io/deployment-name It is set on the generated MachineDeployment objects to track the name of the MachineDeployment topology it represents. cluster.x-k8s.io/provider It is set on components in the provider manifest. The label allows one to easily identify all the components belonging to a provider. The clusterctl tool uses this label for implementing provider’s lifecycle operations. cluster.x-k8s.io/watch-filter It can be applied to any Cluster API object. Controllers which allow for selective reconciliation may check this label and proceed with reconciliation of the object only if this label and a configured value is present. cluster.x-k8s.io/interruptible It is used to mark the nodes that run on interruptible instances. cluster.x-k8s.io/control-plane It is set on machines or related objects that are part of a control plane. cluster.x-k8s.io/set-name It is set on machines if they’re controlled by MachineSet. The value of this label may be a hash if the MachineSet name is longer than 63 characters. cluster.x-k8s.io/control-plane-name It is set on machines if they’re controlled by a control plane. The value of this label may be a hash if the control plane name is longer than 63 characters. cluster.x-k8s.io/deployment-name It is set on machines if they’re controlled by a MachineDeployment. cluster.x-k8s.io/pool-name It is set on machines if they’re controlled by a MachinePool. machine-template-hash It is applied to Machines in a MachineDeployment containing the hash of the template.
Supported Annotations:
Annotation Note
clusterctl.cluster.x-k8s.io/skip-crd-name-preflight-check Can be placed on provider CRDs, so that clusterctl doesn’t emit an error if the CRD doesn’t comply with Cluster APIs naming scheme. Only CRDs that are referenced by core Cluster API CRDs have to comply with the naming scheme. clusterctl.cluster.x-k8s.io/delete-for-move DeleteForMoveAnnotation will be set to objects that are going to be deleted from the source cluster after being moved to the target cluster during the clusterctl move operation. It will help any validation webhook to take decision based on it. clusterctl.cluster.x-k8s.io/block-move BlockMoveAnnotation prevents the cluster move operation from starting if it is defined on at least one of the objects in scope. Provider controllers are expected to set the annotation on resources that cannot be instantaneously paused and remove the annotation when the resource has been actually paused. unsafe.topology.cluster.x-k8s.io/disable-update-class-name-check It can be used to disable the webhook check on update that disallows a pre-existing Cluster to be populated with Topology information and Class. unsafe.topology.cluster.x-k8s.io/disable-update-version-check It can be used to disable the webhook checks on update that disallows updating the .topology.spec.version on certain conditions. cluster.x-k8s.io/cluster-name It is set on nodes identifying the name of the cluster the node belongs to. cluster.x-k8s.io/cluster-namespace It is set on nodes identifying the namespace of the cluster the node belongs to. cluster.x-k8s.io/machine It is set on nodes identifying the machine the node belongs to. cluster.x-k8s.io/owner-kind It is set on nodes identifying the owner kind. cluster.x-k8s.io/owner-name It is set on nodes identifying the owner name. cluster.x-k8s.io/paused It can be applied to any Cluster API object to prevent a controller from processing a resource. Controllers working with Cluster API objects must check the existence of this annotation on the reconciled object. cluster.x-k8s.io/disable-machine-create It can be used to signal a MachineSet to stop creating new machines. It is utilized in the OnDelete MachineDeploymentStrategy to allow the MachineDeployment controller to scale down older MachineSets when Machines are deleted and add the new replicas to the latest MachineSet. cluster.x-k8s.io/delete-machine It marks control plane and worker nodes that will be given priority for deletion when KCP or a MachineSet scales down. It is given top priority on all delete policies. cluster.x-k8s.io/cloned-from-name It is the infrastructure machine annotation that stores the name of the infrastructure template resource that was cloned for the machine. This annotation is set only during cloning a template. Older/adopted machines will not have this annotation. cluster.x-k8s.io/cloned-from-groupkind It is the infrastructure machine annotation that stores the group-kind of the infrastructure template resource that was cloned for the machine. This annotation is set only during cloning a template. Older/adopted machines will not have this annotation. cluster.x-k8s.io/skip-remediation It is used to mark the machines that should not be considered for remediation by MachineHealthCheck reconciler. cluster.x-k8s.io/remediate-machine It can be applied to a machine to manually mark it for remediation by MachineHealthCheck reconciler. cluster.x-k8s.io/managed-by It can be applied to InfraCluster resources to signify that some external system is managing the cluster infrastructure. Provider InfraCluster controllers will ignore resources with this annotation. An external controller must fulfill the contract of the InfraCluster resource. External infrastructure providers should ensure that the annotation, once set, cannot be removed. cluster.x-k8s.io/replicas-managed-by It can be applied to MachinePool resources to signify that some external system is managing infrastructure scaling for that pool. See the MachinePool documentation for more details. cluster.x-k8s.io/skip-machineset-preflight-checks It can be applied on MachineDeployment and MachineSet resources to specify a comma-separated list of preflight checks that should be skipped during MachineSet reconciliation. Supported preflight checks are: All, KubeadmVersionSkew, KubernetesVersionSkew, ControlPlaneIsStable. topology.cluster.x-k8s.io/defer-upgrade It can be used to defer the Kubernetes upgrade of a single MachineDeployment topology. If the annotation is set on a MachineDeployment topology in Cluster.spec.topology.workers, the Kubernetes upgrade for this MachineDeployment topology is deferred. It doesn’t affect other MachineDeployment topologies. topology.cluster.x-k8s.io/dry-run It is an annotation that gets set on objects by the topology controller only during a server side dry run apply operation. It is used for validating update webhooks for objects which get updated by template rotation (e.g. InfrastructureMachineTemplate). When the annotation is set and the admission request is a dry run, the webhook should deny validation due to immutability. By that the request will succeed (without any changes to the actual object because it is a dry run) and the topology controller will receive the resulting object. topology.cluster.x-k8s.io/hold-upgrade-sequence It can be used to hold the entire MachineDeployment upgrade sequence. If the annotation is set on a MachineDeployment topology in Cluster.spec.topology.workers, the Kubernetes upgrade for this MachineDeployment topology and all subsequent ones is deferred. topology.cluster.x-k8s.io/upgrade-concurrency It can be used to configure the maximum concurrency while upgrading MachineDeployments of a classy Cluster. It is set as a top level annotation on the Cluster object. The value should be >= 1. If unspecified the upgrade concurrency will default to 1. machine.cluster.x-k8s.io/certificates-expiry It captures the expiry date of the machine certificates in RFC3339 format. It is used to trigger rollout of control plane machines before certificates expire. It can be set on BootstrapConfig and Machine objects. The value set on Machine object takes precedence. The annotation is only used by control plane machines. machine.cluster.x-k8s.io/exclude-node-draining It explicitly skips node draining if set. machine.cluster.x-k8s.io/exclude-wait-for-node-volume-detach It explicitly skips the waiting for node volume detaching if set. pre-drain.delete.hook.machine.cluster.x-k8s.io It specifies the prefix we search each annotation for during the pre-drain.delete lifecycle hook to pause reconciliation of deletion. These hooks will prevent removal of draining the associated node until all are removed. pre-terminate.delete.hook.machine.cluster.x-k8s.io It specifies the prefix we search each annotation for during the pre-terminate.delete lifecycle hook to pause reconciliation of deletion. These hooks will prevent removal of an instance from an infrastructure provider until all are removed. machinedeployment.clusters.x-k8s.io/revision It is the revision annotation of a machine deployment’s machine sets which records its rollout sequence. machinedeployment.clusters.x-k8s.io/revision-history It maintains the history of all old revisions that a machine set has served for a machine deployment. machinedeployment.clusters.x-k8s.io/desired-replicas It is the desired replicas for a machine deployment recorded as an annotation in its machine sets. Helps in separating scaling events from the rollout process and for determining if the new machine set for a deployment is really saturated. machinedeployment.clusters.x-k8s.io/max-replicas It is the maximum replicas a deployment can have at a given point, which is machinedeployment.spec.replicas + maxSurge. Used by the underlying machine sets to estimate their proportions in case the deployment has surge replicas. controlplane.cluster.x-k8s.io/skip-coredns It explicitly skips reconciling CoreDNS if set. controlplane.cluster.x-k8s.io/skip-kube-proxy It explicitly skips reconciling kube-proxy if set. controlplane.cluster.x-k8s.io/kubeadm-cluster-configuration It is a machine annotation that stores the json-marshalled string of KCP ClusterConfiguration. This annotation is used to detect any changes in ClusterConfiguration and trigger machine rollout in KCP. controlplane.cluster.x-k8s.io/remediation-in-progress It is a KCP annotation that tracks that the system is in between having deleted an unhealthy machine and recreating its replacement. controlplane.cluster.x-k8s.io/remediation-for It is a machine annotation that links a new machine to the unhealthy machine it is replacing.
Cluster API uses Kubernetes owner references to track relationships between objects. These references are used for Kubernetes garbage collection, which is the basis of Cluster deletion in CAPI. They are also used places where the ownership hierarchy is important, for example when using clusterctl move.
CAPI uses owner references in an opinionated way. The following guidelines should be considered:
Objects should always be created with an owner reference to prevent leaking objects. Initial ownerReferences can be replaced later where another object is a more appropriate owner.
Owner references should be re-reconciled if they are lost for an object. This is required as some tools - e.g. velero - may delete owner references on objects.
Owner references should be kept to the most recent apiVersion.
This ensures garbage collection still works after an old apiVersion is no longer served.
Owner references should not be added unless required.
Multiple owner references on a single object should be exceptional.
The below tables map out the a reference for ownership relationships for the objects in a Cluster API cluster. The tables are identical for classy and non-classy clusters.
Providers may implement their own ownership relationships which may or may not map directly to the below tables.
These owner references are almost all tested in an end-to-end test . Lack of testing is noted where this is not the case. CAPI Providers can take advantage of the e2e test framework to ensure their owner references are predictable, documented and stable.
Kubernetes core types
type Owner Controller Note
Secret KubeadmControlPlane yes For cluster certificates Secret KubeadmConfig yes For bootstrap secrets Secret ClusterResourceSet no When referenced by CRS. Not tested in e2e. ConfigMap ClusterResourceSet no When referenced by CRS
type Owner Controller Note
ExtensionConfig None ClusterClass None Cluster None MachineDeployments Cluster no MachineSet MachineDeployment yes Machine MachineSet yes When created by MachineSet Machine KubeadmControlPlane yes When created by KCP MachineHealthChecks Cluster no
type Owner Controller Note
ClusterResourcesSet None ClusterResourcesSetBinding ClusterResourceSet no May have many CRS owners MachinePool Cluster no
type Owner Controller Note
KubeadmControlPlane Cluster yes KubeadmControlPlaneTemplate ClusterClass no
type Owner Controller Note
KubeadmConfig Machine yes When created for Machine KubeadmConfig MachinePool yes When created for MachinePool KubeadmConfigTemplate Cluster no When referenced in MachineDeployment spec KubeadmConfigTemplate ClusterClass no When referenced in ClusterClass
type Owner Controller Note
InfrastructureMachine Machine yes InfrastructureMachineTemplate Cluster no When created by cluster topology controller InfrastructureMachineTemplate ClusterClass no When referenced in a ClusterClass InfrastructureCluster Cluster yes InfrastructureClusterTemplate ClusterClass no InfrastructureMachinePool MachinePool yes